Wolfram Function Repository
Instant-use add-on functions for the Wolfram Language
Function Repository Resource:
Generate a random tabular dataset
ResourceFunction["RandomTabularDataset"][{m,n}] generates a random tabular dataset with m rows and n columns. | |
ResourceFunction["RandomTabularDataset"][m] generates a random tabular dataset with m rows and a random number of columns. | |
ResourceFunction["RandomTabularDataset"][] generates a random tabular dataset with a random number of rows and columns. |
| "ColumnNamesGenerator" | Automatic | generator of column names |
| "Form" | "Wide" | the form of the generated dataset (long or wide) |
| "Generators" | Automatic | generators for the values in each column |
| "MaxNumberOfValues" | Automatic | max number of non-missing values |
| "MinNumberOfValues" | Automatic | min number of non-missing values |
| "RowKeys" | False | should the rows have keys or not |
| "PointwiseGeneration" | False | should the generators be applied in pointwise or vectorwise manner |
Generate a random tabular dataset:
| In[1]:= |
|
| Out[2]= |
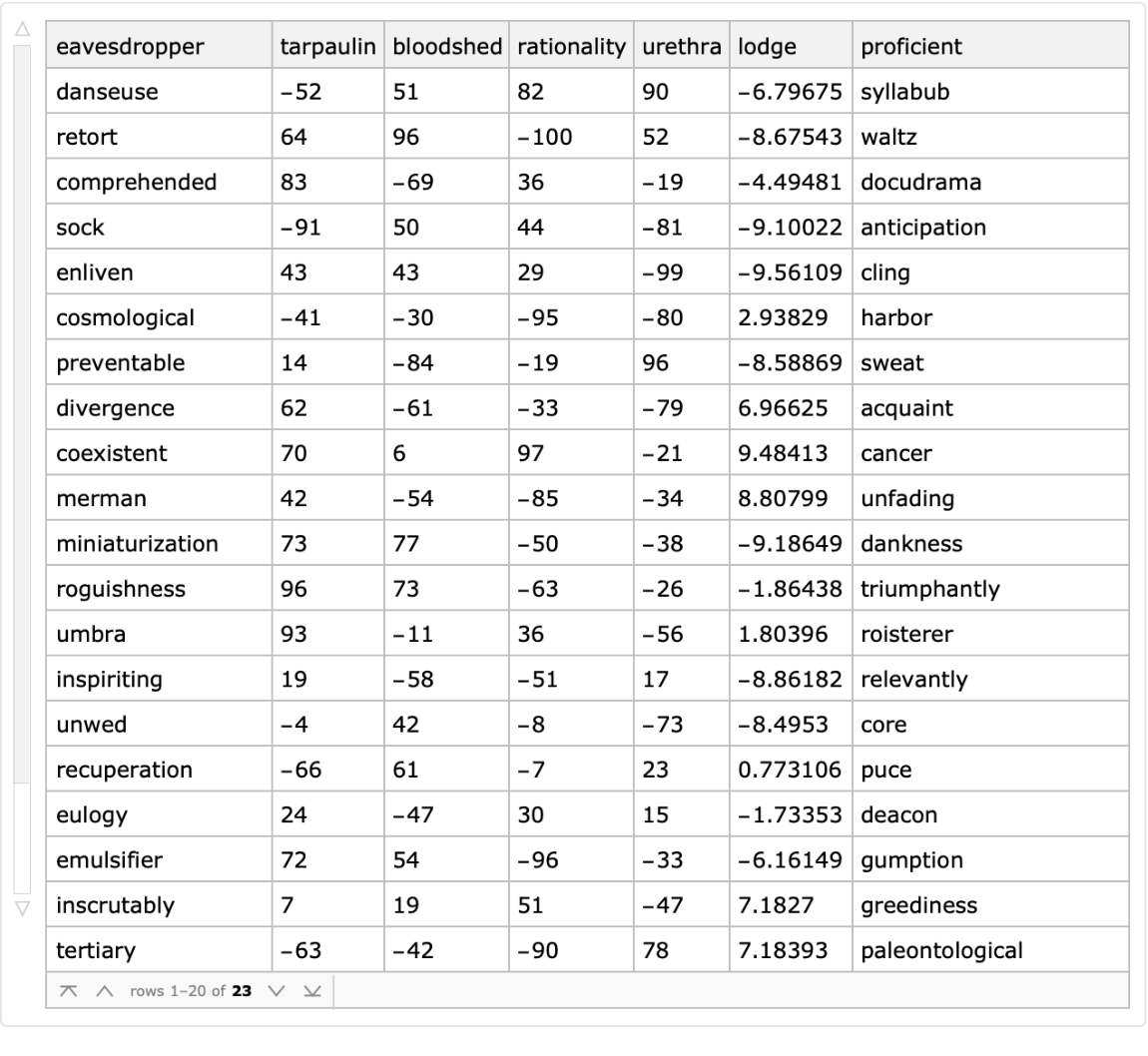
|
Generate a random tabular dataset with specified number of rows:
| In[3]:= |
|
| Out[4]= |
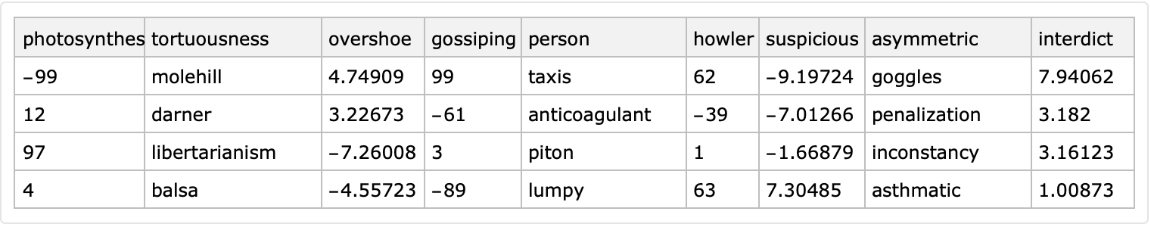
|
Generate a random tabular dataset with specified random value generators for certain columns:
| In[5]:= |
![SeedRandom[4];
ResourceFunction["RandomTabularDataset"][{5, Automatic}, "Generators" -> <|1 -> NormalDistribution[100, 3], 3 -> RandomColor|>]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/5f14998bea637211.png)
|
| Out[6]= |
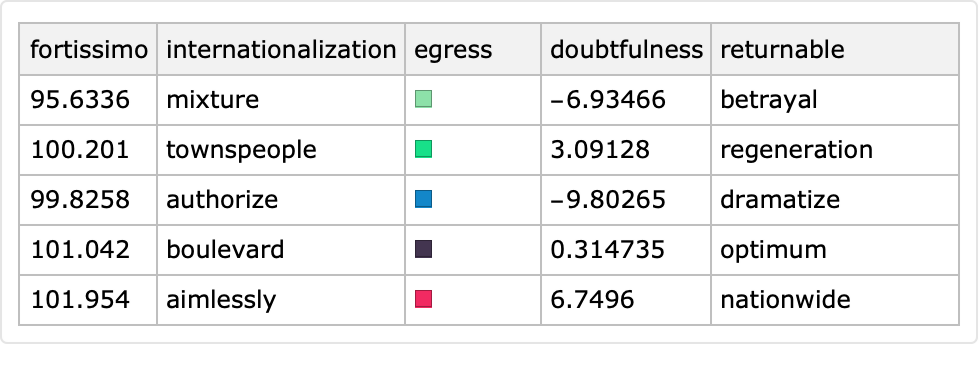
|
The generated dataset can be produced in long form or wide form and can have row keys. Here is a wide form dataset with row keys:
| In[7]:= |
|
| Out[8]= |
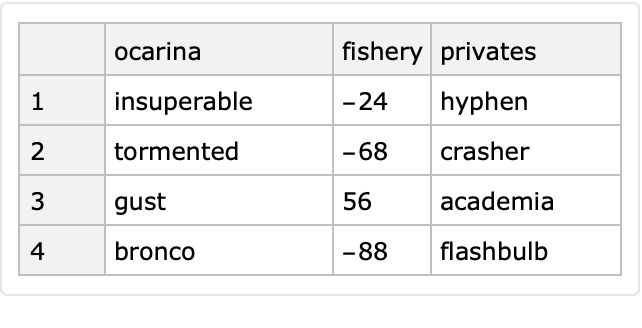
|
Here is the corresponding long form with row keys:
| In[9]:= |
|
| Out[10]= |
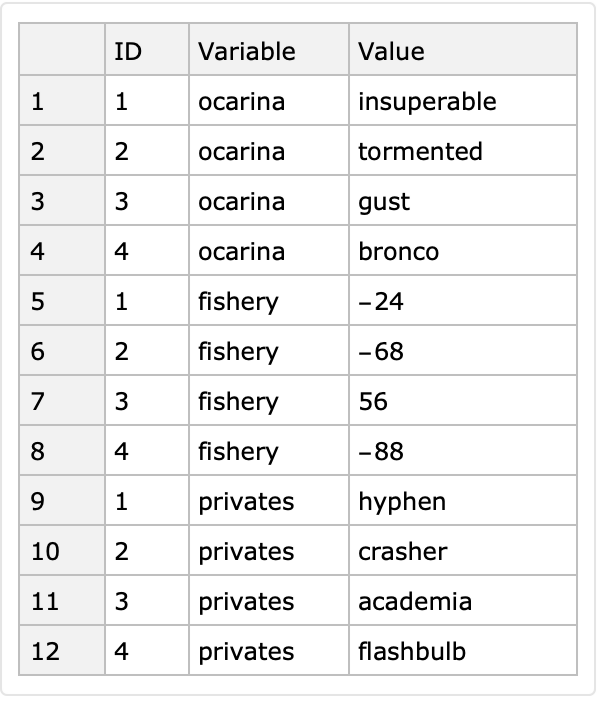
|
Generate a random tabular dataset with specified column names:
| In[11]:= |
|
| Out[12]= |
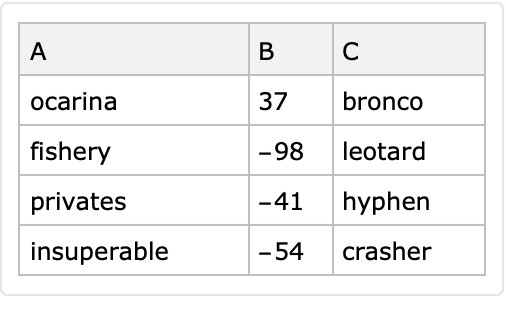
|
Using Identity or symbols without down values to specify the column name generation or column value generation gives insight about how the random generator functions are called. Here is an example with "pointwise" generators:
| In[13]:= |
![Clear[H, V];
ResourceFunction["RandomTabularDataset"][{4, 5}, "ColumnNamesGenerator" -> (ToString@*H), "Generators" -> V, "PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/66f9d8486335b22f.png)
|
| Out[14]= |
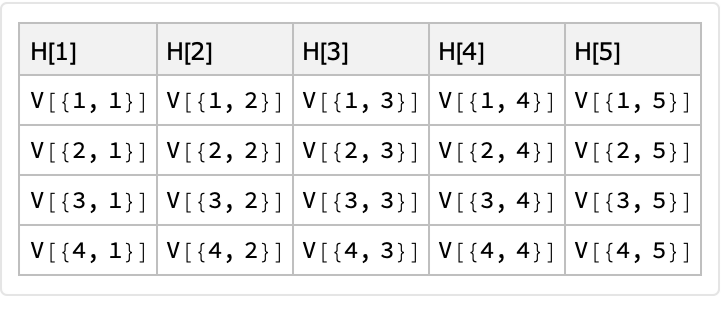
|
Here is an example with "vector-wise" generators:
| In[15]:= |
![Clear[H, V];
ResourceFunction["RandomTabularDataset"][{4, 5}, "ColumnNamesGenerator" -> (ToString@*H /@ #2 &), "Generators" -> Table[V /@ #2 &, {5}], "PointwiseGeneration" -> False]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/154355bae7dd1b60.png)
|
| Out[16]= |
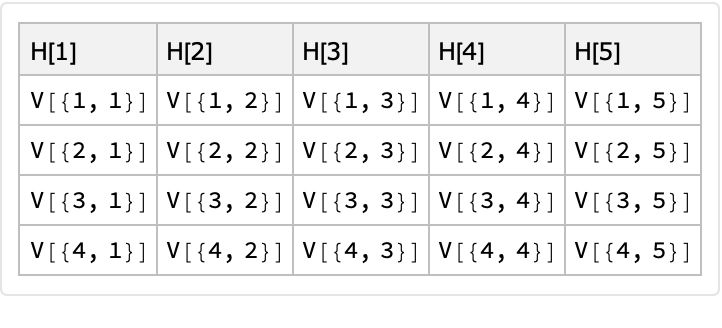
|
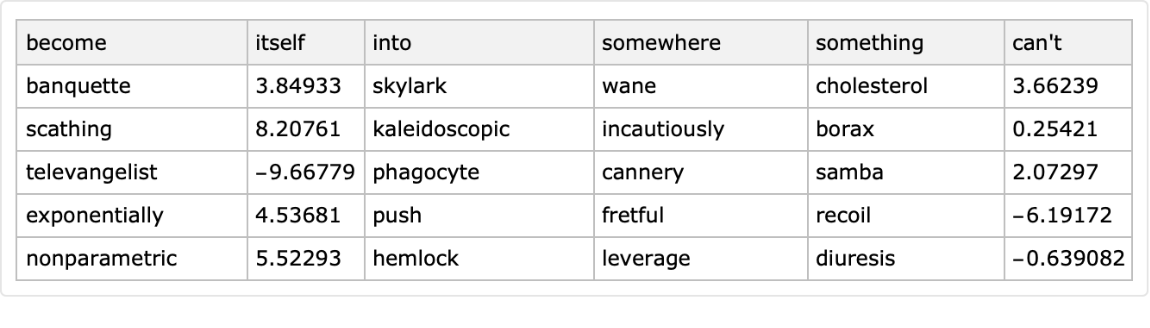
The option "ColumnNamesGenerator" specifies a function that generates the column names:
| In[17]:= |
![SeedRandom[116];
ResourceFunction["RandomTabularDataset"][{5, 6}, "ColumnNamesGenerator" -> (RandomWord["Stopwords", #] &)]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/5025608965da8f23.png)
|
| Out[18]= |
|
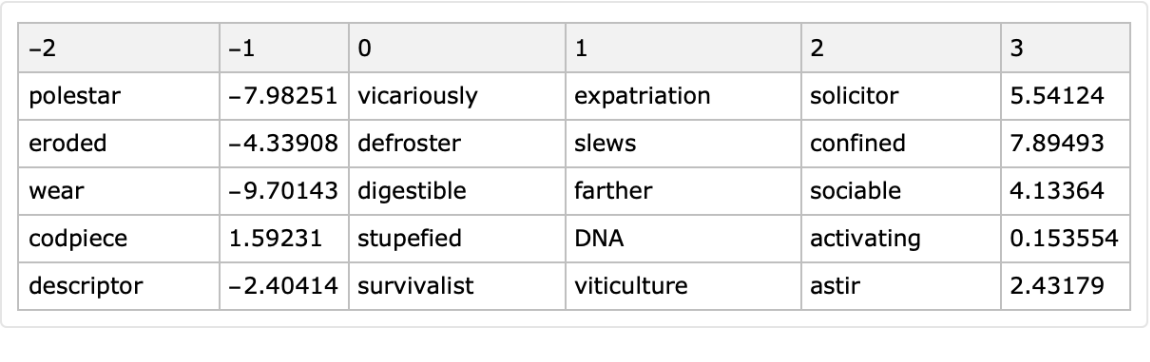
The column names generator function application adheres to the value given to the option "PointwiseGeneration". Here is an example with the pointwise generator (ToString[k++]&):
| In[19]:= |
![SeedRandom[116];
k = -2;
ResourceFunction["RandomTabularDataset"][{5, 6}, "ColumnNamesGenerator" -> (ToString[k++] &), "PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/59ad4c7367e39af3.png)
|
| Out[21]= |
|
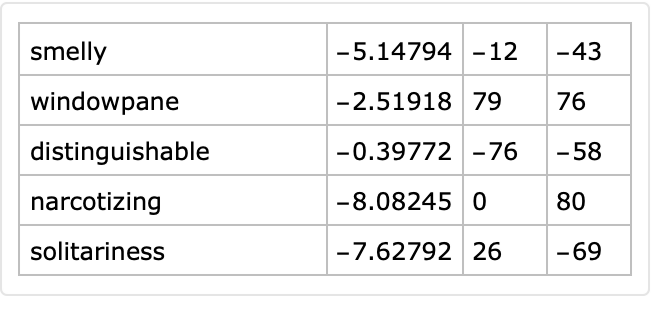
If the column names generator is None, the dataset will not have column names:
| In[22]:= |
|
| Out[23]= |
|
Generate random datasets for which column i has the name F[i], using pointwise generation:
| In[24]:= |
![SeedRandom[11];
ResourceFunction["RandomTabularDataset"][{3, 5}, "ColumnNamesGenerator" -> (ToString@*F), "PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/774abfbb289ecc87.png)
|
| Out[25]= |

|
Here is the vectorwise generation:
| In[26]:= |
![SeedRandom[11];
ResourceFunction["RandomTabularDataset"][{3, 5}, "ColumnNamesGenerator" -> (ToString@*F /@ #2 &), "PointwiseGeneration" -> False]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/64bfac8ebf8b19db.png)
|
| Out[27]= |

|
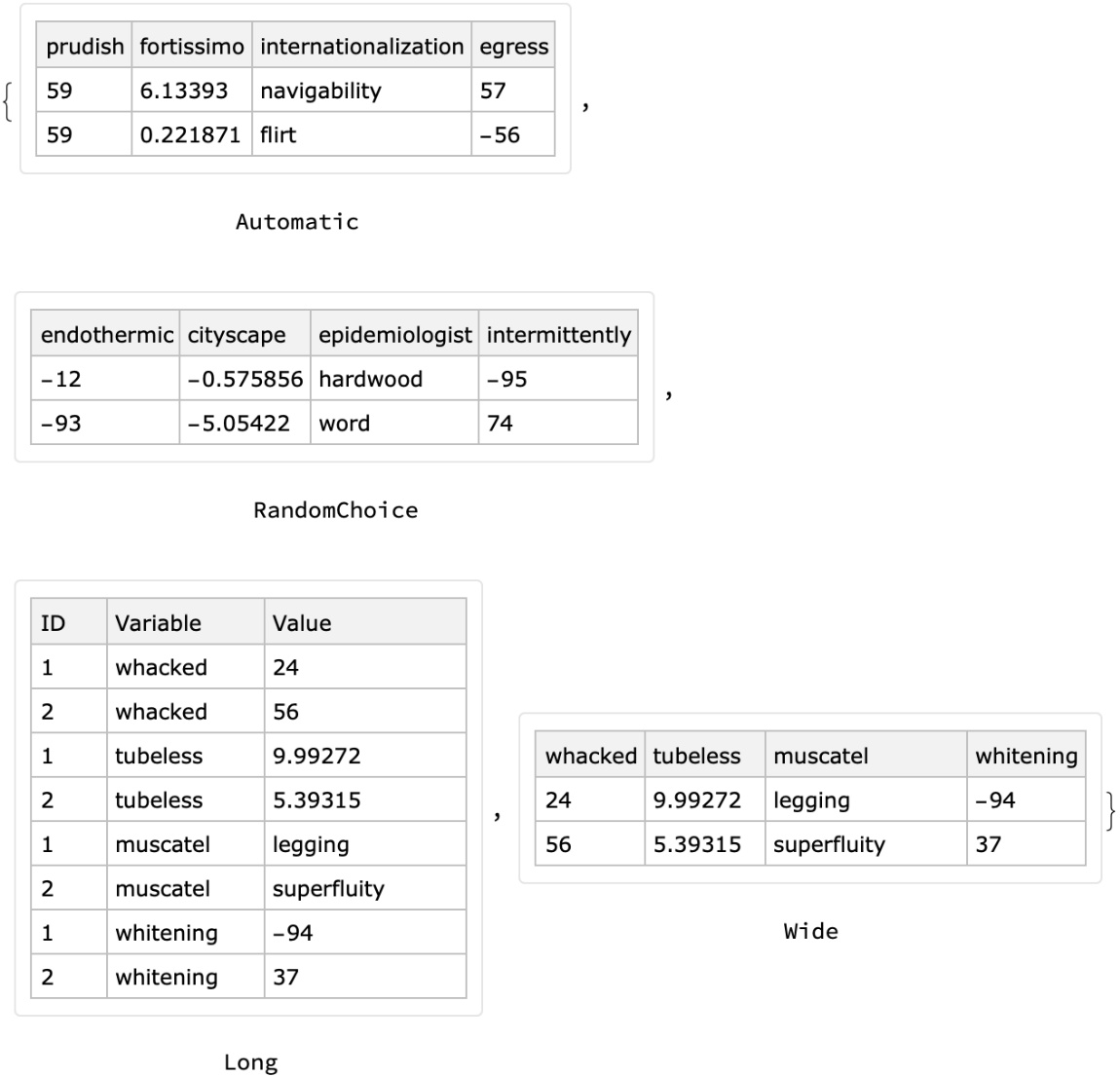
The option "Form" specifies the form (format) of the generated dataset; it takes the values Automatic, RandomChoice, "Long" or "Wide":
| In[28]:= |
![Table[Labeled[
BlockRandom[
ResourceFunction["RandomTabularDataset"][{2, 4}, "Form" -> f], RandomSeeding -> 4], f], {f, {Automatic, RandomChoice, "Long", "Wide"}}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/7090289f38abd63a.png)
|
| Out[28]= |
|
If the option "Generators" is given the value Automatic, then the column value generators are derived through a random choice of functions that produce random reals, random integers and random words. The following two examples show the generated datasets have columns with corresponding types:
| In[29]:= |
![SeedRandom[32];
ncols = 7;
lsColNames = Take[CharacterRange["A", "Z"], ncols];
ResourceFunction["RandomTabularDataset"][{3, lsColNames}, "Generators" -> Automatic]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/5a777789bd6b98a3.png)
|
| Out[30]= |
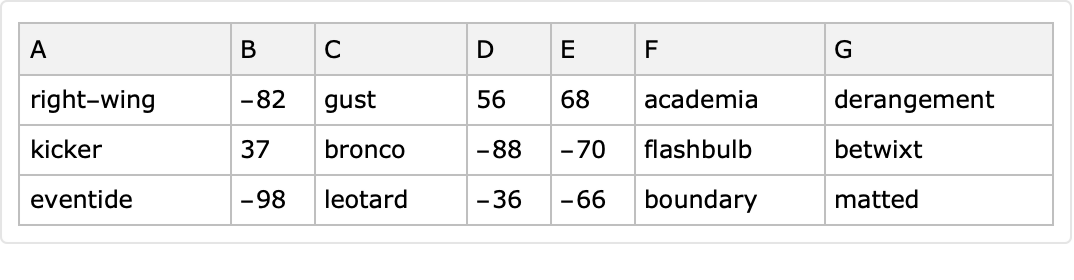
|
| In[31]:= |
![SeedRandom[32];
ResourceFunction["RandomTabularDataset"][{3, lsColNames}, "Generators" -> AssociationThread[Range[ncols], RandomChoice[{RandomReal[{-10, 10}, #] &, RandomInteger[{-100, 100}, #] &, RandomWord[#] &}, ncols]]]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/034fc7c6a657e88c.png)
|
| Out[32]= |
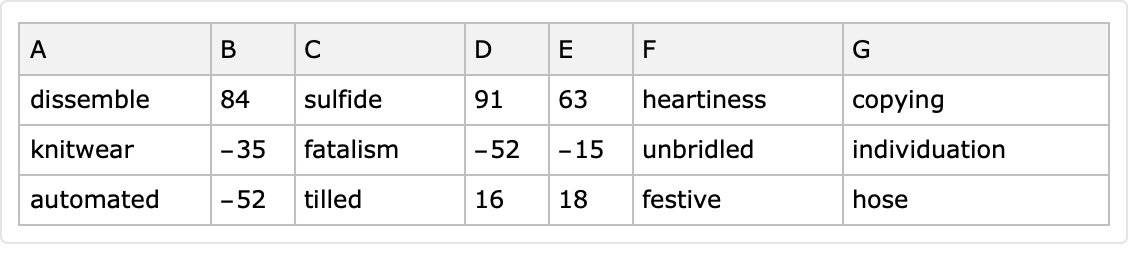
|
Here is a table that shows which generator is used for which column:
| In[33]:= |
![SeedRandom[32];
ResourceFunction["GridTableForm"]@
AssociationThread[lsColNames, RandomChoice[{RandomReal[{-10, 10}, #] &, RandomInteger[{-100, 100}, #] &, RandomWord[#] &}, ncols]]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/01a759d980d999a9.png)
|
| Out[34]= |

|
Specify all values to be generated by RandomInteger:
| In[35]:= |
|
| Out[36]= |
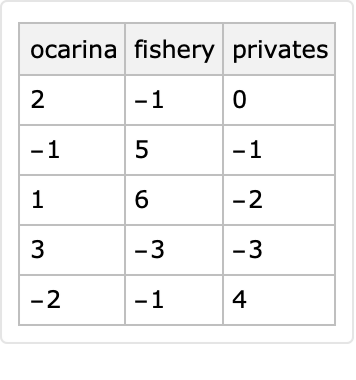
|
If the generators are given in a list, then that list is repeated to match all columns:
| In[37]:= |
![SeedRandom[32];
ResourceFunction["RandomTabularDataset"][{3, 5}, "Generators" -> {Table[RandomImage[], #] &, RandomReal[100, #] &}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/4dbb9e9bb5511915.png)
|
| Out[38]= |
|
Specify the values of the first column to be generated with RandomColor and the values of the second column to be generated with PoissonDistribution. The third column has values derived from the default generator:
| In[39]:= |
![SeedRandom[32];
ResourceFunction["RandomTabularDataset"][{10, 3}, "Generators" -> <|1 -> (RandomColor[#] &), 2 -> (RandomVariate[PoissonDistribution[300], #] &)|>]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/35bac09ba8503431.png)
|
| Out[40]= |
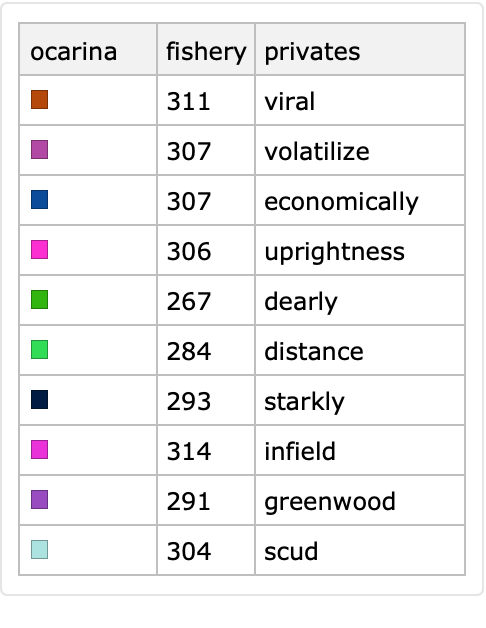
|
Generators using built-in symbolic distributions can be specified in a short form. Instead of specifying column value generation with RandomVariate, just the symbolic distributions can be used.
Use NormalDistribution for both columns, first with the standard specification and next with the short form:
| In[41]:= |
![SeedRandom[12];
\[ScriptCapitalD]1 = NormalDistribution[100, 2];
ResourceFunction["RandomTabularDataset"][{6, 2}, "ColumnNamesGenerator" -> ({"RandomVariate[\[ScriptCapitalD]1,#]&", "\[ScriptCapitalD]1"} &), "Generators" -> <|1 -> (RandomVariate[\[ScriptCapitalD]1, #] &), 2 -> \[ScriptCapitalD]1|>]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/6fdd62bb02db1c56.png)
|
| Out[26]= |
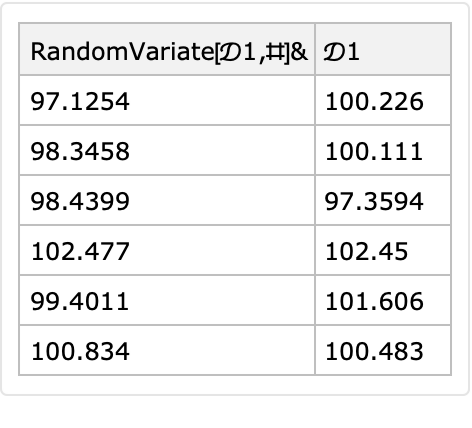
|
Here is another example using a derived, mixture distribution:
| In[42]:= |
![SeedRandom[12];
\[ScriptCapitalD]2 = MixtureDistribution[{1, 1}, {PoissonDistribution[13], BinomialDistribution[200, 0.4]}];
ResourceFunction["RandomTabularDataset"][{6, 2}, "ColumnNamesGenerator" -> ({"RandomVariate[\[ScriptCapitalD]2,#]&", "\[ScriptCapitalD]2"} &), "Generators" -> <|1 -> (RandomVariate[\[ScriptCapitalD]2, #] &), 2 -> \[ScriptCapitalD]2|>]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/60935bf6715caf90.png)
|
| Out[26]= |

|
Use the option "MaxNumberOfValues" to specify the maximum number of (non-missing) values in the generated random dataset:
| In[43]:= |
![Table[SeedRandom[22]; Labeled[ResourceFunction["RandomTabularDataset"][{3, 4}, "MaxNumberOfValues" -> n], n, Top], {n, {Automatic, 6}}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/4e019298d0009d4f.png)
|
| Out[43]= |
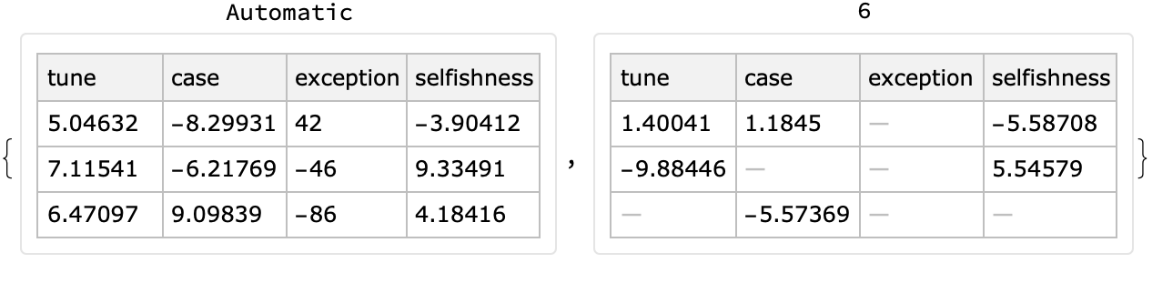
|
Use the option "MinNumberOfValues" to specify the minimum number of (non-missing) values in the generated random dataset:
| In[44]:= |
![Grid[Table[SeedRandom[12]; Labeled[ResourceFunction["RandomTabularDataset"][{3, 4}, "MinNumberOfValues" -> n1, "MaxNumberOfValues" -> n2], {n1, n2}, Top], {n1, {Automatic, 3}}, {n2, {Automatic, 6}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/5b972ca6d5274f8a.png)
|
| Out[44]= |

|
The value of "MinNumberOfValues" is ignored if it is greater than "MaxNumberOfValues":
| In[45]:= |
|
| Out[46]= |

|
The option "RowKeys" specifies whether the generated dataset has row keys:
| In[47]:= |
|
| Out[48]= |
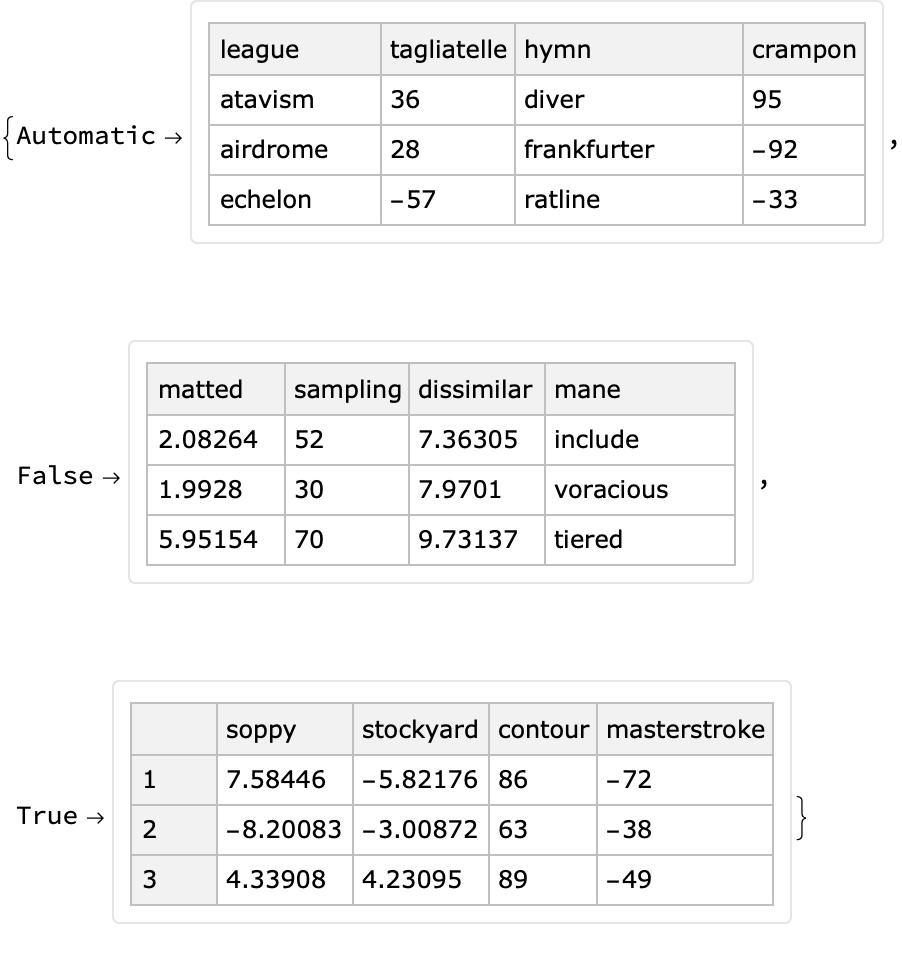
|
If the option value is Automatic then a random choice between False and True is made; False is chosen more often:
| In[49]:= |
|
| Out[50]= |
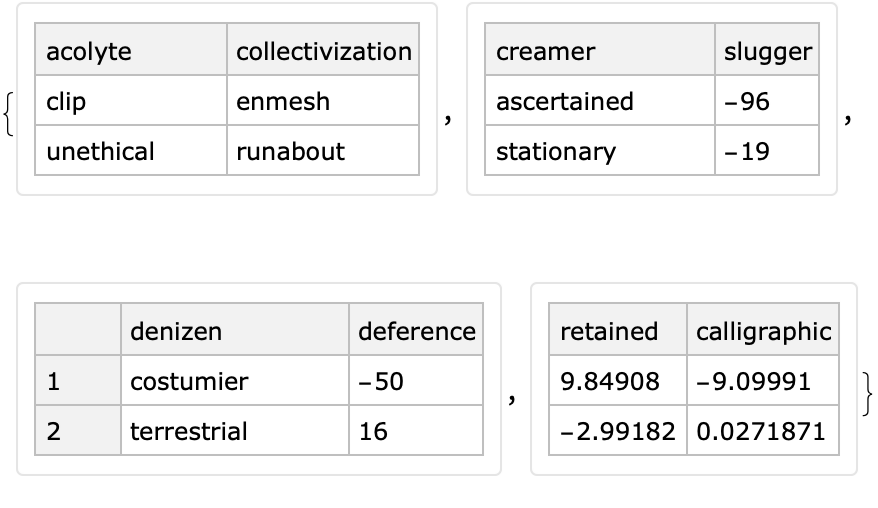
|
The generators can be pointwise or vectorwise; in general, pointwise generation is much slower:
| In[51]:= |
![SeedRandom[81];
AbsoluteTiming[
Table[ResourceFunction["RandomTabularDataset"][{20, 5}, "Generators" -> RandomWord, "PointwiseGeneration" -> True], 10];]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/165c5fe325dd9674.png)
|
| Out[52]= |
|
| In[53]:= |
![SeedRandom[81];
AbsoluteTiming[
Table[ResourceFunction["RandomTabularDataset"][{20, 5}, "Generators" -> RandomWord, "PointwiseGeneration" -> False], 10];]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/6a0b4ac5a8e975fb.png)
|
| Out[54]= |
|
A single call to a pointwise generator produces a single value:
| In[55]:= |
![SeedRandom[99];
k = 0;
ResourceFunction["RandomTabularDataset"][{3, 5}, "Generators" -> {(k++ &)}, "PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/2994a185fcd18e44.png)
|
| Out[53]= |
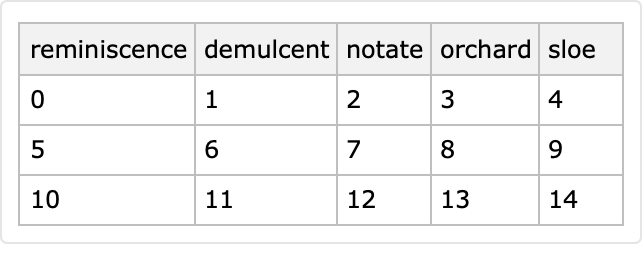
|
A pointwise generator takes entry coordinates as a single argument:
| In[56]:= |
![SeedRandom[99];
k = 0;
ResourceFunction["RandomTabularDataset"][{3, 5}, "Generators" -> {(F[#] &)}, "PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/3a166af911161393.png)
|
| Out[57]= |

|
A single call to a vectorwise generator produces a vector of values with length corresponding to the number of rows:
| In[58]:= |
|
| Out[59]= |
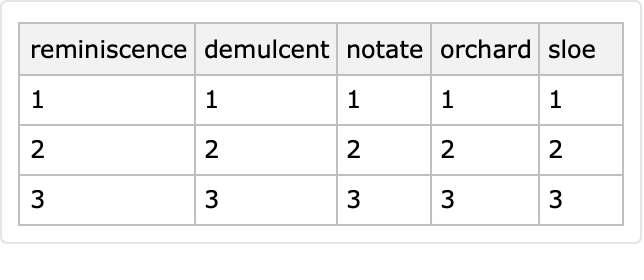
|
A vectorwise generator is a two-argument function consisting of vector length and a list of entry coordinates:
| In[60]:= |
|
| Out[53]= |
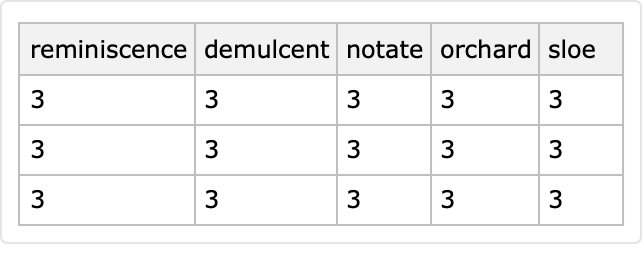
|
| In[61]:= |
|
| Out[58]= |

|
The ability to generate random datasets (tabular or hierarchical) is very useful for developing and testing data wrangling, data science and machine learning algorithms.
Here we use the resource functions RecordsSummary and ParallelCoordinatesPlot:
| In[62]:= |
![SeedRandom[83];
dsRand1 = ResourceFunction["RandomTabularDataset"][{120, 3}, "Generators" -> <|
1 -> With[{ws = RandomWord[4]}, RandomChoice[ws, #] &]|>];
Row[{dsRand1, Spacer[3], ResourceFunction["RecordsSummary"][dsRand1], Spacer[3], ResourceFunction["ParallelCoordinatesPlot"][
Values /@ Normal[GroupBy[dsRand1, #[[1]] &, #[[All, {2, 3}]] &]], ImageSize -> Medium]}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/1afee7c35f51f9ed.png)
|
| Out[61]= |
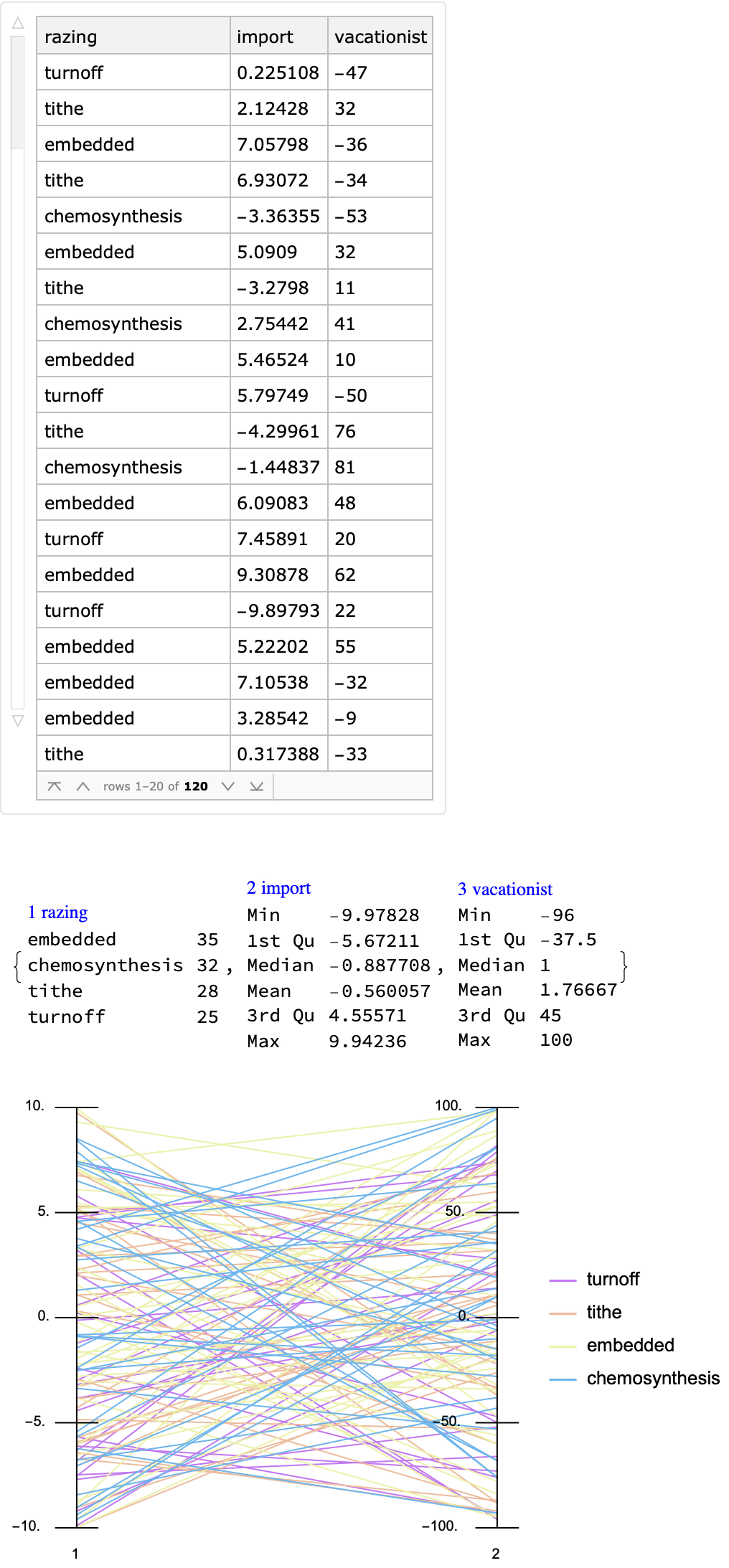
|
Here is an association of random tabular datasets:
| In[63]:= |
![aTbls = Association[
Table[i -> ResourceFunction[
"RandomTabularDataset"][{Automatic, RandomInteger[{2, 6}]}], {i,
3}]];
Magnify[#, 0.6] & /@ aTbls](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/58b62febe92cb9fd.png)
|
| Out[60]= |
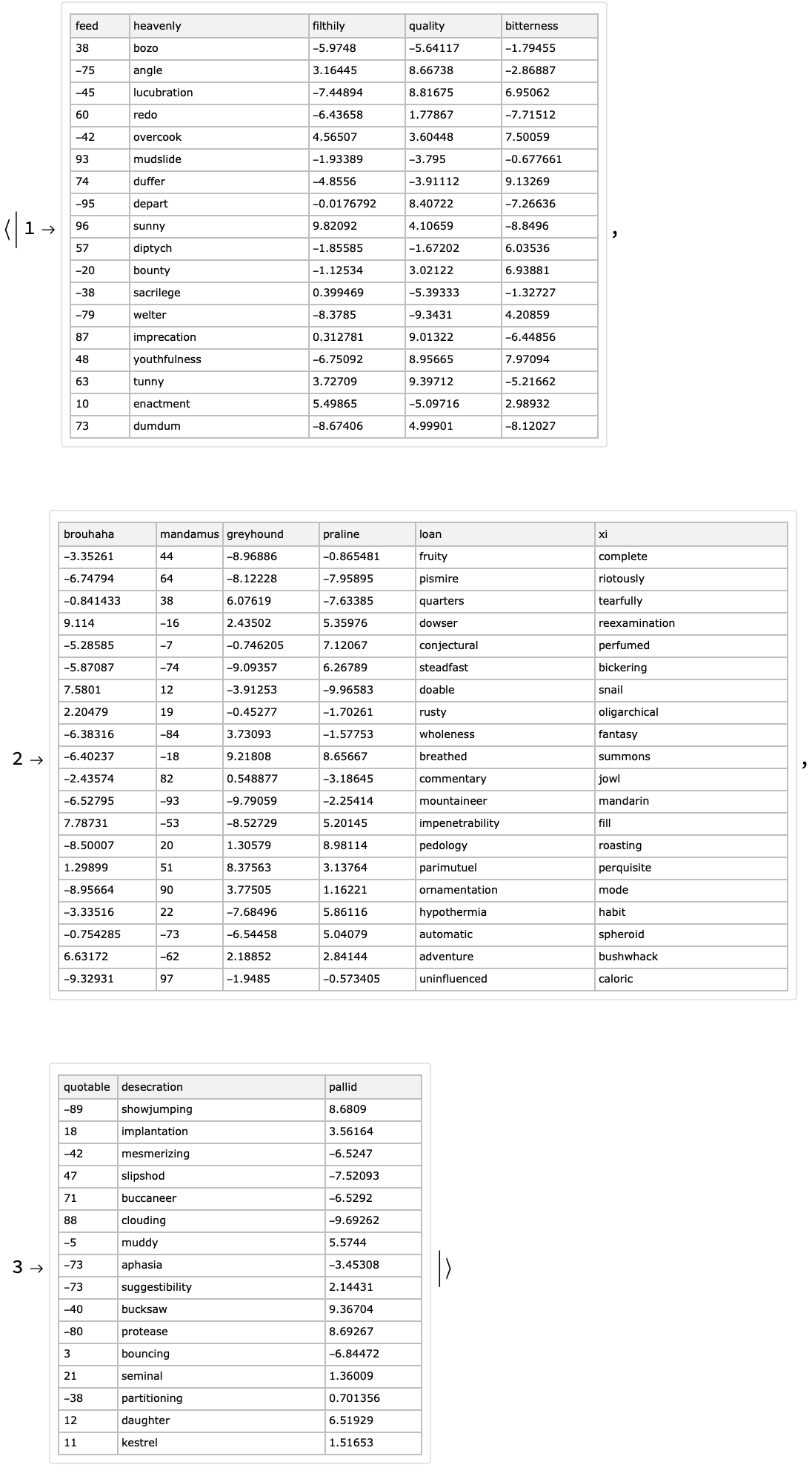
|
The generated datasets can be summarized with the resource function RecordsSummary:
| In[64]:= |
![SeedRandom[26];
<|"Dimensions" -> Dimensions[#], "Summary" -> ResourceFunction["RecordsSummary"][#]|> & /@ aTbls](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/04b7a173e62bd72b.png)
|
| Out[56]= |
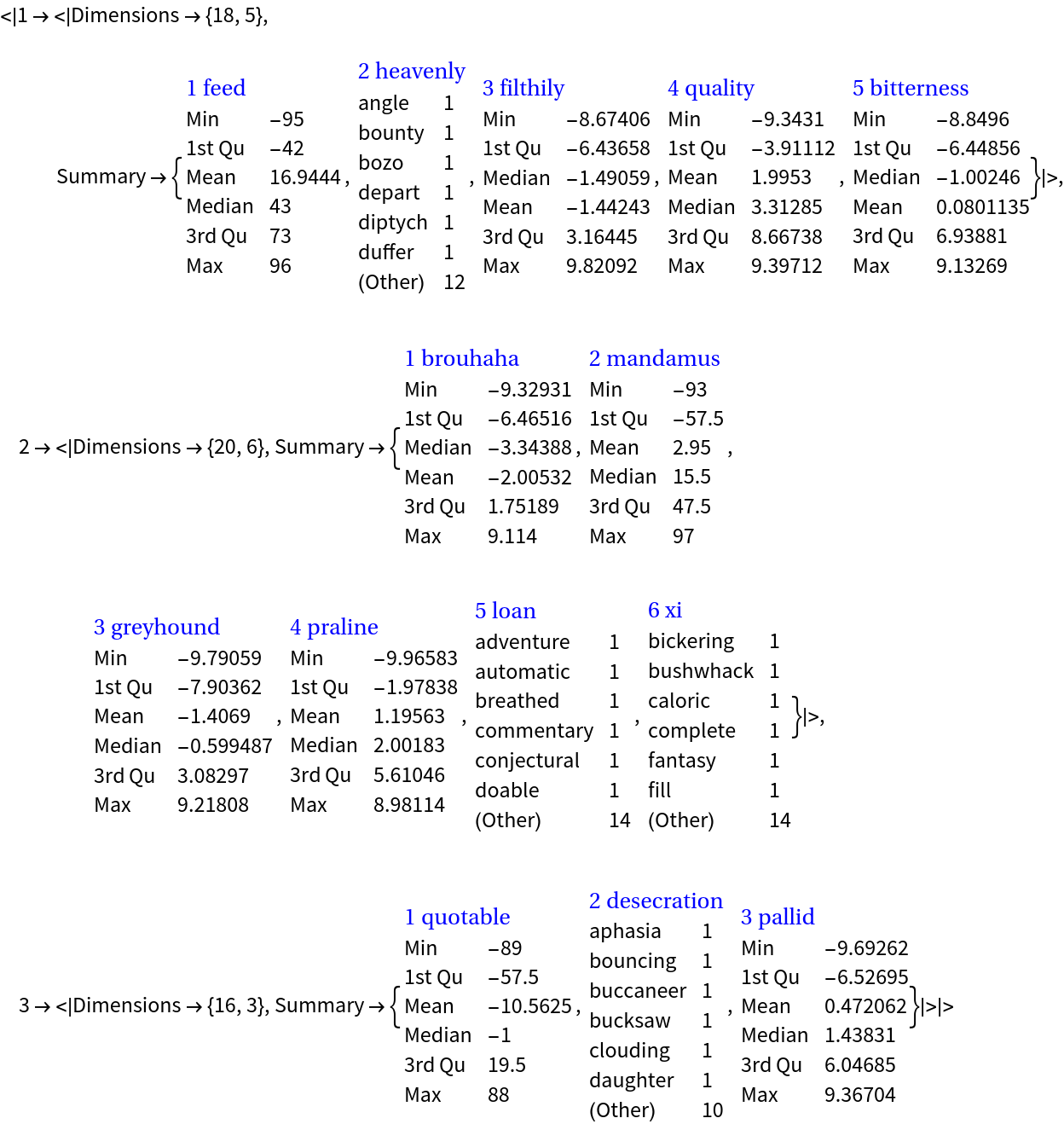
|
Here is a randomly generated tabular dataset in wide form:
| In[65]:= |
|
| Out[60]= |
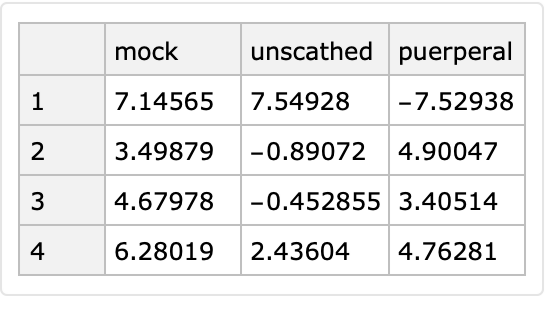
|
Here is the same the dataset in long form:
| In[66]:= |
|
| Out[56]= |
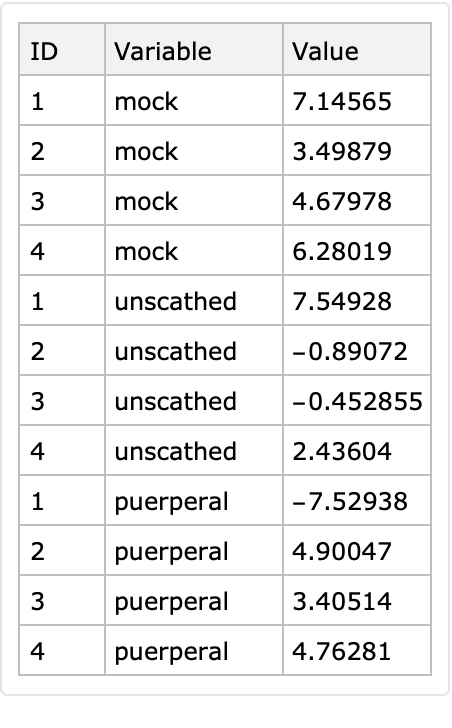
|
The resource function CrossTabulate can be used to convert from long form to wide form:
| In[67]:= |
|
| Out[67]= |

|
Here we verify that result from CrossTabulate is the same as the generated wide form (by sorting the keys in the wide form first):
| In[68]:= |
|
| Out[68]= |
|
RandomTabularDataset can be seen as a dataset version of the results from ProductDistribution. Here is a ProductDistribution of two independent variables:
| In[69]:= |
![SeedRandom[3];
\[ScriptCapitalD] = ProductDistribution[SkewNormalDistribution[0, 2, 0.1], PoissonDistribution[10]];
lsVals = RandomVariate[\[ScriptCapitalD], 9000];
Row[{Framed@ColumnForm@RandomSample[lsVals, 4], Spacer[10], Histogram3D[lsVals, 12, ImageSize -> Medium]}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/2c58aa9a0a713b62.png)
|
| Out[56]= |
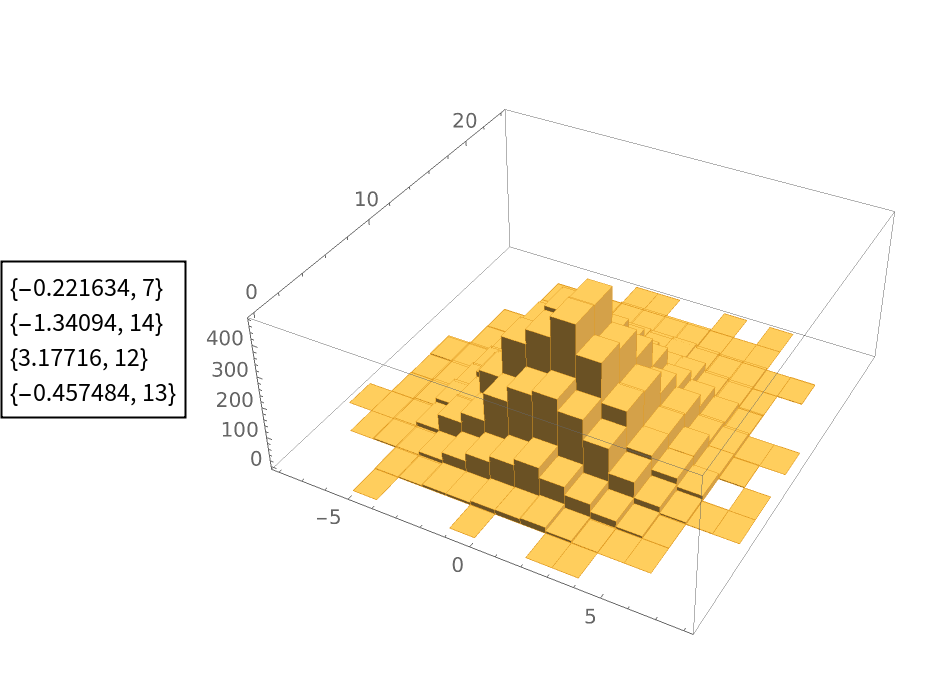
|
Generate a random tabular dataset with 9000 rows and generators that correspond to the distributions given to ProductDistribution above:
| In[70]:= |
![SeedRandom[3];
dsRProd = ResourceFunction["RandomTabularDataset"][{9000, 2}, "Generators" -> {SkewNormalDistribution[0, 2, 0.1], PoissonDistribution[10]}];
Row[{RandomSample[dsRProd, 4], Spacer[10], Histogram3D[Normal[dsRProd[Values]], 12, ImageSize -> Medium]}]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/6e2af74fee692f58.png)
|
| Out[33]= |
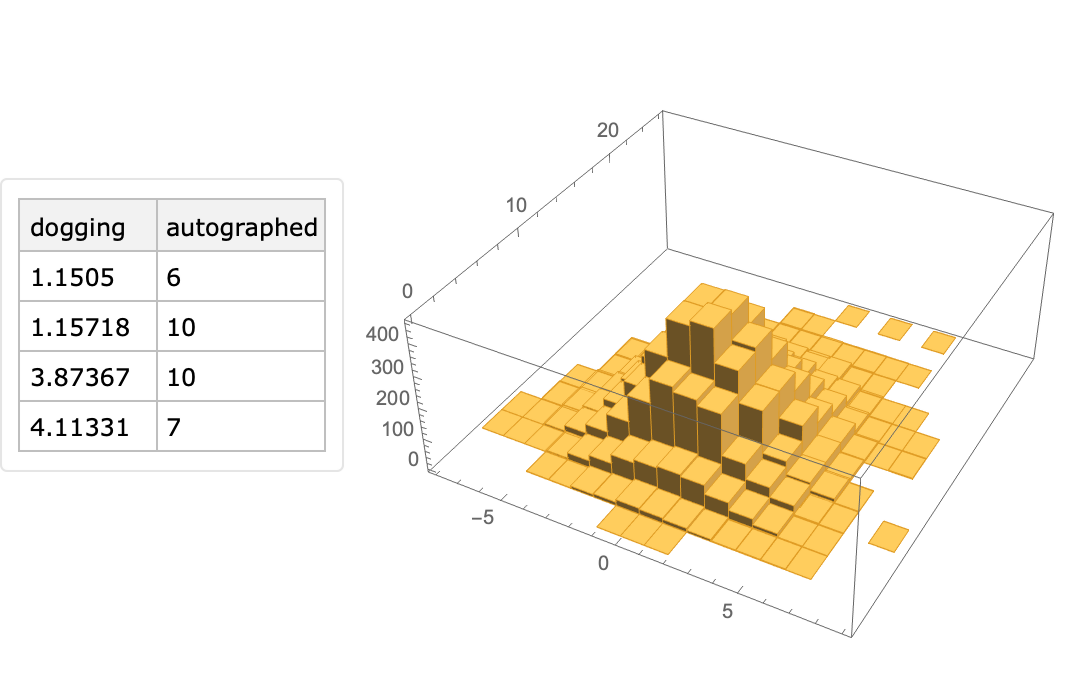
|
The resource function ExampleDataset makes datasets from ExampleData. Here is an example dataset:
| In[71]:= |
|
| Out[71]= |
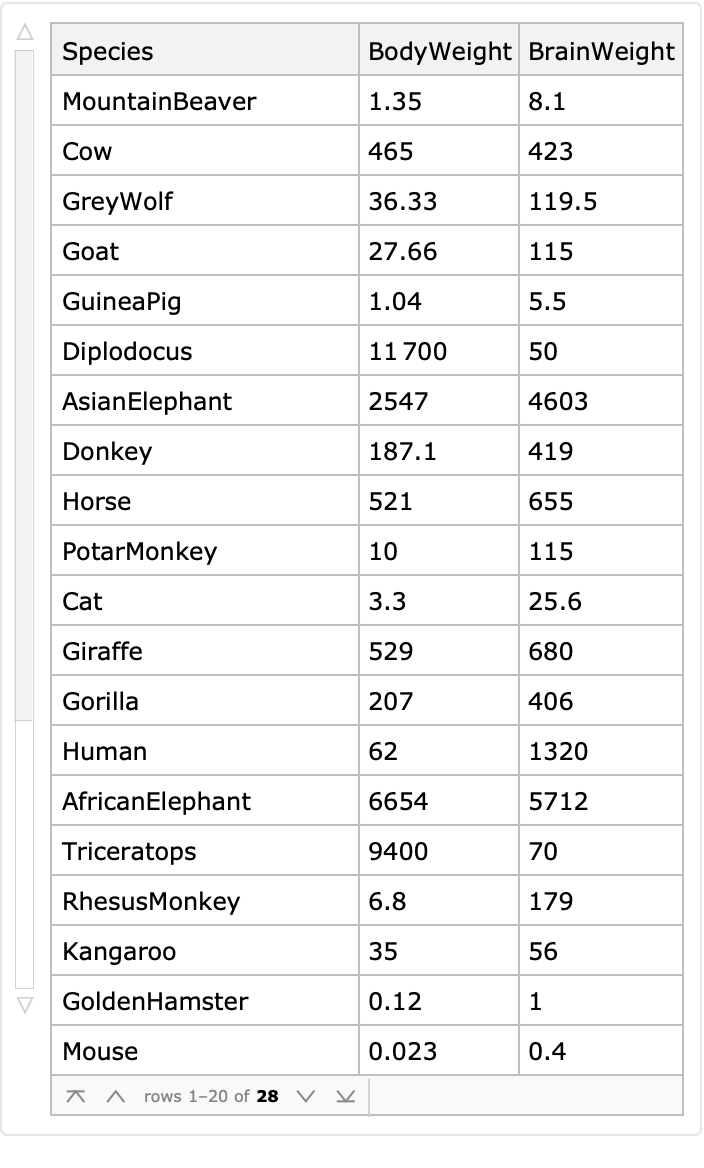
|
Here is a similar random dataset:
| In[72]:= |
![SeedRandom[23];
dsCW = ResourceFunction["RandomTabularDataset"][
{60, {"Creature", "BodyWeight", "BrainWeight"}},
"Generators" -> <| 1 -> (Table[
StringJoin[
RandomChoice[CharacterRange["a", "z"], 5]], #] &),
2 -> FindDistribution[Normal@dsAW[All, "BodyWeight"]],
3 -> FindDistribution[Normal@dsAW[All, "BrainWeight"]]|>];
IQB = Interval[
Quartiles[N@Normal[dsAW[All, #BrainWeight/#BodyWeight &]]][[{1, 3}]]];
dsCW[Select[IntervalMemberQ[IQB, #BrainWeight/ #BodyWeight] &]]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/3bfdc643e14baef9.png)
|
| Out[70]= |
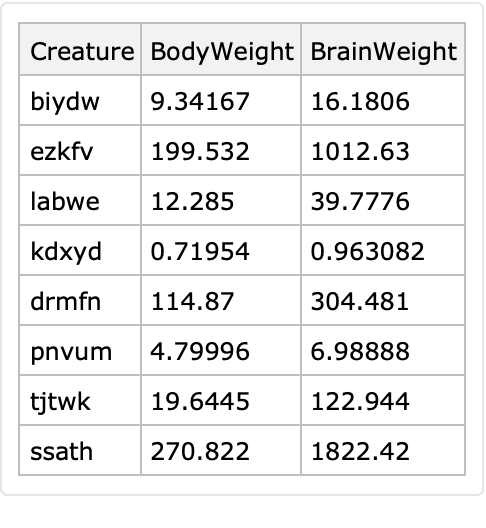
|
If the generated (unique) column names are too few, then additional column names are generated as string forms of integers:
| In[73]:= |
![SeedRandom[32];
ResourceFunction["RandomTabularDataset"][{5, 6}, "ColumnNamesGenerator" -> (RandomChoice[Characters["abc"], #] &)]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/718bd83d8fb66f19.png)
|
| Out[72]= |
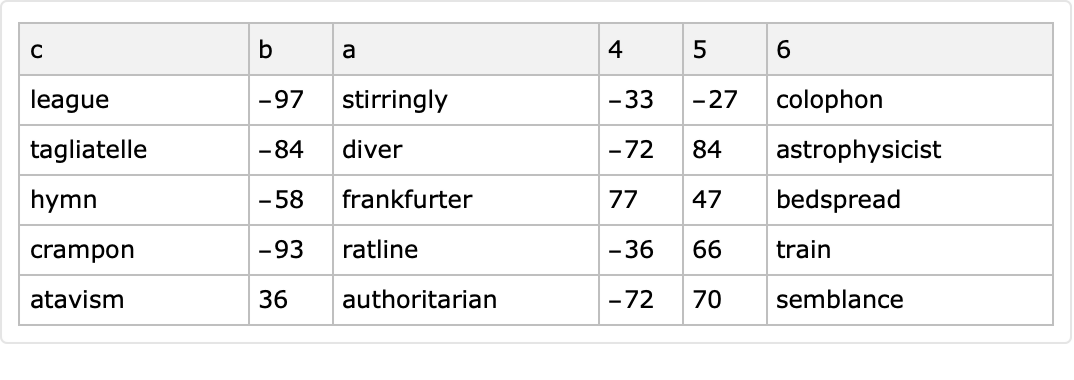
|
Using pointwise generators with "PointwiseGeneration" set to False produces constant value columns:
| In[74]:= |
|
| Out[72]= |
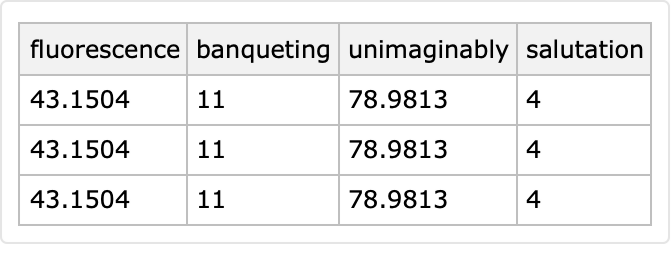
|
If the value of the option "MaxNumberOfValues" is zero or if the value of the option "Generators" is None, then the generated dataset has only Missing values:
| In[75]:= |
![SeedRandom[45];
{ResourceFunction["RandomTabularDataset"][{3, 4}, "MaxNumberOfValues" -> 0], ResourceFunction["RandomTabularDataset"][{3, 2}, "Generators" -> None]}](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/3a4af00ee453a1e2.png)
|
| Out[72]= |
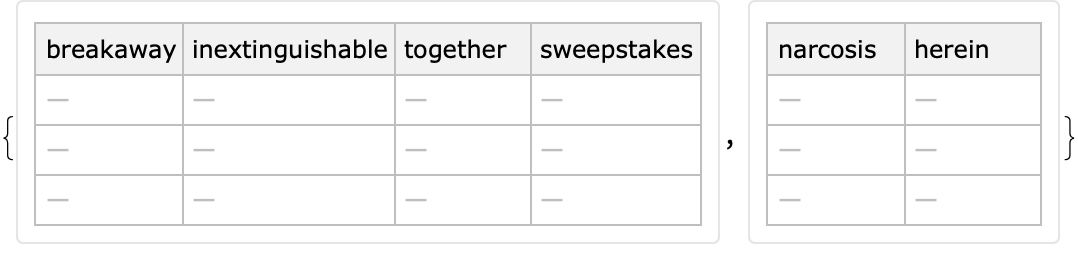
|
If the number of rows and columns are equal to one, then the dataset has a one-dimensional form:
| In[76]:= |
|
| Out[72]= |
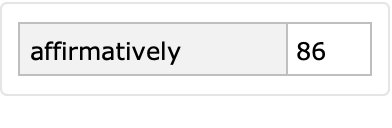
|
A table of random tabular datasets:
| In[77]:= |
![SeedRandom[44];
Multicolumn[
Table[Magnify[
ResourceFunction["RandomTabularDataset"][4, "RowKeys" -> RandomChoice], 0.5], 8], 2]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/3c55467da512ec18.png)
|
| Out[72]= |
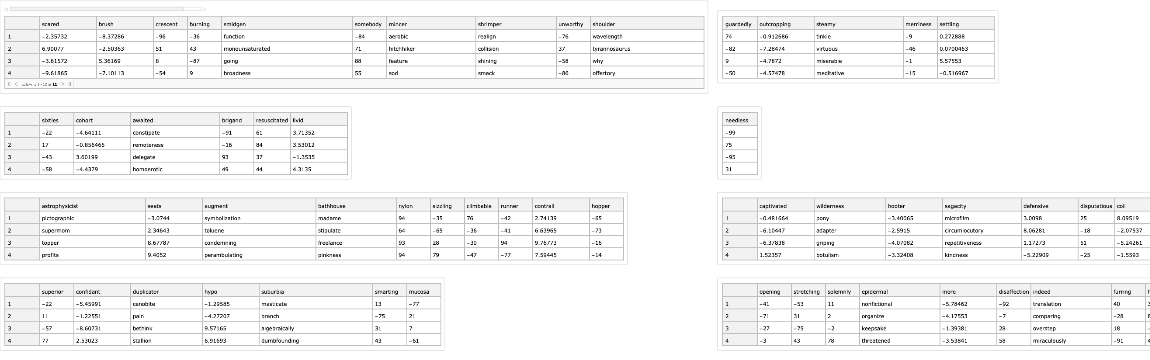
|
Here is a random dataset with values produced by resource functions that generate random objects:
| In[78]:= |
![SeedRandom[3];
ResourceFunction[
"RandomTabularDataset"][{5, {"Mondrian", "Mandala", "Haiku", "Scribble", "Maze", "Fortune"}},
"Generators" ->
<|
1 -> (ResourceFunction["RandomMondrian"][] &),
2 -> (ResourceFunction["RandomMandala"][] &),
3 -> (ResourceFunction["RandomEnglishHaiku"][] &),
4 -> (ResourceFunction["RandomScribble"][] &),
5 -> (ResourceFunction["RandomMaze"][12] &),
6 -> (ResourceFunction["RandomFortune"][] &)|>,
"PointwiseGeneration" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/4db/4db5bf59-17c7-48ee-963c-a90ebedcd8d6/3c3e75bdb16a9d60.png)
|
| Out[72]= |
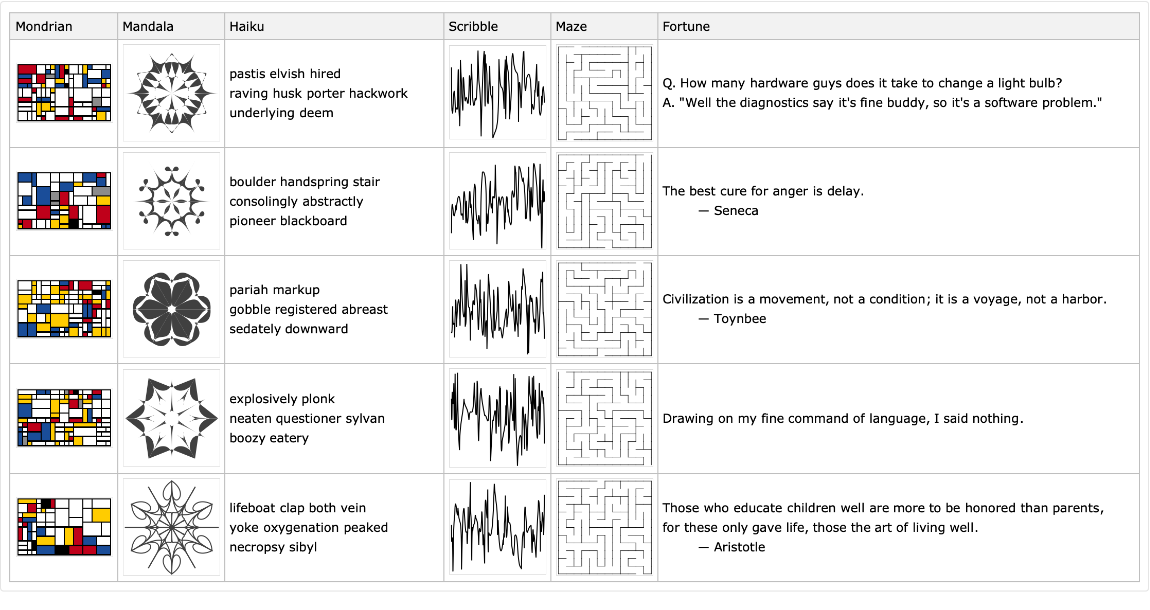
|
This work is licensed under a Creative Commons Attribution 4.0 International License