Basic Examples (4)
Get information about the structure of a piece of Japanese text:
Get a specific property:
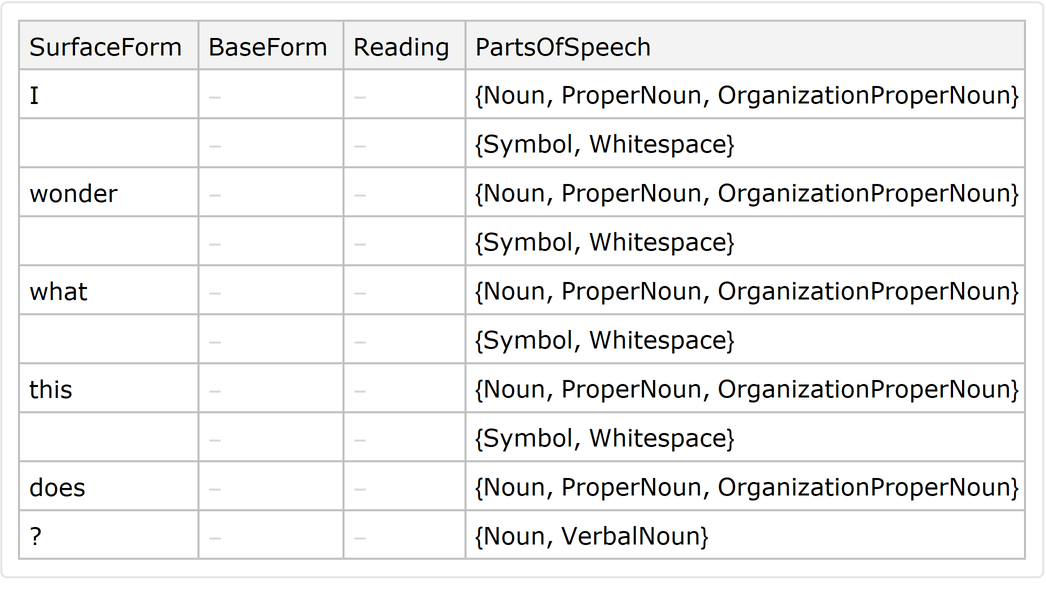
Return a Dataset:
Specify a list of properties:
Properties and Relations (5)
Japanese text is typically written without spaces, so typical structural segmentation does not work:
JapaneseTextTokenizer can identify individual words without spaces:
Readings for kanji and particles are context sensitive:
Compare to Transliterate on individual particles:
The readings of "wa" and "o" correspond to the pronunciation (this example requires a Japanese voice to be installed):
See how the reading for a character changes depending on context:
Listen to the difference (this example requires a Japanese voice to be installed):
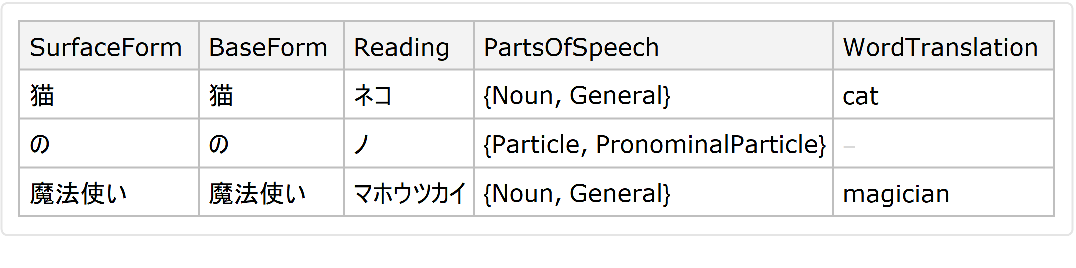
JapaneseTextTokenizer can include translations of individual words in the output:
Compare to using WordTranslation:
TextTranslation provides better results for text since it takes context into consideration:
FuriganaForm uses JapaneseTextTokenizer to parse text:
Get similar results using JapaneseTextTokenizer:
Options (12)
EnglishPartsOfSpeech (2)
By default, parts of speech are given as English string tokens:
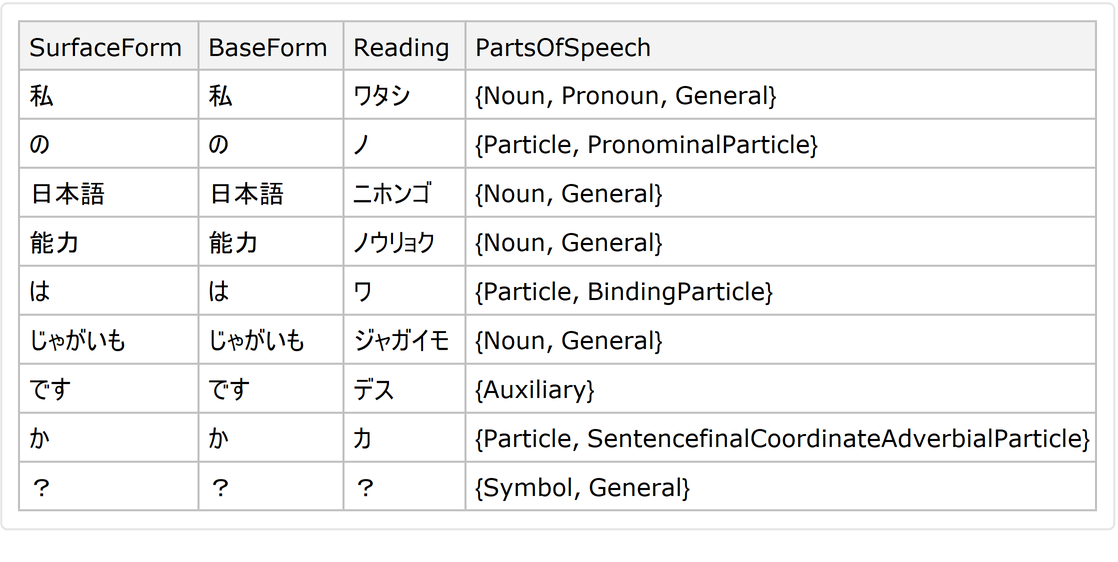
Get the parts of speech in Japanese instead of English:
Language (3)
By default, when specifying "TranslateWords"→True, individual words will be translated to the language defined by $Language:
Get translations in another language:
Entity objects are also supported:
MissingString (3)
By default, a Missing object is returned when values are not found:
Specify a string to use instead:
Missing values can also typically be avoided by using full-width Japanese characters:
Reading (3)
Specify which writing system to show the readings in:
Generate phonetic romaji text from Japanese:
Entity objects are also supported:
TranslateWords (1)
Include word translations when available:
Applications (2)
Create a function to compute word counts in Japanese:
Compare the total number of words for the same document in English using WordCounts:
Create a variant of TextCases that can find parts of speech in Japanese text:
Get a list of the verbs used in the text:
Sort grammatical particles by their usage:
Possible Issues (4)
Results can be different for the same words depending on usage of kana/kanji:
Non-Japanese text will not return interesting results:
Punctuation should be given as full-width characters for more accurate part-of-speech tagging:
JapaneseTextTokenizer only provides translations for individual words (and does not account for context), so it should not be used to translate text:
Use TextTranslation for better results:


![Grid[Transpose[{If[
StringContainsQ[#SurfaceForm, _?ResourceFunction[
"KanjiQ"]], #Reading, ""], #SurfaceForm} & /@ data]]](https://www.wolframcloud.com/obj/resourcesystem/images/552/5525807d-e792-4094-b1a1-c2246f319296/5341ebf4a0b3d740.png)
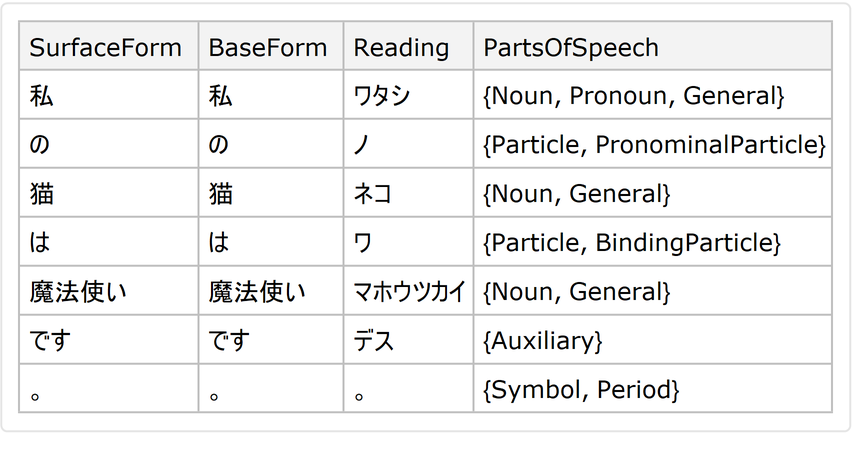
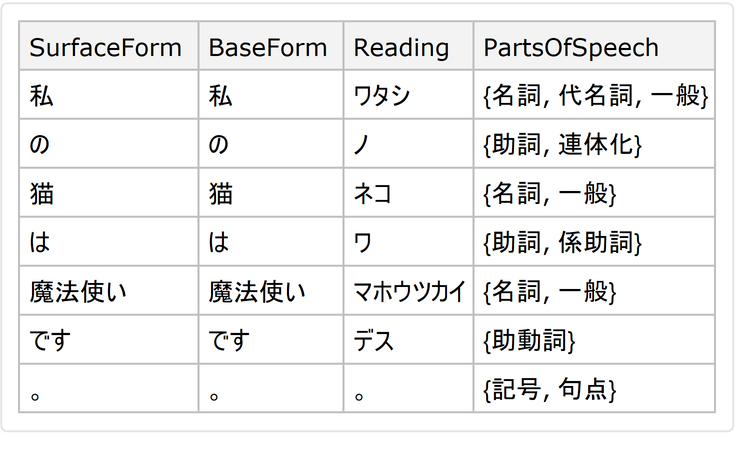
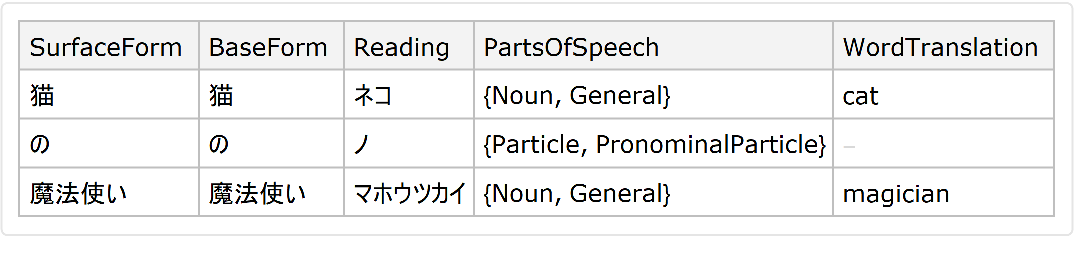
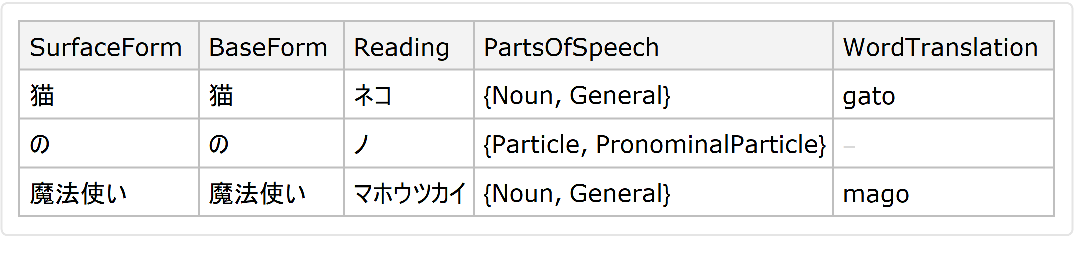
![ResourceFunction["JapaneseTextTokenizer"]["猫の魔法使い", "Dataset", "TranslateWords" -> True, Language -> Entity["Language", "English::385w8"]]](https://www.wolframcloud.com/obj/resourcesystem/images/552/5525807d-e792-4094-b1a1-c2246f319296/30d49a7f328f0f3e.png)
![ResourceFunction["JapaneseTextTokenizer"]["私は日本語を話せません", "Reading", "Reading" -> Entity["WritingScript", "Hiragana::jx343"]]](https://www.wolframcloud.com/obj/resourcesystem/images/552/5525807d-e792-4094-b1a1-c2246f319296/0e13bd2ad2dac448.png)
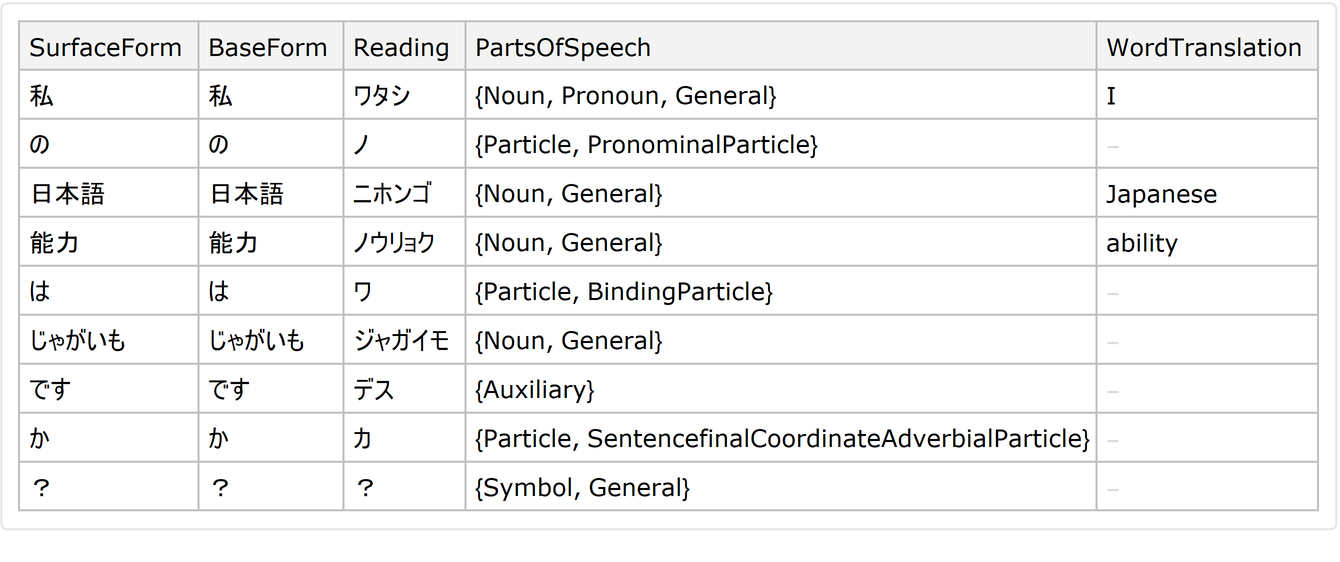
![japaneseTextCases[text_String, form_String] := Cases[ResourceFunction["JapaneseTextTokenizer"][
text, {"BaseForm", "PartsOfSpeech"}], KeyValuePattern[{"BaseForm" -> word_, "PartsOfSpeech" -> {___, form, ___}}] :> word];](https://www.wolframcloud.com/obj/resourcesystem/images/552/5525807d-e792-4094-b1a1-c2246f319296/619e1068c78fcf3f.png)