Wolfram Function Repository
Instant-use add-on functions for the Wolfram Language
Function Repository Resource:
Synthesize images using the Stable Diffusion neural network
ResourceFunction["StableDiffusionSynthesize"][prompt] synthesize an image given a string or explicit text embedding vector as prompt. | |
ResourceFunction["StableDiffusionSynthesize"][prompt→latent] use an initial image or a noise as latent for the diffusion starting point. | |
ResourceFunction["StableDiffusionSynthesize"][prompt→latent→guidanceScale] specify a guidance scale. | |
ResourceFunction["StableDiffusionSynthesize"][{negativeprompt,prompt}→latent→guidanceScale] specify a guidance scale with a negative prompt. | |
ResourceFunction["StableDiffusionSynthesize"][<|"Prompt"→…,"NegativePrompt"→…,"Latent"→…,"GuidanceScale"→…,…|>] provide an association with explicit arguments. | |
ResourceFunction["StableDiffusionSynthesize"][prompt,n] generate n instances for the same prompt specification. | |
ResourceFunction["StableDiffusionSynthesize"][{p1,p2,…}] generate multiple images. | |
ResourceFunction["StableDiffusionSynthesize"][{p1,p2,…},n] generate multiple images for each prompt. |
Generate an image by giving a text prompt:
| In[1]:= |
| Out[1]= |  |
Generate multiple images:
| In[2]:= |
| Out[2]= |  |
Guide an initial image with a prompt:
| In[3]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/6df4f0b4-d044-4fe5-8947-8b066939f673"]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/289ecaa44d49ba74.png) |
| Out[3]= |  |
Use negative prompt for additional guidance (bottom row):
| In[4]:= | ![Grid@ResourceFunction["StableDiffusionSynthesize"][{
"A cat in party hat",
{"image cut out, bad anatomy, bad composition, odd looking, weird, odd, unnatural", "A cat in party hat"}}, 3, BatchSize -> 3]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/32c4cb6d45c3cb55.png) |
| Out[4]= |  |
Use a precomputed text embedding:
| In[5]:= | ![embedding = NetModel[{"CLIP Multi-domain Feature Extractor", "InputDomain" -> "Text", "Architecture" -> "ViT-L/14"}][
"A cat in a party hat", NetPort[{"post_normalize", "Output"}]];](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/7f405b5fb580b8c3.png) |
| In[6]:= |
| Out[6]= |  |
Use an explicit initial noise:
| In[7]:= |
| In[8]:= |
| Out[8]= |  |
A higher guidance scale encourages generation of images that are more closely linked to the prompt, usually at the expense of lower image quality:
| In[9]:= | ![SeedRandom[7];
noise = RandomVariate[NormalDistribution[], {4, 64, 64}];
prompt = "A cat in party hat";
negativePrompt = "image cut out, bad anatomy, bad composition, odd looking, weird, odd, unnatural";](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/506bf686955881df.png) |
| In[10]:= | ![GraphicsRow@ResourceFunction["StableDiffusionSynthesize"][{
prompt -> noise,
{negativePrompt, prompt} -> noise -> 3,
{negativePrompt, prompt} -> noise,
{negativePrompt, prompt} -> noise -> 14}]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/38445a40cde192c0.png) |
| Out[10]= |  |
Specify encoding strength (how much to transform the reference image):
| In[11]:= |
| In[12]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/2b5a1059-1d25-4155-b1b3-1d6b4059ef84"]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/64d56b3cacf6c63d.png) |
| Out[12]= |  |
Specify number of diffusion iterations (default is 50):
| In[13]:= |
| Out[13]= |  |
Default Automatic reporting shows latent images in the process of diffusion:
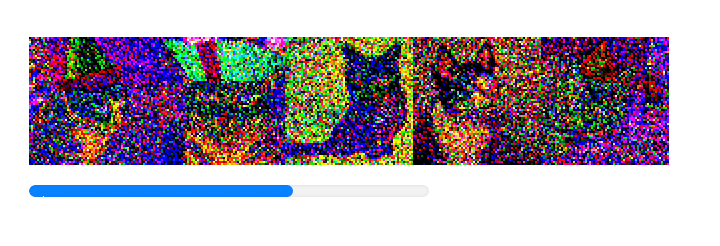
ProgressReporting→False disables it.
Return intermediate images for each diffusion iteration:
| In[14]:= | ![GraphicsRow[
BlockRandom[SeedRandom[33]; ResourceFunction["StableDiffusionSynthesize"][
"A cat in a party hat", "ReturnIntermediates" -> True, BatchSize -> 3][[;; ;; 5]]]]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/087c27e04f4d11e3.png) |
| Out[14]= |  |
Return a pair with a list of latents and the result {latents,result}:
| In[15]:= | ![GraphicsRow[
Image /@ Transpose[
BlockRandom[SeedRandom[33]; ResourceFunction["StableDiffusionSynthesize"][
"A cat in a party hat", "ReturnLatents" -> True][[
1, ;; ;; 5]]], {1, 4, 2, 3}]]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/2752696ea7a61acb.png) |
| Out[15]= |  |
Specify custom neural network parts from a different trained checkpoints, modified by Text Inversion, LoRA or other techniques:
| In[16]:= | ![ResourceFunction[
"StableDiffusionSynthesize"]["A cat in a party hat", 5, "TextEncoder" -> modifiedTextEncoder, "UNet" -> modifiedUnet, "Decoder" -> modifiedDecoder]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/7c34f64a2fbae92a.png) |
| Out[16]= |  |
By default TargetDevice is "GPU" as the network is extremely slow and not recommended to be run on "CPU":
| In[17]:= |
| Out[17]= |
"UNetTargetDevice" and "UNetBatchSize" options can overwrite TargetDevice and BatchSize, which may be useful when Decoder can't handle the same BatchSize for decoding too many images:
Progressively modify the neural network to see how it gradually breaks down:
| In[18]:= |
| In[19]:= |
| In[20]:= |
| In[21]:= |
| In[22]:= | ![GraphicsGrid[Partition[images = Table[
ResourceFunction["StableDiffusionSynthesize"][
"A cat in a party hat" -> seedimage, "UNet" -> NetReplacePart[unet, Merge[{arrays, randomArrays}, Apply[Normal[#1 + p (#2 - #1)] &]]]],
{p, 0, .15, 0.01}
], 8]]](https://www.wolframcloud.com/obj/resourcesystem/images/931/931345fa-89a3-4152-be66-dc076a4536ea/255a55d50f0ef3b9.png) |
| Out[22]= |  |
Wolfram Language 13.0 (December 2021) or above
This work is licensed under a Creative Commons Attribution 4.0 International License