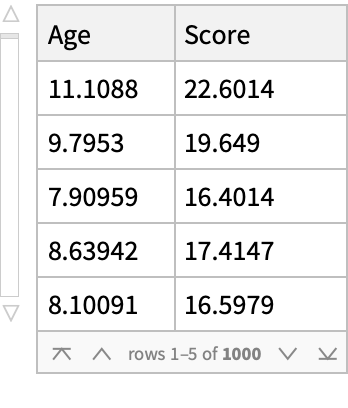
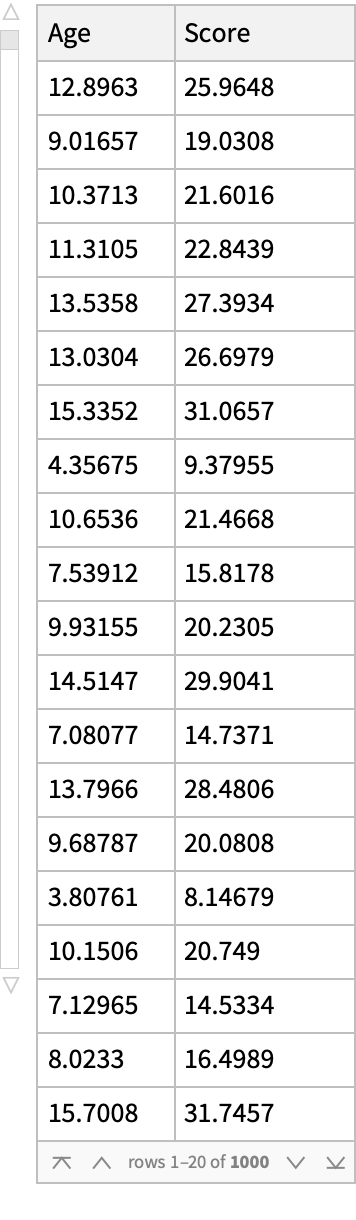
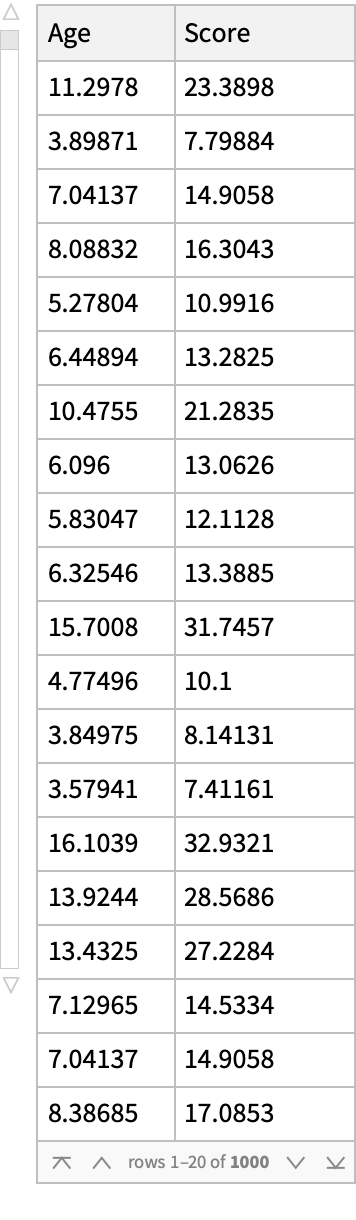
Basic Examples (3)
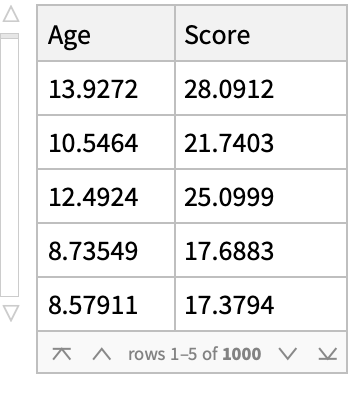
A dataset:
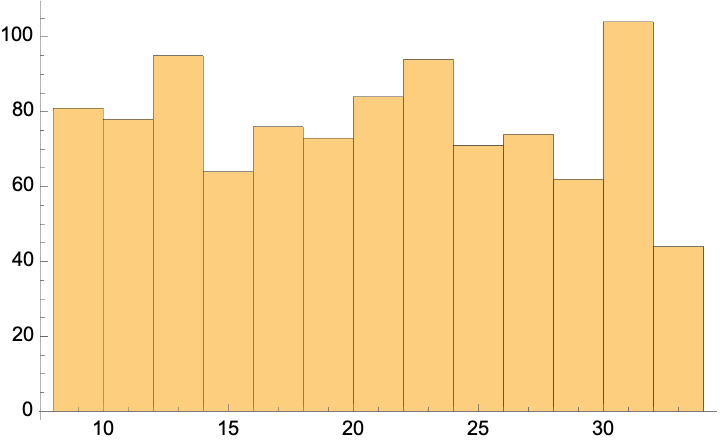
Resample the data so that the "Age" column is uniformly distributed:
Resample the data so that the "Age" column follows an Exponential[0.1] distribution:
Scope (2)
A dataset:
Compute the mean of the data in the "Score" column:
The target distribution for "Age" can be given as a fully specified distribution:
One or more parameters can also be estimated from the "Age" data:
A representative sample of "Age" values can also be provided:
The column being used for rebalancing can be specified by position instead of name:
Data can be provided as a Dataset of associations, a Dataset of lists or, as here, a List of lists:
If a column contains any non-numeric data, then it can be balanced against a CategoricalDistribution:
Non-numeric reference data will be converted into a CategoricalDistribution:
Applications (3)
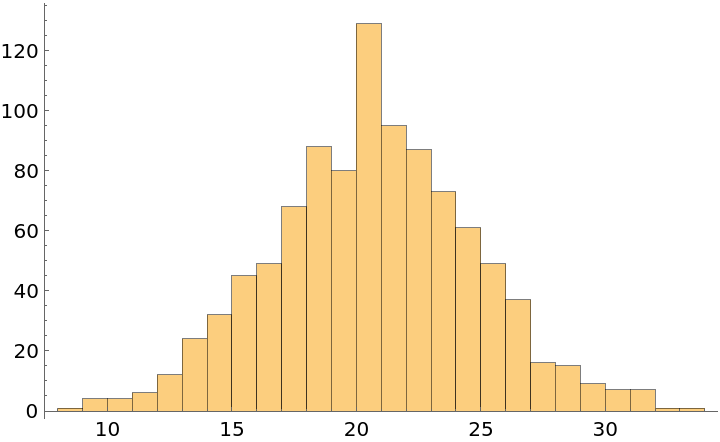
In this synthetic dataset of children's test scores, it would appear that the scores are normally distributed:
However, this is because the data sample was biased toward 10-year-olds. If we assume that, across the whole population, all ages are equally represented, then the "Score" distribution appears more uniform:
If we assume that the ages of the population follow a certain ExponentialDistribution, then we see a different result:
Properties and Relations (1)
After resampling the column used to rebalance it, the data should tend to the target distribution:
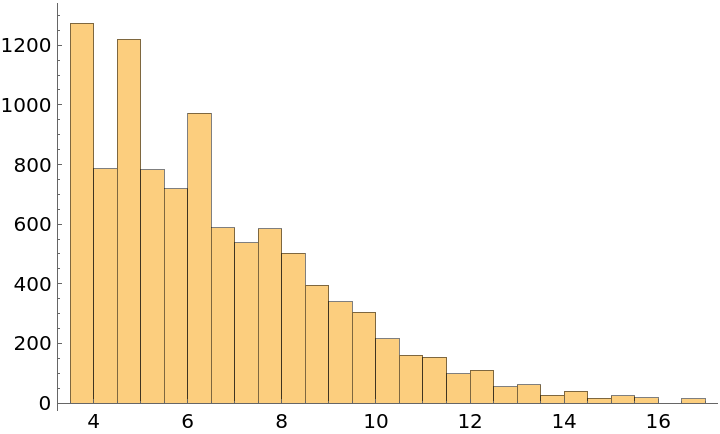
Possible Issues (1)
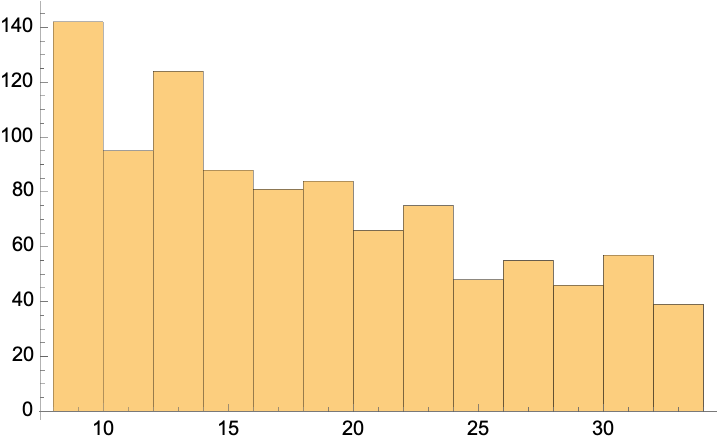
SampleRebalance only uses values from the original data and cannot always achieve the target reference distribution. In this example, there are no negative values, so the attempt to rebalance to NormalDistribution[0,5] results in the data distributed more like TruncatedDistribution[{0,∞},NormalDistribution[0,5]]:
![data = Dataset[
Table[age = RandomVariate[NormalDistribution[10, 2]]; <|
"Age" -> age, "Score" -> 2 age + RandomReal[]|>, {1000}], MaxItems -> 5]](https://www.wolframcloud.com/obj/resourcesystem/images/a1a/a1a6e728-3b83-4ba5-9c68-2d2c08fdeaa8/4db0b2ef86924816.png)
![data = Dataset[
Table[age = RandomVariate[NormalDistribution[10, 2]]; <|
"Age" -> age, "Score" -> 2 age + RandomReal[]|>, {1000}], MaxItems -> 5]](https://www.wolframcloud.com/obj/resourcesystem/images/a1a/a1a6e728-3b83-4ba5-9c68-2d2c08fdeaa8/2b2c24e92b4527d9.png)
![data2 = ResourceFunction[
"SampleRebalance"][{{"A", 1}, {"A", 2}, {"B", 3}, {"C", 4}}, 10000,
1, CategoricalDistribution[{"A", "B", "C"}]];
Counts[data2[[All, 1]]]](https://www.wolframcloud.com/obj/resourcesystem/images/a1a/a1a6e728-3b83-4ba5-9c68-2d2c08fdeaa8/3363a91b742c9756.png)


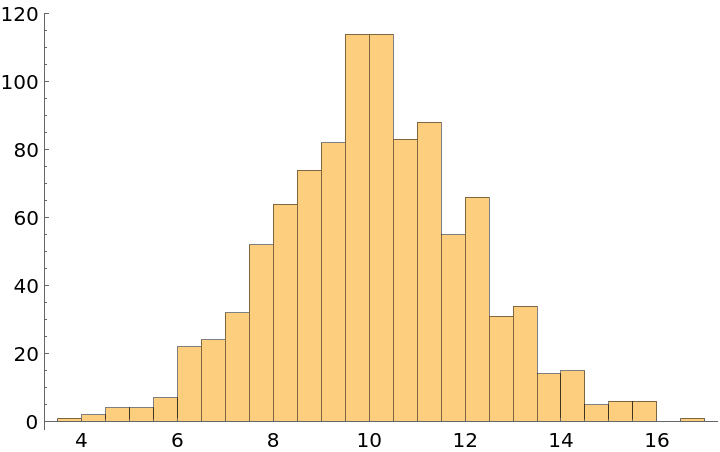
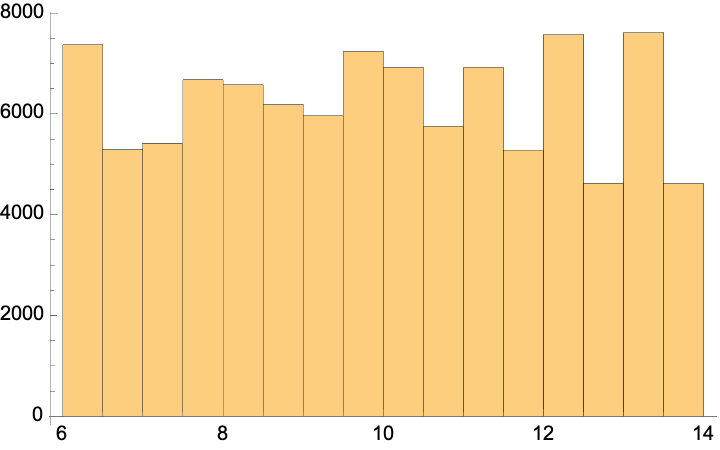
![data = Dataset[
Table[age = Abs@RandomVariate[NormalDistribution[10, 2]]; <|
"Age" -> age, "Score" -> 2 age + RandomReal[]|>, {1000}], MaxItems -> 5];
ResourceFunction["SampleRebalance"][data, 10000, "Age", NormalDistribution[0, 5]][Histogram, "Age"]](https://www.wolframcloud.com/obj/resourcesystem/images/a1a/a1a6e728-3b83-4ba5-9c68-2d2c08fdeaa8/1bae1b924b8459e4.png)