Applications (19)
The Jaccard dissimilarity measure, sometimes called Tanimoto dissimilarity, has its origins in ecology. It was developed by Paul Jaccard as a measure of similarity of plant distribution in different regions.
The measure can be used in a number of fields, as shown by the following examples. The role of object and attribute can also be reversed, and the first application demonstrates this duality.
Ecology (5)
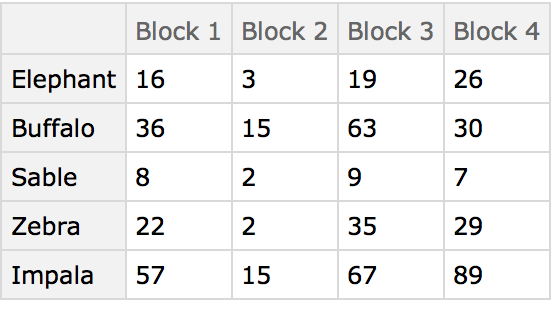
Here are some ground-based animal index counts:
Here the different blocks (habitats) are compared using the animals present as characters. The arrangement of the table in this manner originated in the field of psychology and was later adopted by numerical taxonomy.
The MultisetJaccardDissimilarity distance matrix of the blocks:
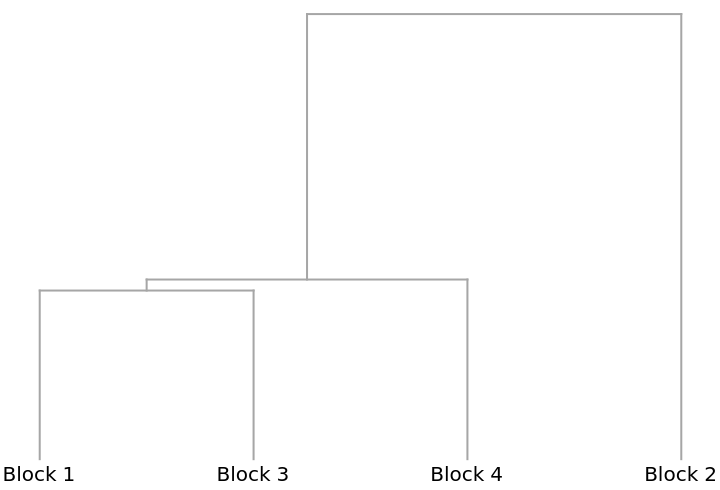
A Dendrogram showing how the blocks cluster:
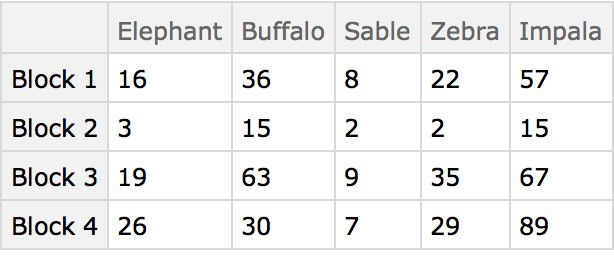
The preceding analysis that compares the columns of the table is known as a Q-type (deriving from early factor analysis studies in the area of psychology). Conversely, comparing the rows is known as an R-type analysis and in this case compares the animals. Begin by first transposing the data table:
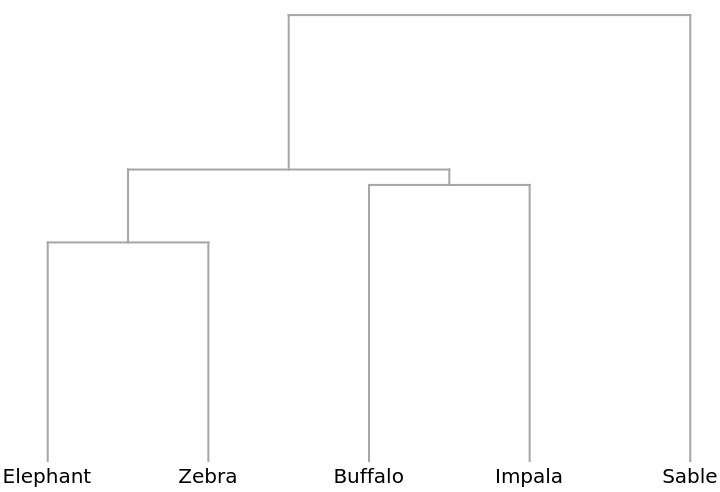
A Dendrogram shows that elephants and zebras, for example, are distributed similarly:
Sociology (6)
This example compares households on a single city block using the composition of household members (head, wife, daughter, brother-in-law, etc.). The data was compiled from the 1920 US Census for the 300 block of Wyoming Ave., Buffalo, NY. The households are labeled by street number.
Load the data:
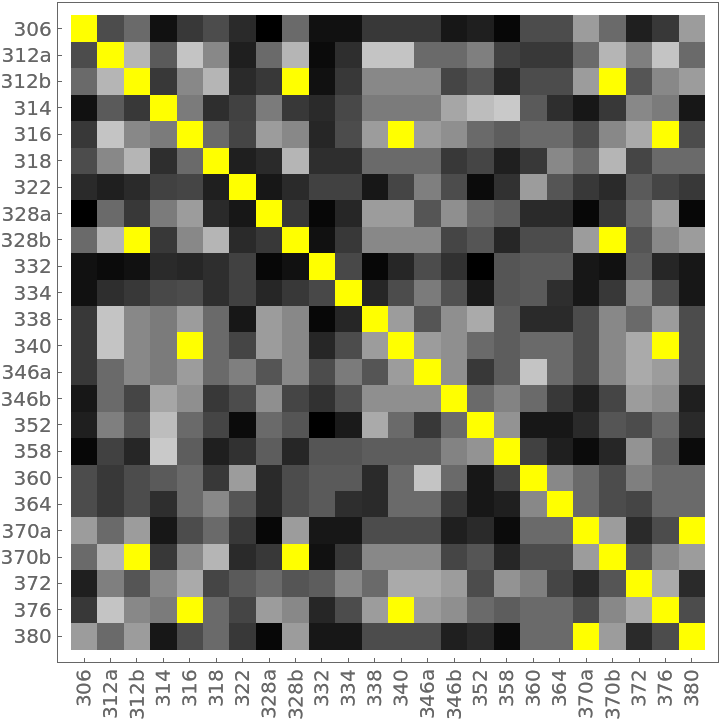
The distance matrix using MultisetJaccardDissimilarity can be displayed with an ArrayPlot (note the presence of off-diagonal 0s colored yellow):
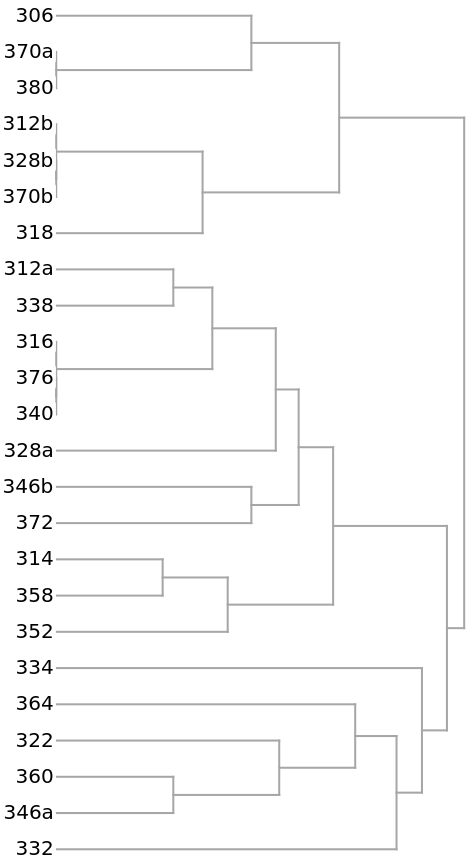
The clustering of the households as shown by a Dendrogram:
The 14 yellow-colored, off-diagonal 0s of the preceding distance matrix represent pairs of identical households. They also appear in the preceding dendrogram as leaves with no initial height. Here they are extracted as clusters:
Mapping back to the original household data gives:
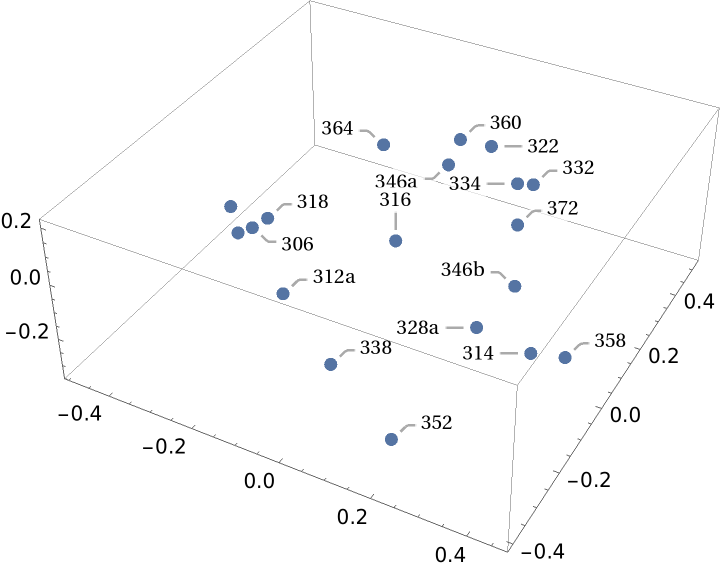
Because the MultisetJaccardDissimilarity is a distance metric, the distance matrix can be used to generate a set of 3D coordinates with distance geometry methods:
Economics (3)
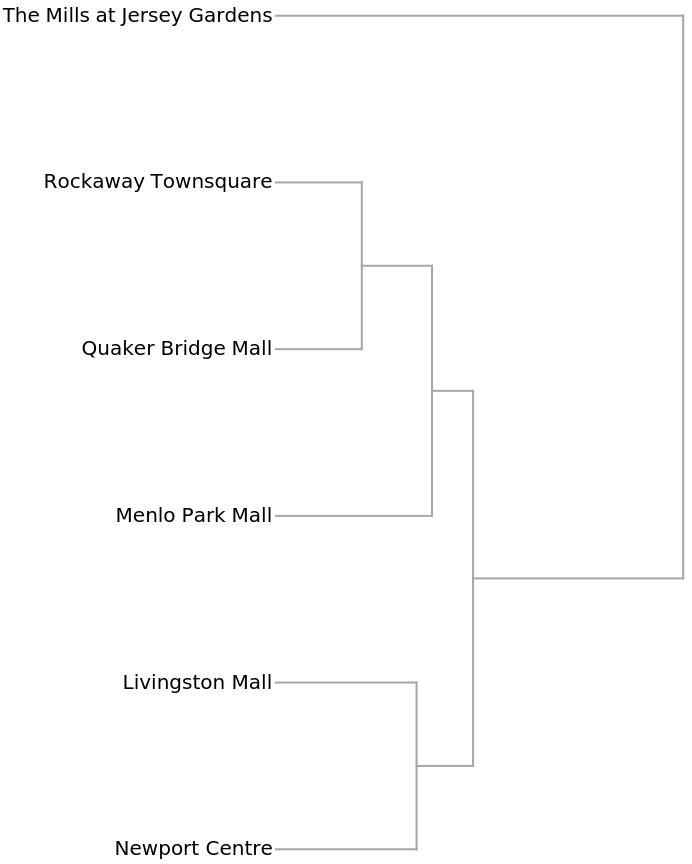
Understanding market forces and characteristics of the competition are essential components of profitable business decisions. This example shows how shopping malls might be compared using the numbers of kinds of businesses in each. The data was collected from the websites of each mall using the self-reported number of businesses in each category. These malls are all managed by the same organization, so the categories can be assumed to be consistent.
Load the data:
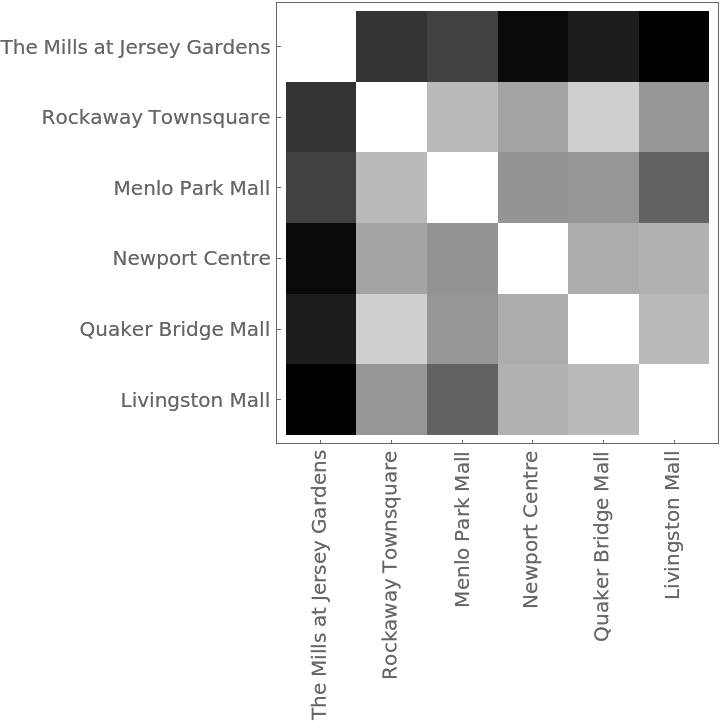
The distance matrix using MultisetJaccardDissimilarity can be displayed with an ArrayPlot:
The Dendrogram shows that The Mills at Jersey Gardens is very different from the others:
Chemistry (5)
Similarity analysis of chemical structures goes back to the original work of Carhart et al. at Lederle Laboratories. It is used extensively to search though chemical databases to find compounds of interest and to cluster chemical structures into similar groups.
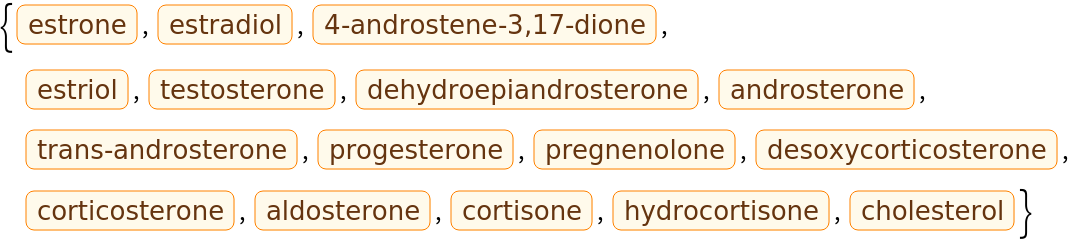
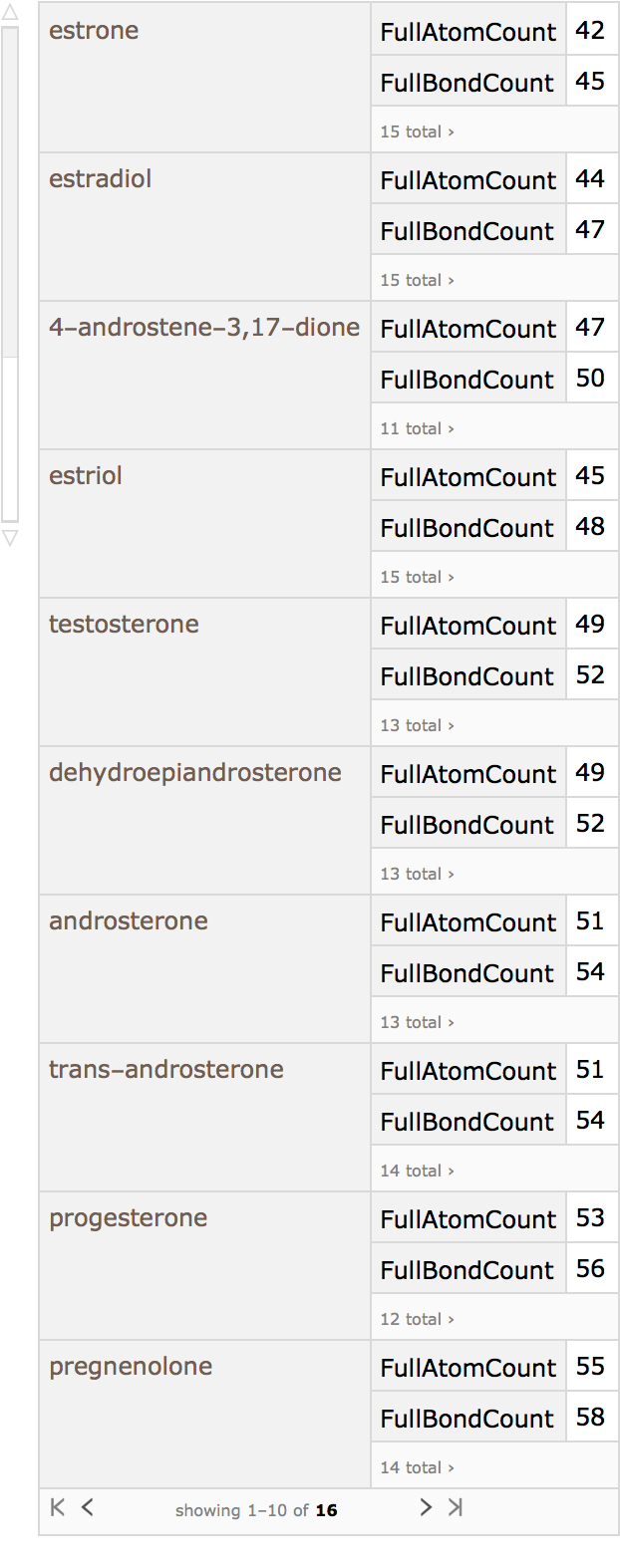
Here is small set of entities from the ChemicalData collection:
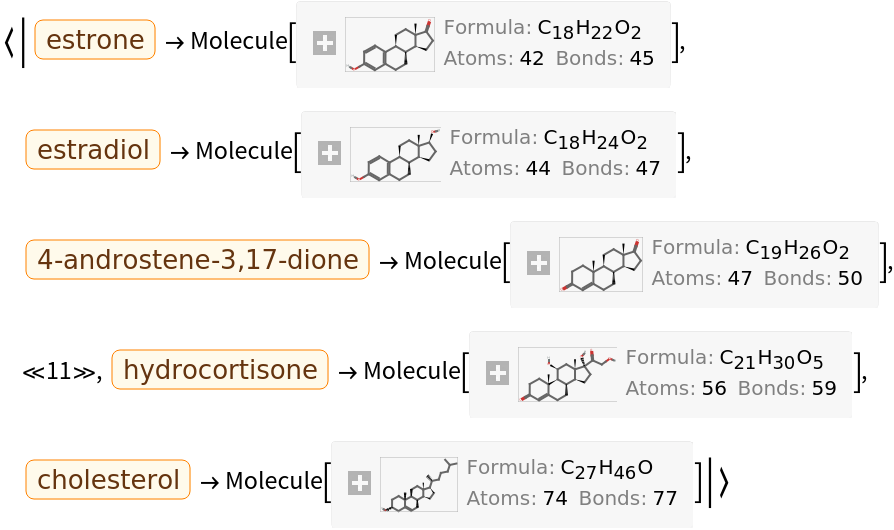
They can be converted into computable Molecule objects:
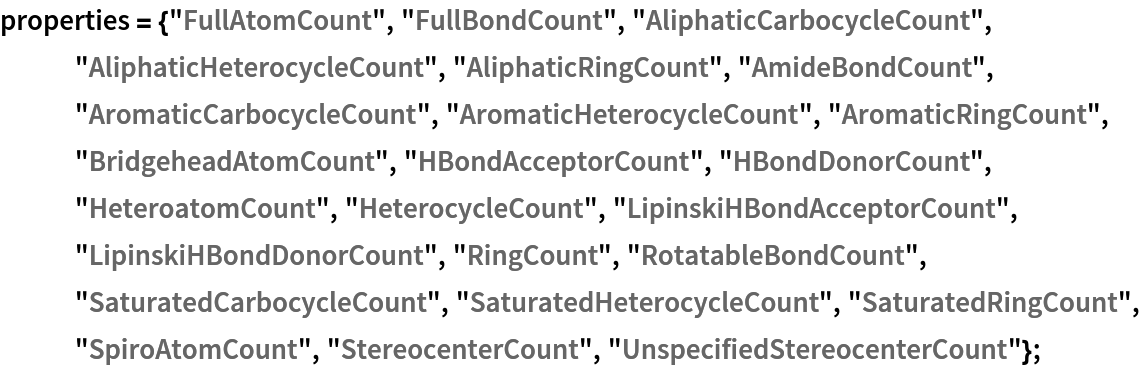
These are the topological features that will characterize each chemical structure (they are not the same as those used by Carhart et al., but are easily computable with MoleculeValue):
Using Dataset, a searchable database can be made:
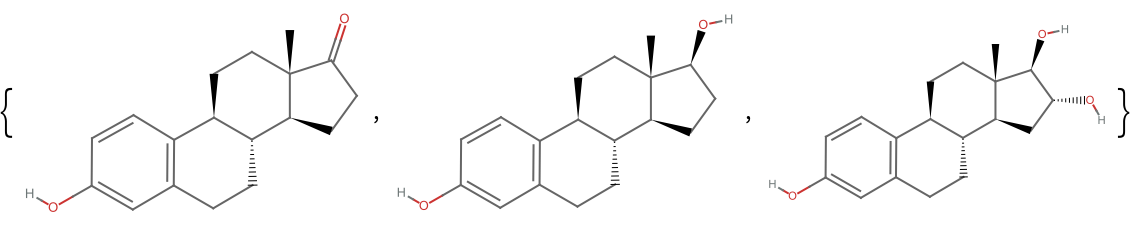
Estradiol, for example, can be taken as the query molecule:
Properties and Relations (3)
Jaccard multiset dissimilarity is bounded by 0 and 1:
The result is the same as JaccardDissimilarity when the multisets are sets:
The MultisetJaccardDissimilarity is a true distance measure, as it does obey the triangle inequality:
The same is true for JaccardDissimilarity:

![DistanceMatrix[Values@Transpose@blockData, DistanceFunction -> ResourceFunction[
"MultisetJaccardDissimilarity"]] // Row[{MatrixForm@#, MatrixForm@N@#}, Spacer[18]] &](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/7480723e3d3a8c3e.png)

![Dendrogram[Normal@Transpose@speciesData, DistanceFunction -> ResourceFunction["MultisetJaccardDissimilarity"]]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/4e350a7df8f673de.png)
![With[{labels = Keys@data}, (\[ScriptCapitalD] = DistanceMatrix[Values@data, DistanceFunction -> ResourceFunction[
"MultisetJaccardDissimilarity"]]) // ArrayPlot[#, FrameTicks -> {Thread[{Range@Length@labels, labels}], Thread[{Range@Length@labels, Rotate[#, 90 °] & /@ labels}]}, ColorRules -> {0 -> Yellow}] &]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/77cdcbf77bdcd714.png)
![Dendrogram[Association@data, Right, DistanceFunction -> ResourceFunction["MultisetJaccardDissimilarity"],
ClusterDissimilarityFunction -> "Average"]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/5b8ee33d6dd1790b.png)
![clusters = ClusteringTree[data, 0, DistanceFunction -> ResourceFunction[
"MultisetJaccardDissimilarity"], ClusterDissimilarityFunction -> "Average"] // PropertyValue[#, "LeafLabels"] &;](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/7ca9fc16ada144eb.png)

![coords = Module[{d = N@\[ScriptCapitalD], n, dSqr, sumSqr, c, g, vals, vec, nDim = 3},
n = Length@d;
dSqr = d^2;
sumSqr = Map[Total, LowerTriangularize[dSqr], {0, 1}];
c = ConstantArray[Mean[dSqr] - sumSqr/n^2, n];
g = (Transpose[c] + c - dSqr)/2;
{vals, vecs} = Eigensystem[g];
Transpose[
DiagonalMatrix[Take[Sqrt[Abs[vals]], nDim]] . Take[vecs, nDim]]
];](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/2d4ed4dabaf22acb.png)

![With[{labels = Normal@Keys@Transpose@data}, DistanceMatrix[Values@Transpose@data, DistanceFunction -> ResourceFunction[
"MultisetJaccardDissimilarity"]] // ArrayPlot[#, FrameTicks -> {Thread[{Range@Length@labels, labels}], Thread[{Range@Length@labels, Rotate[#, 90 °] & /@ labels}]}] &]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/61e7e5de492d2568.png)
![Dendrogram[Normal@Transpose@data, Right, DistanceFunction -> ResourceFunction["MultisetJaccardDissimilarity"],
ClusterDissimilarityFunction -> "Average"]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/191ba0368525be69.png)
![database = Dataset@(DeleteCases[#, 0] &@
AssociationThread[
properties -> MoleculeValue[#, properties]] & /@ mols)](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/4c7d36a39721bd90.png)
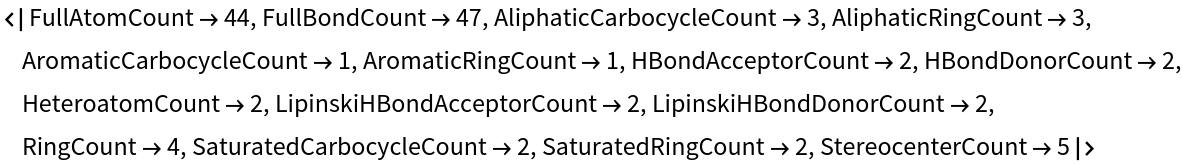
![U = {"a"};
V = {"b"};
W = {"a", "b"};
ResourceFunction["MultisetJaccardDissimilarity"][U, V] <= ResourceFunction["MultisetJaccardDissimilarity"][U, W] + ResourceFunction["MultisetJaccardDissimilarity"][V, W]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/01a4ce3e9b8ae04a.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/c7dc5555-76be-4fed-8d18-e6aae767bfc4"]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/288481a88d3603eb.png)
![u = {1, 0};
v = {0, 1};
w = {1, 1};
JaccardDissimilarity[u, v] <= JaccardDissimilarity[u, w] + JaccardDissimilarity[v, w]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/2ac2a0caa3c9bdbb.png)
![u = RandomInteger[1, 10] // Echo;
v = RandomInteger[1, 10] // Echo;
w = RandomInteger[1, 10] // Echo;
JaccardDissimilarity[u, v] <= JaccardDissimilarity[u, w] + JaccardDissimilarity[v, w]](https://www.wolframcloud.com/obj/resourcesystem/images/9e3/9e3fe5a9-25a9-4464-8be9-c8a1f7f631a1/65e02d3f3eb383b1.png)