Details
A merge-find set is a data structure that contains disjoint subsets of a master set indexed by integers 1…n. It supports both fast finding of canonical subset elements and fast merging of subsets.
A merge-find set is also called a disjoint-set or a union-find set.
Merge-find sets are used in graph partitioning algorithms to keep track of unconnected components as they are merged. One such application is in efficient implementations of Kruskal's minimum spanning tree algorithm.
ResourceFunction["MergeFindSet"] only works with explicit indices 1…n. A more general one can handle arbitrary set elements, though at the expense of speed and memory requirements.
The initialization can specify either a positive integer
n or a disjoint partition of
Range[n]. In the former case, the initial subsets are singletons containing the individual integers from 1 to
n.
Each subset in a merge-find set has a canonical leader element. Elements that are not leaders have parents.
A leader for a given element is located by following the parent path beginning at that element. A leader is its own parent and this gives a termination condition for locating an elements leader.
A merge-set with n elements is comprised of n pairs of integers. The kth element is {pk,sk}, where pk is the parent of k. When k is its own parent, sk gives the total size of its subset; it is not used in other cases.
In "Merge" operations, smaller subsets are merged into larger.
Whenever a "Find" is performed, elements in the parent path that do not point directly to the leader will be changed to point directly to it.
ResourceFunction["MergeFindSet"] with one argument will automatically assume the operation is "Initialize".
ResourceFunction["MergeFindSet"][mfs,j] for integer j will automatically assume the operation is "Find".
ResourceFunction["MergeFindSet"][mfs,j,k] for integers j and k will automatically assume the operation is "Merge".
The "Find" operation will thread over its second argument.
ResourceFunction["MergeFindSet"] has the attribure
HoldFirst.
![ResourceFunction["MergeFindSet"][mfs, 4, 5, "Merge"];
ResourceFunction["MergeFindSet"][mfs, 2, 5, "Merge"];
mfs](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/7611cee8c9a187ad.png)
![BlockRandom[SeedRandom[123456];
mfs = ResourceFunction["MergeFindSet"][
Partition[RandomSample[Range@20], 5], "Initialize"]]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/74fa54f2c9122b8b.png)
![n = 15;
msf = ResourceFunction["MergeFindSet"][2^n, "Initialize"];
Timing[Do[
ResourceFunction["MergeFindSet"][msf, i, i + 2^m - 1, "Merge"], {m,
1, n}, {i, 1, 2^n - 1, 2^m}];]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/2acabb7985b4bb64.png)
![n += 1;
msf = ResourceFunction["MergeFindSet"][2^n, "Initialize"];
Timing[Do[
ResourceFunction["MergeFindSet"][msf, i, i + 2^m - 1, "Merge"], {m,
1, n}, {i, 1, 2^n - 1, 2^m}];]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/08eb8b3e820cb96d.png)
![n += 1;
msf = ResourceFunction["MergeFindSet"][2^n, "Initialize"];
Timing[Do[
ResourceFunction["MergeFindSet"][msf, i, i + 2^m - 1, "Merge"], {m,
1, n}, {i, 1, 2^n - 1, 2^m}];]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/5ad19e04e42cfc38.png)
![msf = ResourceFunction["MergeFindSet"][2^n, "Initialize"];
Timing[Do[
ResourceFunction["MergeFindSet"][msf, 1, i, "Merge"], {i, 2, 2^n}];]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/5186d988641e74a6.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/e68fae57-0257-4253-9e5f-e896a88bf6e3"]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/6fb4c1ed28a9343a.png)
![BlockRandom[SeedRandom[1234];
nverts = 200;
ListPlot[pts = RandomReal[{-10, 10}, {nverts, 2}], AspectRatio -> Automatic]]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/3c948b79cf055bb5.png)

![nverts = 400;
pts = RandomReal[{-10, 10}, {nverts, 2}];
Timing[{tdist, treegraph} = Kruskal[pts];]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/0e1ad55234457715.png)
![edges = Flatten[
Table[UndirectedEdge[i, j], {i, nverts - 1}, {j, i + 1, nverts}]];
edgeweights = Flatten[Table[
EuclideanDistance[pts[[i]], pts[[j]]], {i, nverts - 1}, {j, i + 1,
nverts}]];
gr = Graph[Range[nverts], edges, EdgeWeight -> edgeweights, VertexCoordinates -> pts];
Timing[msk = FindSpanningTree[gr, Method -> "Kruskal"]]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/086f8a201c3db529.png)
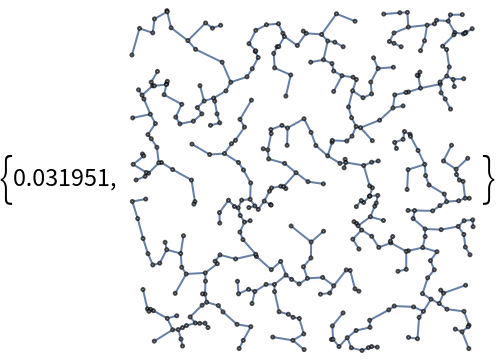
![Table[nverts = 2^n;
pts = RandomReal[{-10, 10}, {nverts, 2}];
t1 = First[Timing[{tdist, treegraph} = Kruskal[pts]]];
edges = Flatten[
Table[UndirectedEdge[i, j], {i, nverts - 1}, {j, i + 1, nverts}]];
edgeweights = Flatten[Table[
EuclideanDistance[pts[[i]], pts[[j]]], {i, nverts - 1}, {j, i + 1,
nverts}]];
gr = Graph[Range[nverts], edges, EdgeWeight -> edgeweights, VertexCoordinates -> pts];
t2 = First[Timing[msp = FindSpanningTree[gr, Method -> "Kruskal"]]];
{t1/t2},
{n, 7, 11}]](https://www.wolframcloud.com/obj/resourcesystem/images/5e3/5e348946-57f8-4a4f-80b8-f911d9af2dad/05fffbd9622520cf.png)