Wolfram Function Repository
Instant-use add-on functions for the Wolfram Language
Function Repository Resource:
Find the longest common contiguous prefix of a set of strings or lists
ResourceFunction["LongestCommonPrefix"][{"str1","str2",…}] gives the longest string "pre" such that StringStartsQ["stri","pre"] for all of the "stri". | |
ResourceFunction["LongestCommonPrefix"][{list1,list2,…}] gives the longest list {e1,…,en} such that Take[listi,n]==={e1,…,en} for all of the listi. | |
ResourceFunction["LongestCommonPrefix"][a1,a2,…] is equivalent to ResourceFunction["LongestCommonPrefix"][{a1,a2,…}]. |
| IgnoreCase | False | whether to ignore case of letters in strings |
| Method | Automatic | algorithm to be used |
| "LinearSearch" | check sequences one element at a time starting from the left |
| "BinarySearch" | recursively check from the middle of each sequence |
Get the longest common prefix of strings:
| In[1]:= |
| Out[1]= |
| In[2]:= |
| Out[2]= |
Get the longest common prefix of lists:
| In[3]:= |
| Out[3]= |
| In[4]:= |
| Out[4]= |
| In[5]:= |
| Out[5]= |
Multiple arguments will be interpreted as a list:
| In[6]:= |
| Out[6]= |
| In[7]:= |
| Out[7]= |
If given an Association, LongestCommonPrefix uses the values:
| In[8]:= |
| Out[8]= |
By default, LongestCommonPrefix is case sensitive for strings:
| In[9]:= |
| Out[9]= |
Set IgnoreCase→True to treat uppercase and lowercase letters as equivalent:
| In[10]:= |
| Out[10]= |
When ignoring case, the result will match the case of the first string:
| In[11]:= |
| Out[11]= |
| In[12]:= |
| Out[12]= |
| In[13]:= |
| Out[13]= |
Specify that a linear search algorithm should be used:
| In[14]:= |
| Out[14]= |
Use a binary search:
| In[15]:= |
| Out[15]= |
Choose a search algorithm automatically:
| In[16]:= |
| Out[16]= |
If prefixes are likely to be very short relative to the sequence length, a linear search can be a little faster:
| In[17]:= |
| Out[17]= |
| In[18]:= |
| Out[18]= |
| In[19]:= |
| Out[19]= |
Using Automatic resorts to a linear search in this case:
| In[20]:= |
| Out[20]= |
The worse-case performance of a linear search is much worse than a binary search however:
| In[21]:= |
| Out[18]= |
| In[22]:= |
| Out[22]= |
| In[23]:= |
| Out[23]= |
Using Automatic resorts to a binary search in this case:
| In[24]:= |
| Out[24]= |
Find the common root directory for a list of files:
| In[25]:= |
| Out[25]= | 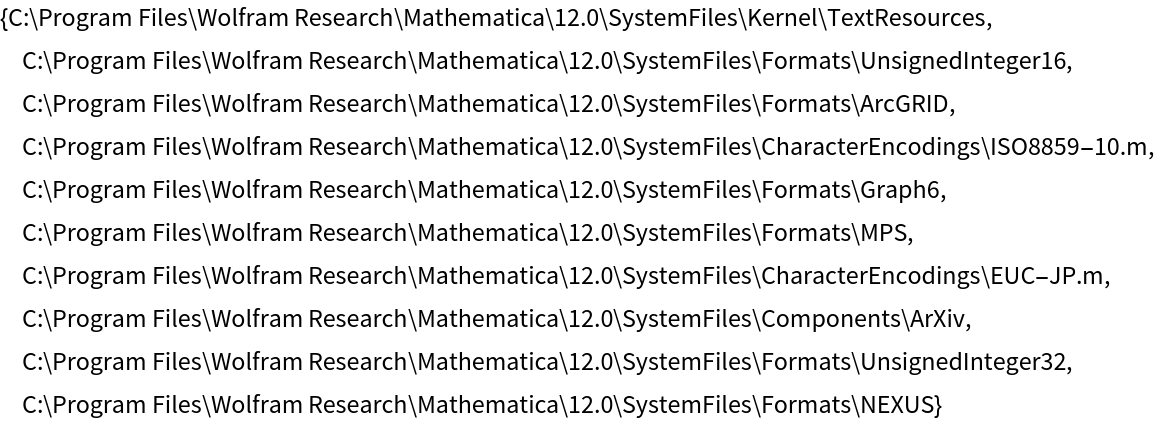 |
| In[26]:= |
| Out[26]= |
Show relative file names:
| In[27]:= |
| Out[27]= |  |
Find the common parent directory for a list of cloud objects:
| In[28]:= |
| Out[28]= |
| In[29]:= |
| Out[29]= |
For a single string or list, the longest common prefix is simply itself:
| In[30]:= |
| Out[30]= |
| In[31]:= |
| Out[31]= |
For strings, an empty string is returned if no prefix is found:
| In[32]:= |
| Out[32]= |
| In[33]:= |
| Out[33]= |
For lists, an empty list is returned if no prefix is found:
| In[34]:= |
| Out[34]= |
If an empty string appears in the list of strings, the output will always be an empty string:
| In[35]:= |
| Out[35]= |
If an empty list appears in the list of lists, the output will always be an empty list:
| In[36]:= |
| Out[36]= |
LongestCommonPrefix is similar to LongestCommonSubsequence:
| In[37]:= |
| Out[37]= |
| In[38]:= |
| Out[38]= |
However, LongestCommonPrefix only checks subsequences at the beginning of each list:
| In[39]:= |
| Out[39]= |
| In[40]:= |
| Out[40]= |
Lists and strings cannot be mixed:
| In[41]:= |
| Out[41]= |
Since LongestCommonPrefix can return a list or string depending on the input, at least one element must be given to resolve ambiguity:
| In[42]:= |
| Out[42]= |
| In[43]:= |
| Out[43]= |
| In[44]:= |
| Out[44]= |
When setting the option IgnoreCase to True, the order of items can affect the result:
| In[45]:= |
| Out[45]= |
| In[46]:= |
| Out[46]= |
The IgnoreCase option has no effect when comparing lists:
| In[47]:= |
| Out[47]= |
| In[48]:= |
| Out[48]= |
Find the lengths of longest common prefixes in random binary sequences of length 100:
| In[49]:= |
| Out[49]= | 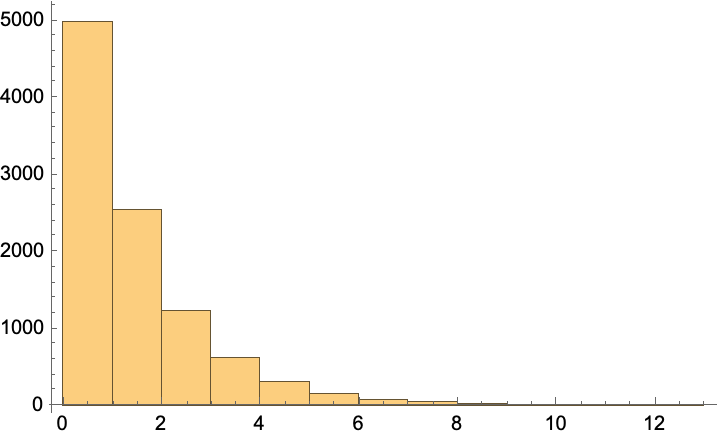 |
Compare distributions to LongestCommonSequence and LongestCommonSubsequence:
| In[50]:= | ![ints = RandomInteger[1, {10000, 2, 100}];
Table[Labeled[Histogram[Length /@ f @@@ ints], ToString[f]], {f, {LongestCommonSequence, LongestCommonSubsequence, ResourceFunction["LongestCommonPrefix"]}}]](https://www.wolframcloud.com/obj/resourcesystem/images/224/224746a4-9f7b-4829-a18e-a9824153dbe9/414eab4319c05c78.png) |
| Out[51]= | 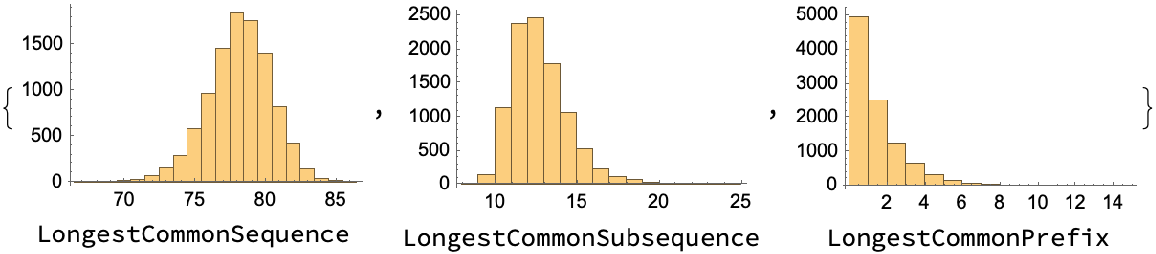 |
Find words that share a prefix with "BirdSay":
| In[52]:= | ![Select[WordList["KnownWords", IncludeInflections -> True], StringLength[
ResourceFunction["LongestCommonPrefix"]["BirdSay", #, IgnoreCase -> True]] >= 4 &]](https://www.wolframcloud.com/obj/resourcesystem/images/224/224746a4-9f7b-4829-a18e-a9824153dbe9/74e51dc2170ea8da.png) |
| Out[52]= |  |
BirdSay the results:
| In[53]:= |
| Out[53]= |  |
This work is licensed under a Creative Commons Attribution 4.0 International License