Basic Examples (4)
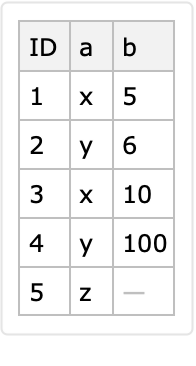
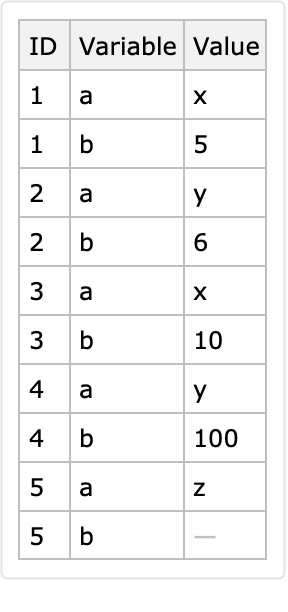
Here is a simple dataset:
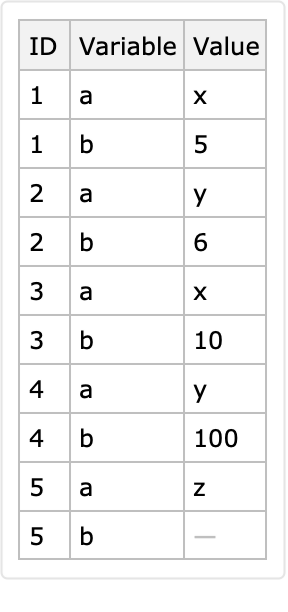
Here is a long form conversion with a specified identifier column and variable columns:
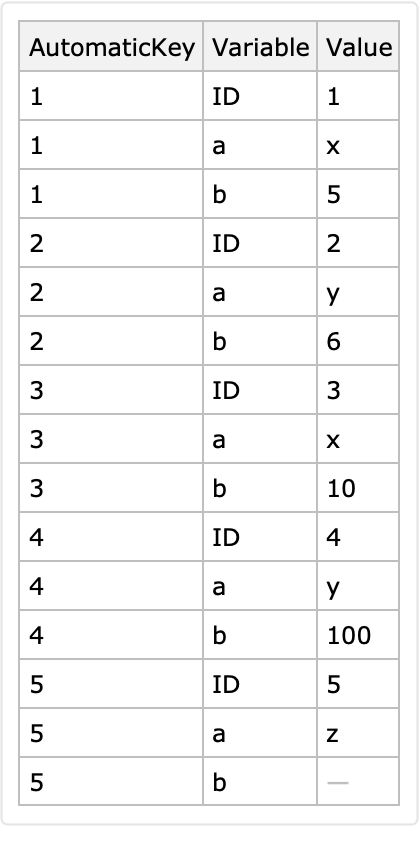
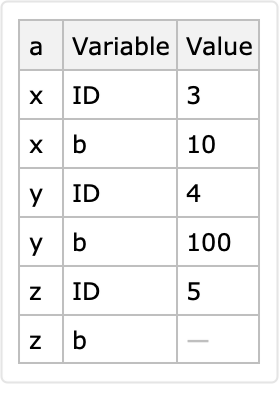
Here is another long form derived with an automatically determined identifier column and variable columns:
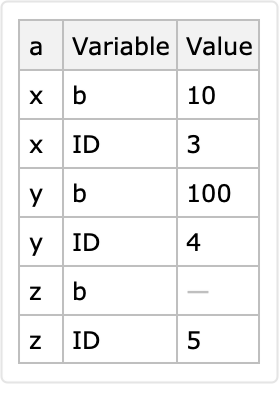
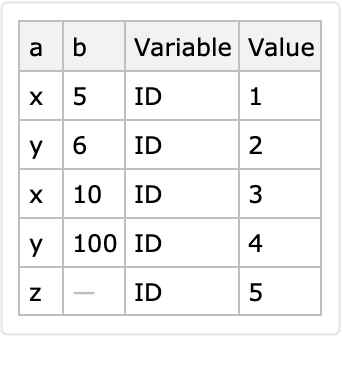
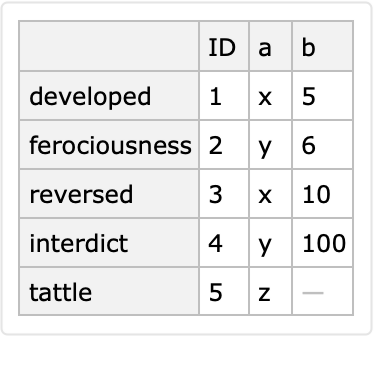
Here is a conversion to long form with identifier columns "a" and "b":
Scope (5)
The first argument can be a matrix:
The first argument can be a list of associations:
The second and third arguments can be Automatic:
The options "IdentifierColumns" and "VariableColumns" can be used instead of a second argument and third argument respectively:
The second and third arguments can be column indexes:
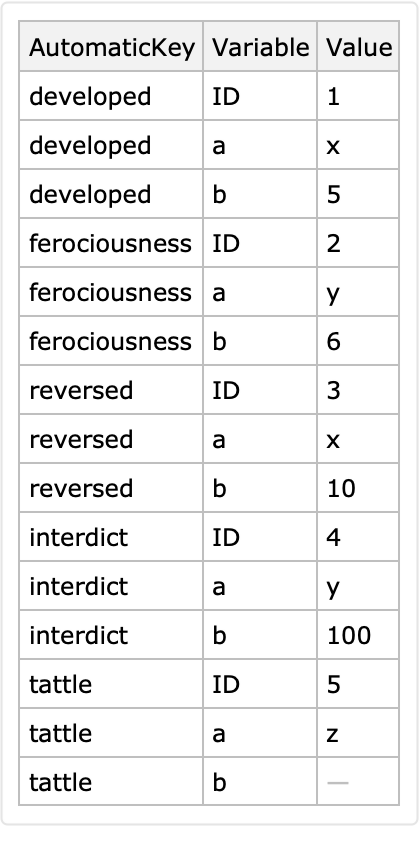
Automatic keys are derived if the dataset argument has row keys:
Here is an automatic conversion to long form:
The row keys are ignored if the identifier column is specified:
Options (3)
AutomaticKeysTo (1)
The option "AutomaticKeysTo" can be used to specify the name of the column that corresponds to the automatically determined identifier:
VariablesTo (1)
The option "VariablesTo" specifies the name of long form's column that has, as values, the names of the variable columns:
ValuesTo (1)
The option "ValuesTo" specifies the name of the column that has the values in the variable columns:
Applications (9)
Column names as data (5)
The main advantage of the long form conversion is that variable column names become data, that is, values in a certain column. This can be demonstrated by making an association of time series objects for the rows of multiple time series data given in wide form.
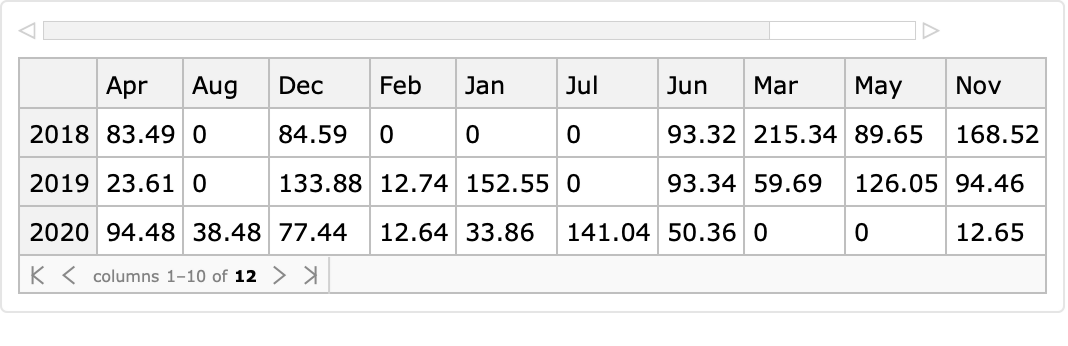
Here is a randomly generated table (dataset) with multiple time series data:
Each row of that random time series dataset corresponds to a yearly sequence of monthly values. The interpretation of the dataset reveals heterogeneous semantics of its values: (1) each row corresponds to a year specified as a key and (2) the columns have short month names.
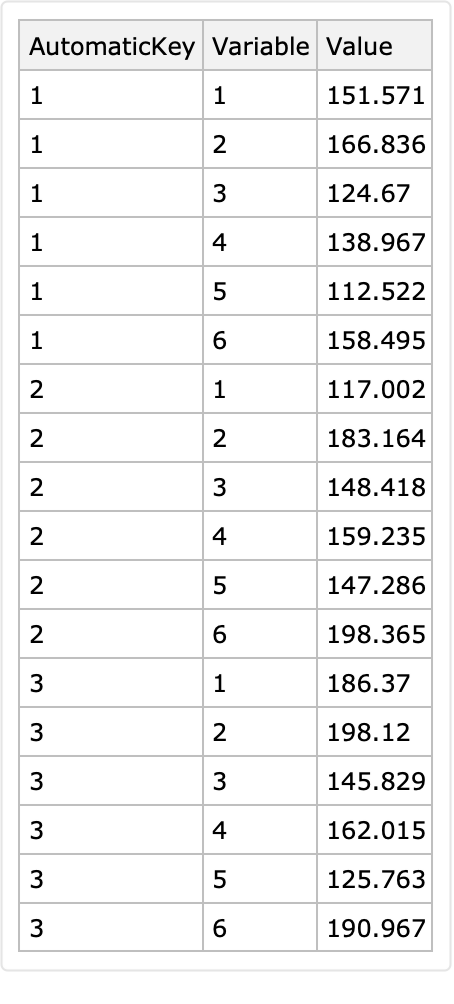
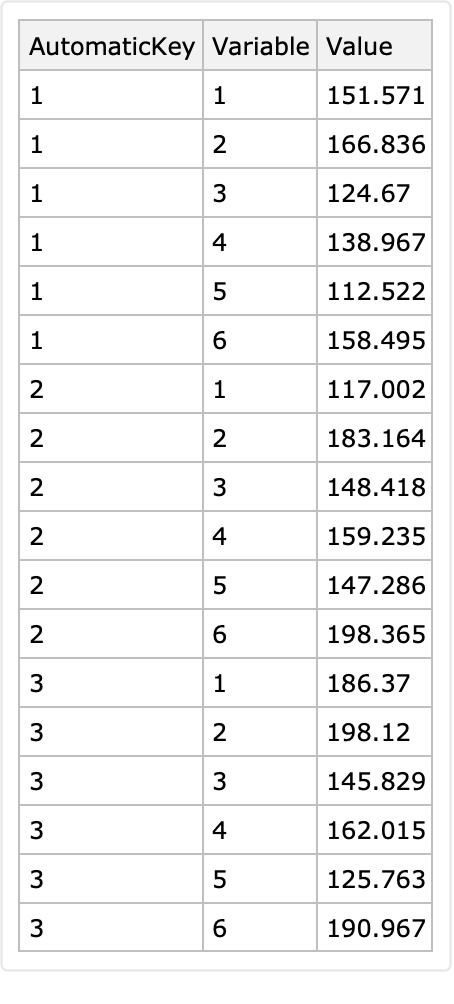
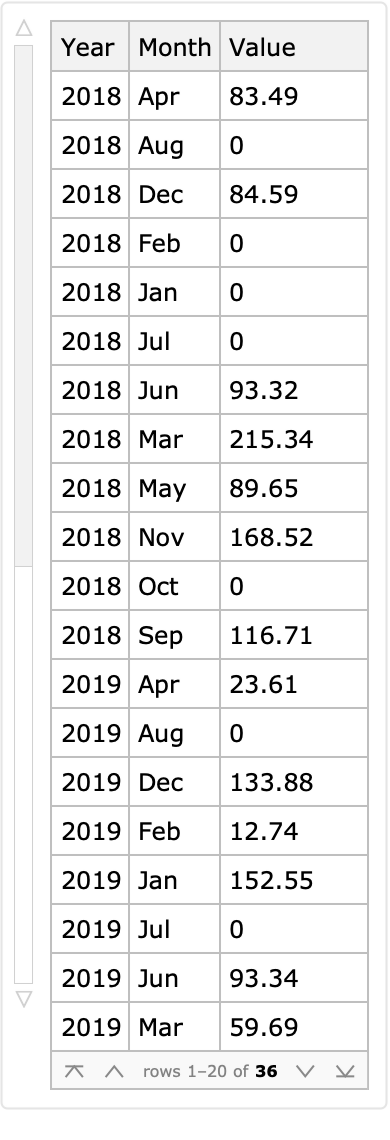
Convert the dataset into long form using the row keys as identifiers:
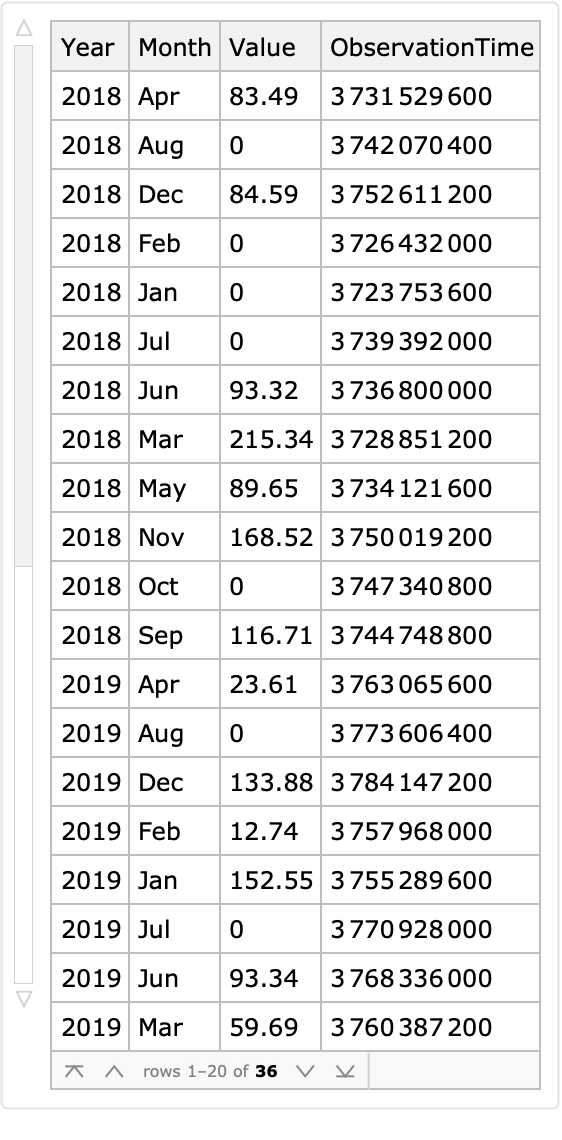
Add the column "ObservationTime" derived from the columns "Year" and "Month":
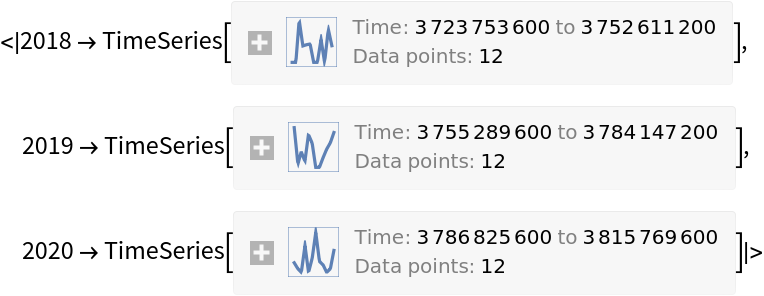
Split the long form dataset by year and make time series with the columns "ObservationTime" and "Value":
Plot the obtained time series:
Combinations of the heterogenous data (4)
Using long forms simplifies the programmatic manipulation of heterogenous data.
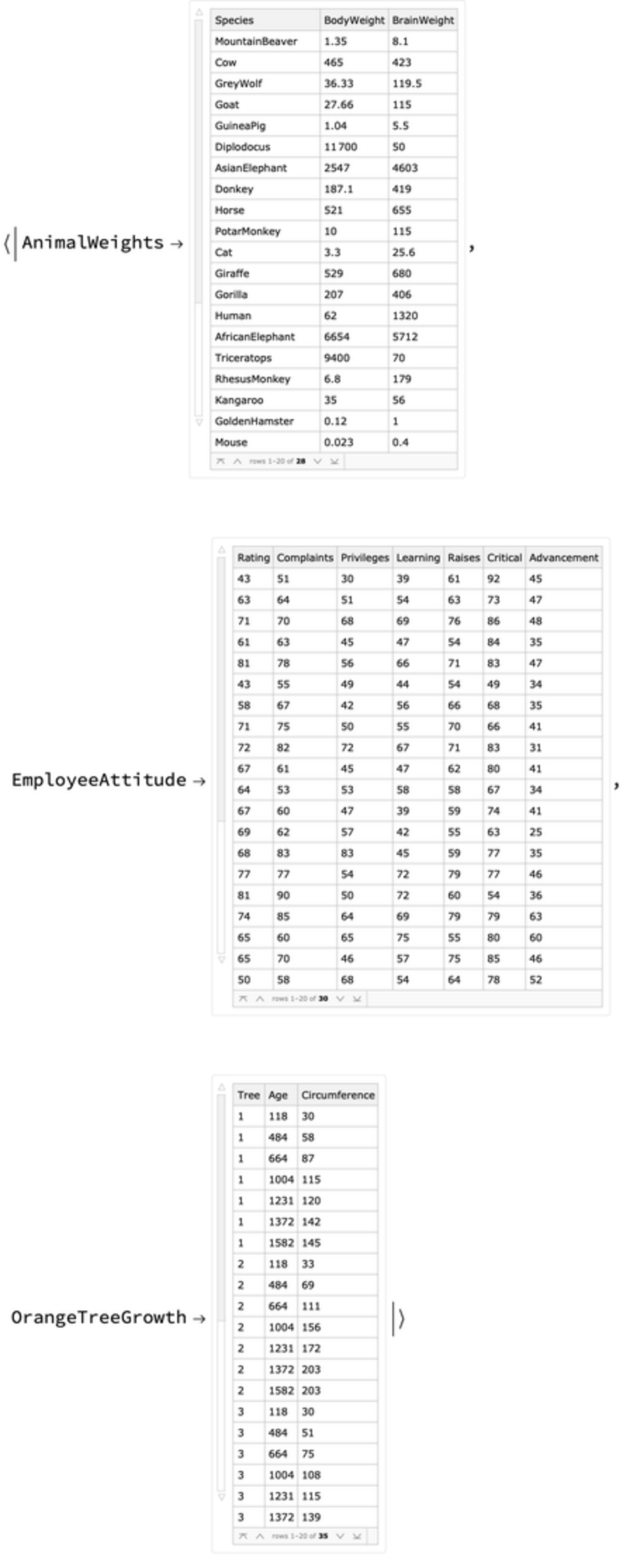
Get datasets with different numbers of rows and columns that correspond to items and variables of different kinds:
Convert all datasets into long form datasets:
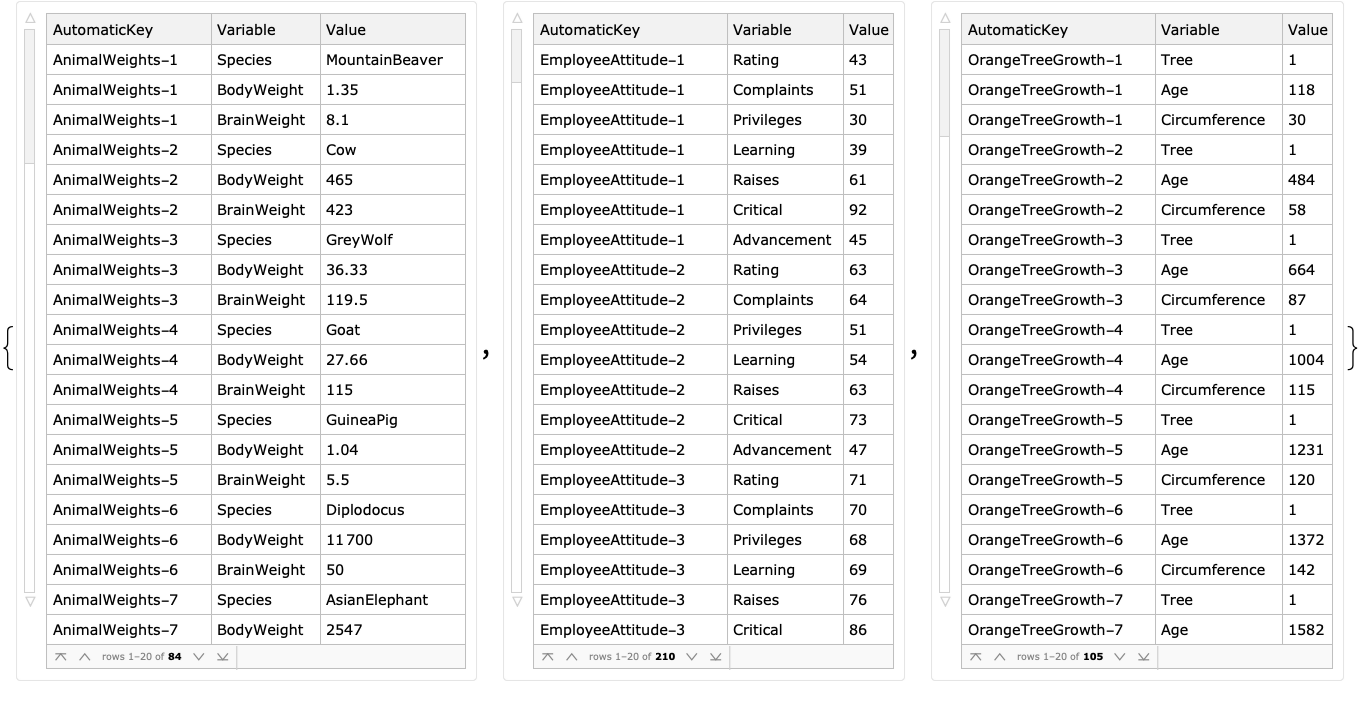
For each long form dataset, change the automatic key column to include the name of that dataset:
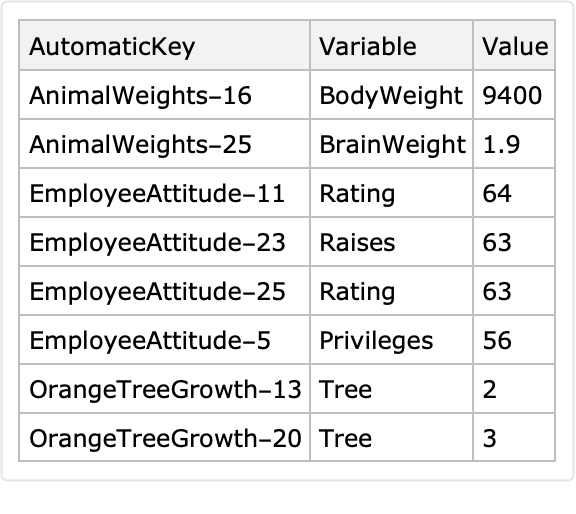
Join all long form datasets into one dataset and show a sample:
Properties and Relations (2)
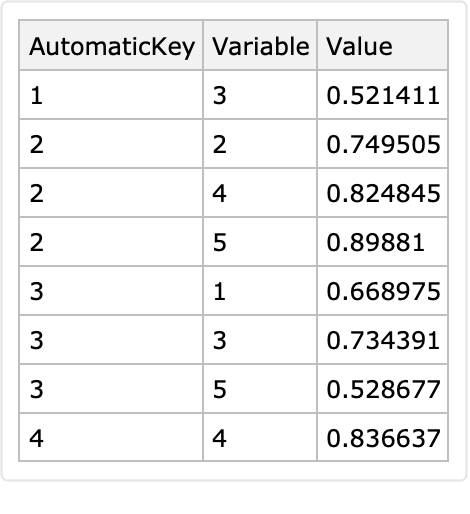
Here is a random sparse matrix:
Compare the array rules of this sparse matrix with its long-form representation:
Here is the long-form representation:
Note that since using Normal on the sparse matrix makes a dense matrix with zeroes, those zeroes are filtered out from the displayed long form.
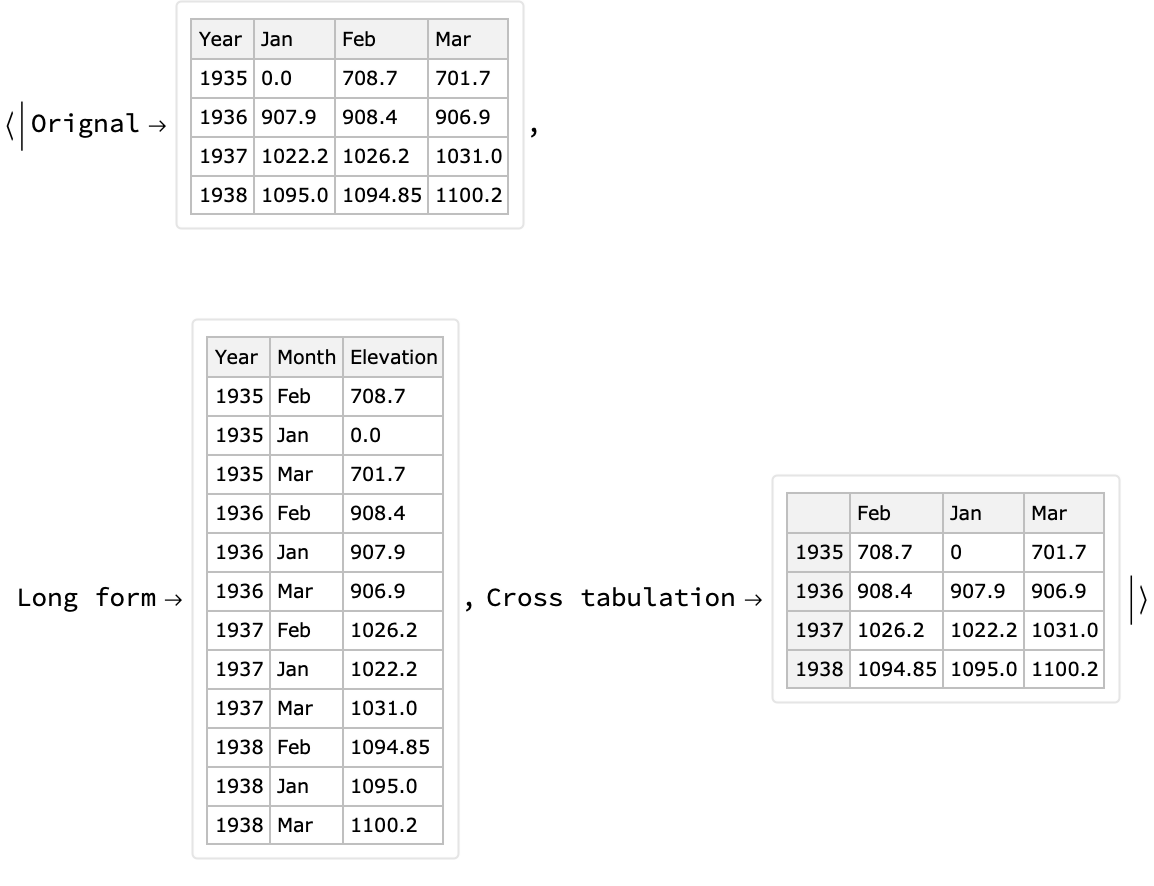
Cross tabulation can be seen under certain conditions as conversion to wide form. Therefore, certain long form conversions can be reverted into the original forms using cross tabulation.
Here is an example using the resource function over a subset of the Lake Mead elevation levels data:
Possible Issues (2)
If the first argument is a dataset without column names, the second and third arguments are expected to consist of column indices.
Here is a correct specification:
Here are some incorrect specifications:
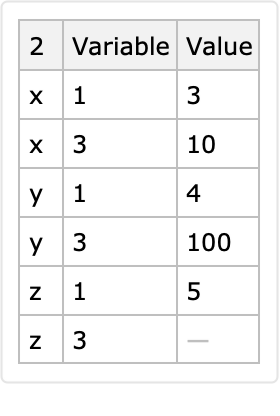
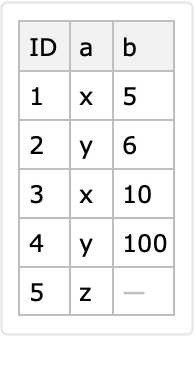
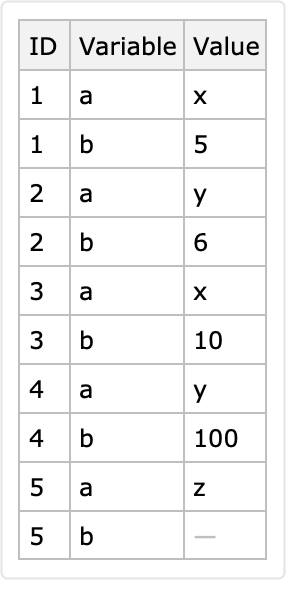
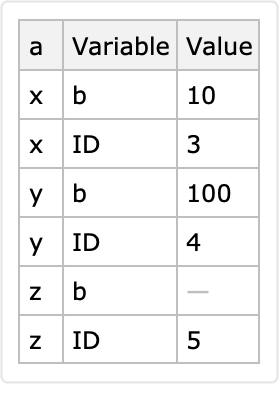
If the identifier columns produce multiple corresponding rows for a given combination of identifier values, then only the last row is put in the long-form result:
The row <|"ID"→1, "a"→ x, "b" → 5|> is lost:
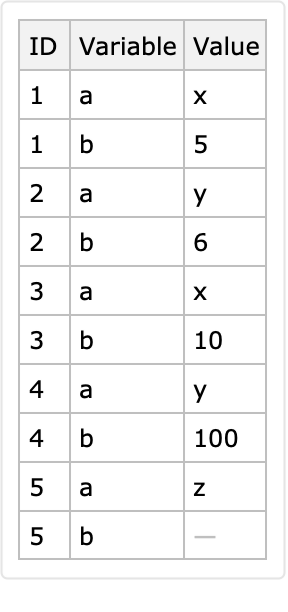
![dataset = Block[{ds, k}, ds = Dataset[{
Association["a" -> "x", "b" -> 5],
Association["a" -> "y", "b" -> 6],
Association["a" -> "x", "b" -> 10],
Association["a" -> "y", "b" -> 100],
Association["a" -> "z", "b" -> Missing[]]}]; k = 1; ds[
All, Prepend[#, "ID" -> Increment[k]]& ]];
ResourceFunction["LongFormDataset"][dataset, "AutomaticKeysTo" -> "SpecialID"]](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/012bf1025cab9202.png)
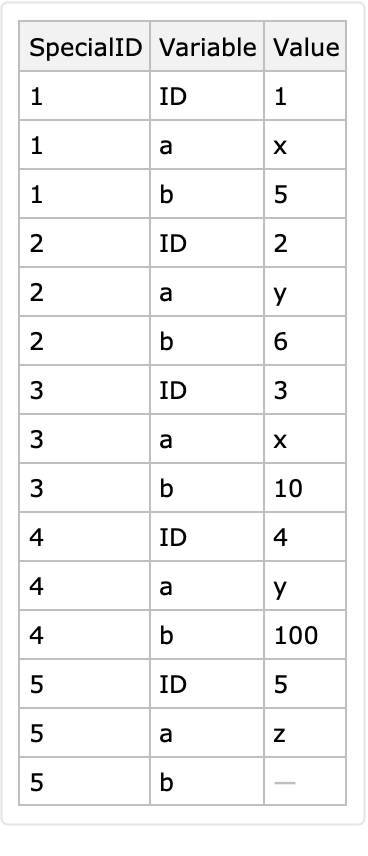
![dataset = Block[{ds, k}, ds = Dataset[{
Association["a" -> "x", "b" -> 5],
Association["a" -> "y", "b" -> 6],
Association["a" -> "x", "b" -> 10],
Association["a" -> "y", "b" -> 100],
Association["a" -> "z", "b" -> Missing[]]}]; k = 1; ds[
All, Prepend[#, "ID" -> Increment[k]]& ]];
ResourceFunction["LongFormDataset"][dataset, "VariablesTo" -> "VAR"]](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/73fd8976c00ce199.png)
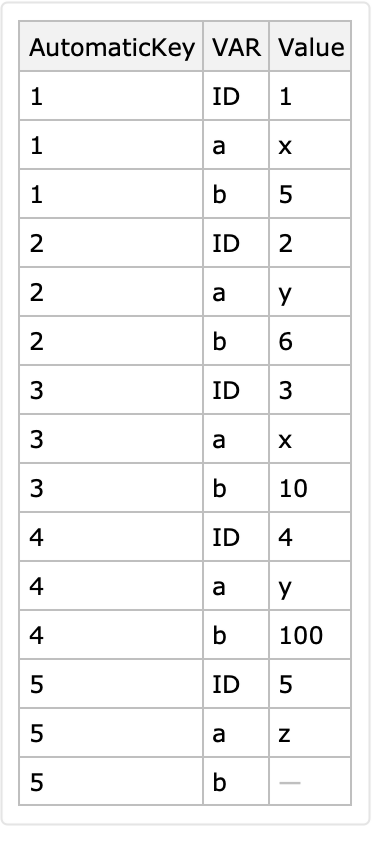
![dataset = Block[{ds, k}, ds = Dataset[{
Association["a" -> "x", "b" -> 5],
Association["a" -> "y", "b" -> 6],
Association["a" -> "x", "b" -> 10],
Association["a" -> "y", "b" -> 100],
Association["a" -> "z", "b" -> Missing[]]}]; k = 1; ds[
All, Prepend[#, "ID" -> Increment[k]]& ]];
ResourceFunction["LongFormDataset"][dataset, "ValuesTo" -> "VAL"]](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/769a292263536089.png)
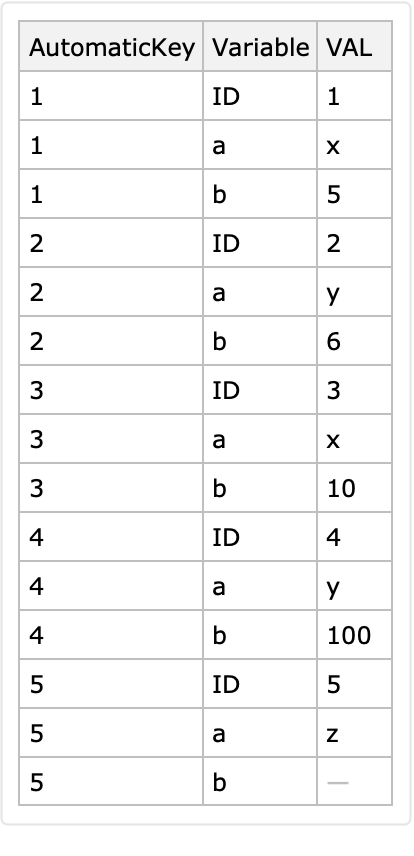
![dsLong = dsLong[All, Join[#, <|"ObservationTime" -> AbsoluteTime[ToString[#Year] <> "-" <> #Month]|>] &]](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/31cf4fe2a822f921.png)

![datasets = Association@
Map[# -> ResourceFunction[
"ExampleDataSpecToDataset"][{"Statistics", #}] &, \
{"AnimalWeights", "EmployeeAttitude", "OrangeTreeGrowth"}];
Magnify[#, 0.6] & /@ datasets](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/3f1c6a5dc8a50441.png)

![datasets = KeyValueMap[
Function[{k, v}, v[All, Prepend[#, "AutomaticKey" -> k <> "-" <> ToString[#AutomaticKey]] &]], datasets];
Magnify[#, 0.6] & /@ datasets](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/2987fc0b1424c2ff.png)
![dsLakeData = ResourceFunction["ExampleDataSpecToDataset"][{"Statistics", "LakeMeadLevels"}][[1 ;; 4, 1 ;; 4]];
dsLong = ResourceFunction["LongFormDataset"][dsLakeData, "Year", "VariablesTo" -> "Month", "ValuesTo" -> "Elevation"];
dsCrossTbl = ResourceFunction["CrossTabulate"][dsLong];](https://www.wolframcloud.com/obj/resourcesystem/images/33b/33b8aa4f-1543-4a74-a984-aacf5ec19bcf/4c18534352530eb2.png)