Basic Examples (2)
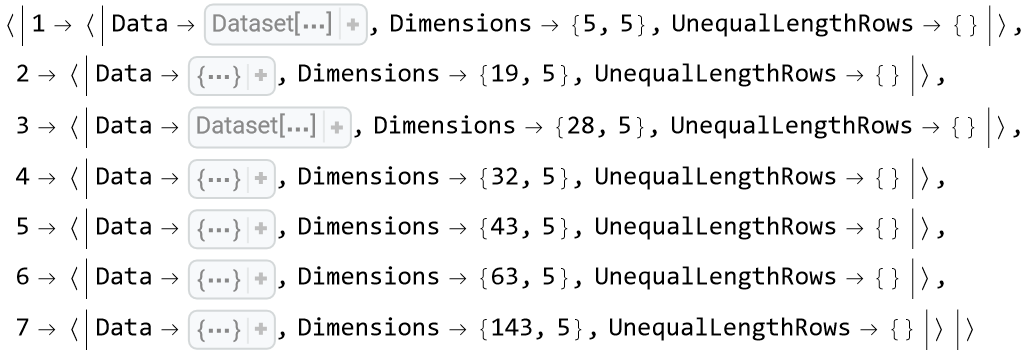
Import the tables available in the Wikipedia page about "List of countries by forest area". By default the result is a list of tables (nested lists) found in this page:
See the size of the tables:
Usually, the scraped values are strings, but if the data contains well formatted numbers they are scraped as numeric types. This shows a TextGrid of the first table:
If the second argument is specified as "IconAssociation", the result is an Association of table data. The tables are iconized as the "Data" element to shorten long outputs:
Tables can be copy–pasted or extracted programmatically (note that the 1 in the third argument of Query is used to get data from the IconizedObject):
Scope (2)
The key "UnequalLengthRows" contains the indexes of rows which have different lengths from the commonest length of the table. In the following, the first table has the first two rows with a different length from the rest of the table:
This information can be useful for fixing or skipping these rows:
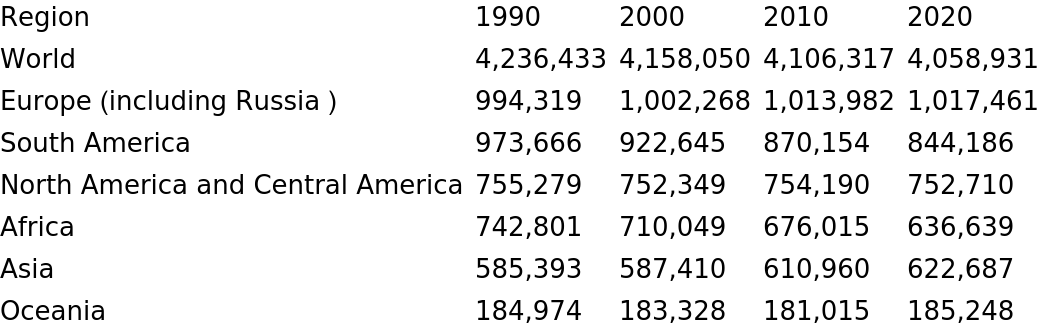
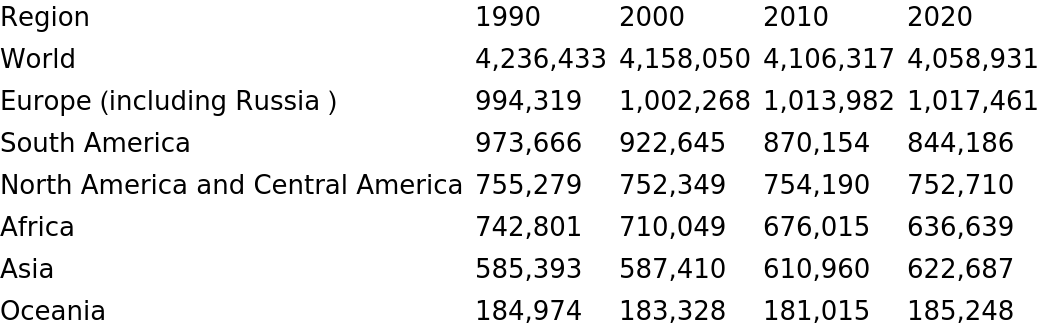
Import tables from a Spanish Wikipedia page:
Options (8)
AvoidRowsOfUnequalLength (2)
Rows with different length than the commonest length of the table can be automatically skipped:
Using the default setting shows that the original tables had rows of unequal length:
SemanticImportSpecification (5)
The "SemanticImportSpecification" option can be used to try to semantically import all the tables:
Semantically import a specific list of tables:
The tables can have rows of unequal lengths:
An Association of list of types can be passed for the interpretation of each table (see the second argument of SemanticImport):
Additionally, SemanticImport options can be passed for each table:
ShowPreview (1)
Show a preview of each table in a "Print" cell:
Properties and Relations (2)
Extract the names of the 10 largest lakes by area from a table on Wikipedia:
In the Wolfram Language, the same data can be gathered directly using the Entity framework and knowledge representation:
Import a table:
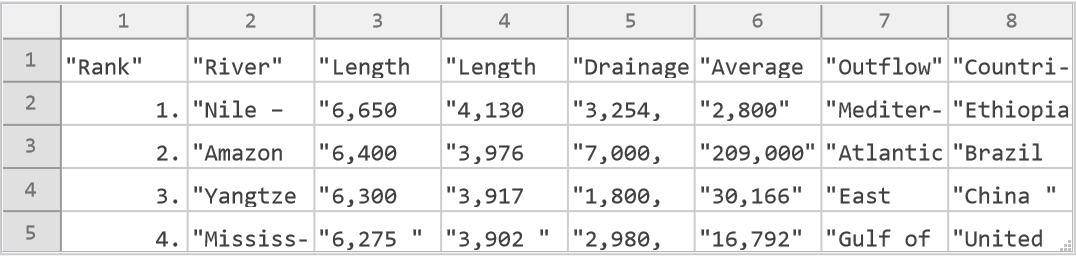
For more complex data tables, a direct call to the "Source" element of the Import function can be used, but parsing the result is complicated. For example, here we show the underlying structure of the same table:
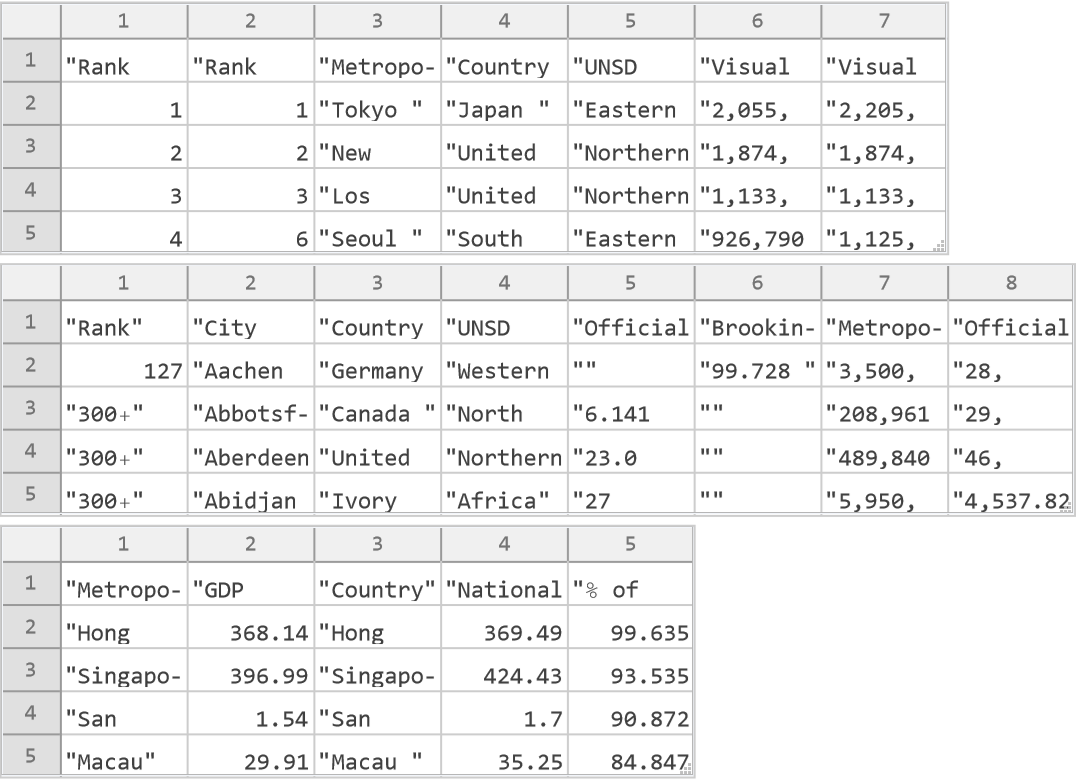
Possible Issues (2)
Unequal length rows can appear at the end of tables, since Wikipedia tables can have headers at the end:
Wikipedia tables can also have spanned cells in any place, in those cases they are reported as rows of unequal lengths, so that they can be fixed or deleted:
In some cases they are due to missing data and can be handled incorrectly by SemanticImport. For example, getting the Cuba GDP from the corresponding Wikipedia table gives an incorrect result, since the values are shifted for this row:
In other cases, the unequal length rows can happen because the first column is spanned to group some rows of the table:
To show the spanned strings in the first column we pad the unequal length rows with empty strings:
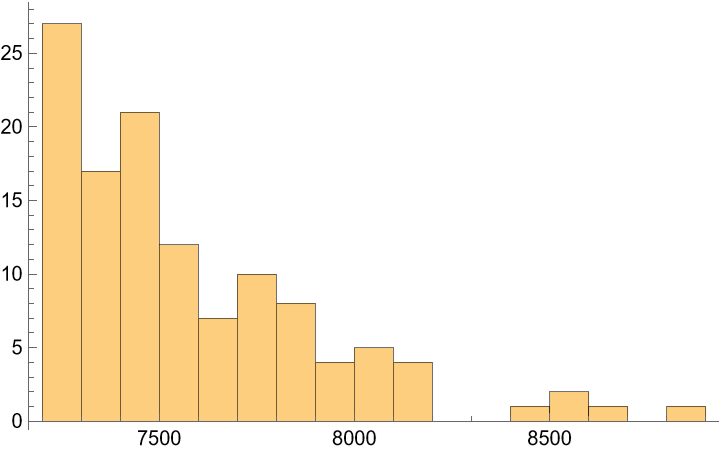
Applications (1)
Histogram of the tallest mountains:
![Short[ResourceFunction["ImportWikipediaTables"][
URL["https://es.wikipedia.org/wiki/Organización_territorial_de_México"]], 20]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/491d6fc481b9faf9.png)

![Dimensions /@ ResourceFunction["ImportWikipediaTables"][
"List of U.S. states and territories by area", "AvoidRowsOfUnequalLength" -> True]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/0ac114f7b6389bcc.png)
![ResourceFunction[
"ImportWikipediaTables"]["List of islands by population", "IconAssociation", "SemanticImportSpecification" -> All]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/14eee4ffbe20abe1.png)

![ResourceFunction[
"ImportWikipediaTables"]["List of islands by area", "IconAssociation", "SemanticImportSpecification" -> {3, 6}]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/168e0dbf4f8c6fc5.png)

![ResourceFunction[
"ImportWikipediaTables"]["List of U.S. states and territories by area", "IconAssociation", "SemanticImportSpecification" -> All]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/60c308848d563d0d.png)

![Normal[ResourceFunction["ImportWikipediaTables"][
"List of islands by area", "SemanticImportSpecification" -> {{1}, {3, <|1 -> Number, 2 -> String|>}}][[3]]]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/0a235d0d3c72038c.png)

![ResourceFunction[
"ImportWikipediaTables"]["List of islands by area", "IconAssociation", "SemanticImportSpecification" -> {{1}, {3, {Integer, String, Number, Number, None}, "Options" -> {HeaderLines -> 2}}}]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/2dab3f63ef34e8b7.png)

![Partition[StringCases[
StringCases[
Import["https://en.wikipedia.org/wiki/List_of_river_systems_by_length", "Source"], Shortest["<table" ~~ __ ~~ "</table>"], \[Infinity]][[
6]], {"<td" ~~ Shortest[___] ~~ ">" ~~ Shortest[str__] ~~ "</td>" :> "data", "<th" ~~ Shortest[___] ~~ ">" ~~ Shortest[str__] ~~ "</th>" :> "header"}], 8][[;; 5]] // TableForm](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/61024ad0d419fb38.png)


![ds = Query[1, "Data", 1][
ResourceFunction["ImportWikipediaTables"][
"List of countries by GDP (nominal)", "IconAssociation", "SemanticImportSpecification" -> {{1, Automatic, "Options" -> {HeaderLines -> 1, ExcludedLines -> {2}}}}]];
ds = ds[All, <|"Country" -> "Country/Territory", "UNRegion" -> "UN Region", "Estimate (IMF)" -> "IMF [1] [13]", "Date (IMF)" -> "World Bank [14]", "Estimate (WorldBank)" -> "United Nations [15]", "Date (WorldBank)" -> "column6"|>];
ds[Select[#"Country" === Entity["Country", "Cuba"] &]]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/767ad1570d5e1eca.png)

![tables = ResourceFunction["ImportWikipediaTables"][
"List of tallest mountains in the Solar System", "IconAssociation"][1]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/320cf9ea71c2ca25.png)
![table1 = First@tables["Data"];
With[{idx = Complement[Range[First@tables["Dimensions"]], tables["UnequalLengthRows"]]}, table1[[idx]] = Prepend[#, ""] & /@ table1[[idx]]];
table1[[All, 1 ;; 3]] // TableForm](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/307275d4ebe3d38d.png)

![Histogram[
First[ResourceFunction["ImportWikipediaTables"][
"List of highest mountains on Earth", "SemanticImportSpecification" -> {{1, <|3 -> Real|>, "Options" -> {HeaderLines -> None, ExcludedLines -> {1, 2, 3}}}}]], 20]](https://www.wolframcloud.com/obj/resourcesystem/images/8d9/8d9c1903-8229-4c22-9d85-c618740cb382/067432afa23af523.png)