Details and Options
ResourceFunction["CrackCaesarCipher"] has the following options:
| Method | Automatic | method used to decipher the message |
| Language | "English" | language to use for dictionaries and letter frequencies |
| "WordValueFunction" | StringLength | function for valuing a matched substring |
| "DictionaryWords" | Automatic | list of words to use for a dictionary attack |
Possible forms for the option
Method are:
| "Dictionary" | sort possible deciphered messages based on the presence of words from a dictionary |
| "LetterFrequency" | sort possible deciphered messages based on the letter frequencies and compare those with known letter frequencies based on Language |
| Automatic | if the string has a length smaller or equal to 100 characters, "Dictionary" is used; for texts above 100 characters, "LetterFrequencies" is used |
For the method "Dictionary", each word in the dictionary is tested for its presence. Each matched string gets a value according to the option "WordValueFunction". The highest-value-candidate deciphered message will be returned.
For the method "Dictionary", a custom list of words can also be given using the option "DictionaryWords".
Letter frequencies are known for the following languages: Czech, Danish, Dutch, English, Esperanto, Finnish, French, German, Icelandic, Italian, Polish, Portuguese, Spanish, Swedish and Turkish. Data is based on
Wikipedia's article on letter frequency.
For the method
"LetterFrequency", the frequency of the letters is compared to the known letter frequencies for various languages by calculating Pearson’s correlation coefficient between the letter frequency of the message for various shifts and the known letter frequencies for the language given by the option
Language.
When
n is given, a list of length
n is returned. Each element is an
Association with three keys:
"DecipheredString" contains the deciphered string,
"Score" gives the score of the decipher and
"Shift" gives the Caesar shift. The methods
"Dictionary" and
"LetterFrequency" give different scores and cannot be directly compared.



![s = ResourceFunction["CaesarCipher"]["my hovercraft is full of eels!",
11];
ResourceFunction["CrackCaesarCipher"][s, Method -> "Dictionary", "DictionaryWords" -> {"airplane", "truck", "hovercraft", "car", "boat", "plane", "bike", "bicyle", "moped"}]](https://www.wolframcloud.com/obj/resourcesystem/images/fb3/fb3c0cfe-3c74-4dc3-8cb1-88c121c4a444/02a713b12b817e31.png)
![hamlet = ExampleData[{"Text", "Hamlet"}];
hamlet = ResourceFunction["CaesarCipher"][hamlet, 6];
ResourceFunction["CrackCaesarCipher"][hamlet] // Short](https://www.wolframcloud.com/obj/resourcesystem/images/fb3/fb3c0cfe-3c74-4dc3-8cb1-88c121c4a444/070720271c0a91ec.png)
![message = ResourceFunction["CaesarCipher"]["De rode auto!", 11];
ResourceFunction["CrackCaesarCipher"][message, Method -> "Dictionary",
Language -> #] & /@ {"Finnish", "Dutch"}](https://www.wolframcloud.com/obj/resourcesystem/images/fb3/fb3c0cfe-3c74-4dc3-8cb1-88c121c4a444/751fd794194490d1.png)
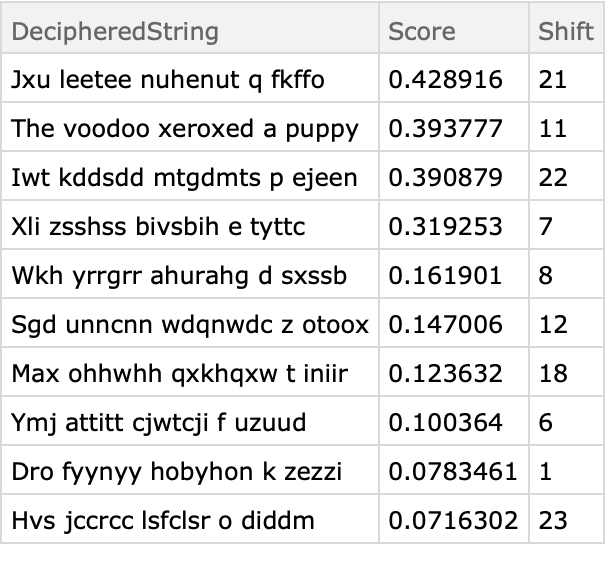
![shorthamlet = StringTake[ExampleData[{"Text", "Hamlet"}], 1000];
shorthamlet = ResourceFunction["CaesarCipher"][shorthamlet, 6];
AbsoluteTiming[
ResourceFunction["CrackCaesarCipher"][shorthamlet, Method -> "Dictionary"];]](https://www.wolframcloud.com/obj/resourcesystem/images/fb3/fb3c0cfe-3c74-4dc3-8cb1-88c121c4a444/326b41583c0be90b.png)