Basic Examples (2)
Here is a stem or the word "качество":
Here are the stems for a list of words:
Scope (3)
The stem rules currently used by BulgarianStem can be retrieved with the argument "CurrentRules"; here is a sample of the current rules:
Words without recognized suffixes by BulgarianStem are returned unchanged:
The symbol BulgarianStem is overloaded—it takes arguments that allow the control and monitoring of the stem rules that are applied. There are three sets of rules.
The following command sets up the use of the third set with each rule having a frequency (count) of at least 2:
Here is the number of rules (which were just set):
Here is a sample of the rules:
Here are stems of the list of words above using the newly set rules:
Here we restore the default stem rules:
Applications (2)
Finding word stems is one of the fundamental procedures in information retrieval.
Take Bulgarian text from Wikipedia:
Here we get the words from the text:
Here we find the number of occurrences of each word and show the words with the largest counts:
Here we stem the words, find the number of occurrences of each word stem and show the stems with the largest counts:
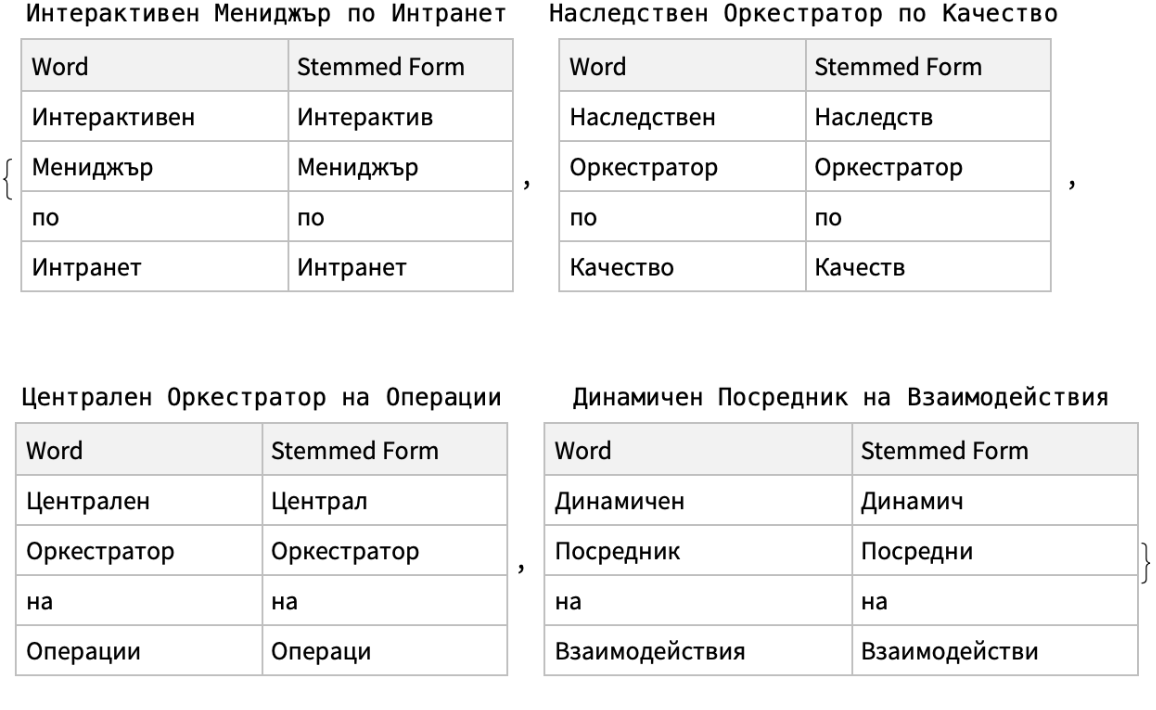
Consider the following random job titles in Bulgarian:
Here is a list of tables that show the words of the job titles and their corresponding stems:
Properties and Relations (4)
Here is the number of rules in each of the three sets of rules:
Here are stem rule samples:
The current set of stem rules can be obtained with the argument "CurrentRules":
Each stem rule has an associated count (or frequency); here is the minimum count of the current rules:
Here is the number of current rules:
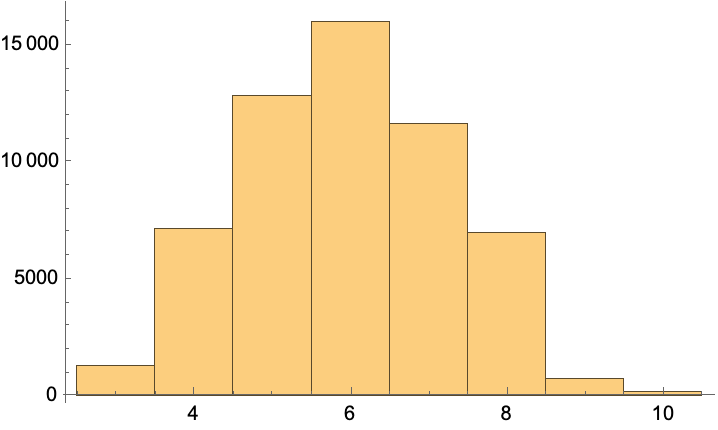
Here is the string length of the replacement values of the current stem rules:
Here is a histogram of the lengths of the suffixes that are replaced with the current stem rules:
The function WordStem gives stems of English words:
Here is a corresponding call of BulgarianStem:
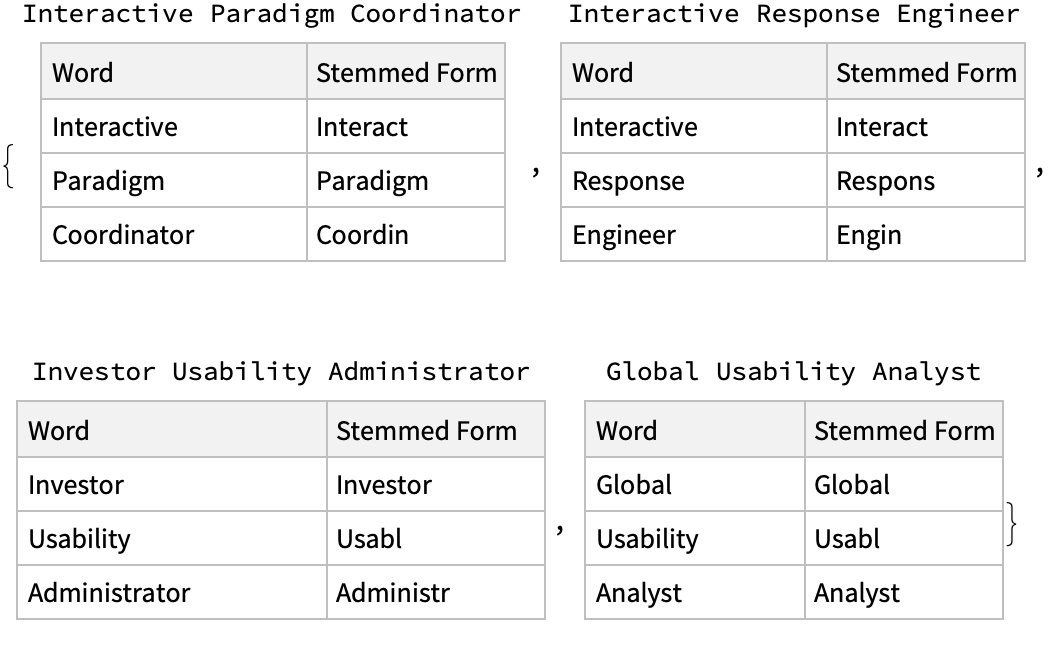
Here is a list of tables that show the words of job titles in English and their corresponding stems (analogous to the list of tables above):
The words of a text can be obtained with StringSplit or TextWords and then given to BulgarianStem:
Neat Examples (3)
Here is some English text:
Here are the stems of the words in the English text:
Here we translate the English text into Bulgarian text, extract the words and stem them:
![ResourceFunction["BulgarianStem"]["SetRules"[2, 2]];
ResourceFunction[
"BulgarianStem"][{"качество", "рандевуто", "линейността", "кафяво"}]](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/7dd025344fa96396.png)
![textAZlatarov = WikipediaData["Asen Zlatarov", Language -> {\!\(\*
NamespaceBox["LinguisticAssistant",
DynamicModuleBox[{Typeset`query$$ = "English", Typeset`boxes$$ = TemplateBox[{"\"English\"",
RowBox[{"Entity", "[",
RowBox[{"\"Language\"", ",", "\"English::385w8\""}], "]"}], "\"Entity[\\\"Language\\\", \\\"English::385w8\\\"]\"", "\"language\""}, "Entity"], Typeset`allassumptions$$ = {{"type" -> "Clash", "word" -> "English", "template" -> "Assuming \"English\" is a language${separator}Use as ${desc} or ${desc} instead", "count" -> "3", "pulldown" -> "false", "default" -> "{\"C\", \"English\"} -> {\"Language\", \"dflt\"}", "Values" -> {{"name" -> "Language", "desc" -> "a language", "input" -> "{\"C\", \"English\"} -> {\"Language\"}"}, {"name" -> "GivenName", "desc" -> "a given name", "input" -> "{\"C\", \"English\"} -> {\"GivenName\"}"}, {"name" -> "Surname", "desc" -> "a surname", "input" -> "{\"C\", \"English\"} -> {\"Surname\"}"}}}},
Typeset`assumptions$$ = {}, Typeset`open$$ = {1, 2}, Typeset`querystate$$ = {"Online" -> True, "Allowed" -> True,
"mparse.jsp" -> 0.698978, "Messages" -> {}}},
DynamicBox[ToBoxes[
AlphaIntegration`LinguisticAssistantBoxes["", 4, Automatic,
Dynamic[Typeset`query$$],
Dynamic[Typeset`boxes$$],
Dynamic[Typeset`allassumptions$$],
Dynamic[Typeset`assumptions$$],
Dynamic[Typeset`open$$],
Dynamic[Typeset`querystate$$]], StandardForm],
ImageSizeCache->{166.25, {8.125, 17.125}},
TrackedSymbols:>{Typeset`query$$, Typeset`boxes$$, Typeset`allassumptions$$, Typeset`assumptions$$, Typeset`open$$, Typeset`querystate$$}],
DynamicModuleValues:>{},
UndoTrackedVariables:>{Typeset`open$$}],
BaseStyle->{"Deploy"},
DeleteWithContents->True,
Editable->False,
SelectWithContents->True]\) -> \!\(\*
NamespaceBox["LinguisticAssistant",
DynamicModuleBox[{Typeset`query$$ = "Bulgarian", Typeset`boxes$$ = TemplateBox[{"\"Bulgarian\"",
RowBox[{"Entity", "[",
RowBox[{"\"Language\"", ",", "\"Bulgarian::xmr5j\""}], "]"}], "\"Entity[\\\"Language\\\", \\\"Bulgarian::xmr5j\\\"]\"", "\"language\""}, "Entity"], Typeset`allassumptions$$ = {{"type" -> "Clash", "word" -> "Bulgarian", "template" -> "Assuming \"Bulgarian\" is a language${separator}Use as ${desc} or ${desc} instead", "count" -> "3", "pulldown" -> "false", "default" -> "{\"C\", \"Bulgarian\"} -> {\"Language\", \"dflt\"}", "Values" -> {{"name" -> "Language", "desc" -> "a language", "input" -> "{\"C\", \"Bulgarian\"} -> {\"Language\"}"}, {"name" -> "Country", "desc" -> "a country", "input" -> "{\"C\", \"Bulgarian\"} -> {\"Country\"}"}, {"name" -> "Alphabet", "desc" -> "an alphabet", "input" -> "{\"C\", \"Bulgarian\"} -> {\"Alphabet\"}"}}}},
Typeset`assumptions$$ = {}, Typeset`open$$ = {1, 2}, Typeset`querystate$$ = {"Online" -> True, "Allowed" -> True,
"mparse.jsp" -> 0.913959, "Messages" -> {}}},
DynamicBox[ToBoxes[
AlphaIntegration`LinguisticAssistantBoxes["", 4, Automatic,
Dynamic[Typeset`query$$],
Dynamic[Typeset`boxes$$],
Dynamic[Typeset`allassumptions$$],
Dynamic[Typeset`assumptions$$],
Dynamic[Typeset`open$$],
Dynamic[Typeset`querystate$$]], StandardForm],
ImageSizeCache->{183.25, {8.125, 17.125}},
TrackedSymbols:>{Typeset`query$$, Typeset`boxes$$, Typeset`allassumptions$$, Typeset`assumptions$$, Typeset`open$$, Typeset`querystate$$}],
DynamicModuleValues:>{},
UndoTrackedVariables:>{Typeset`open$$}],
BaseStyle->{"Deploy"},
DeleteWithContents->True,
Editable->False,
SelectWithContents->True]\)}];](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/6a9d5d511a95aff2.png)


![Map[Labeled[
Dataset[Transpose[{TextWords@#1, ResourceFunction["BulgarianStem"]@TextWords@#1}]][All, AssociationThread[{"Word", "Stemmed Form"}, #] &], #1, Top] &, lsTitles]](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/337a374876644316.png)
![ResourceFunction["GridTableForm"][
RandomSample[#, 6] & /@ ResourceFunction["BulgarianStem"]["AllStemRulesWithCounts"]]](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/27480e9e3147caee.png)

![SeedRandom[32];
Map[Labeled[
Dataset[Transpose[{TextWords@#1, WordStem@TextWords@#1}]][All, AssociationThread[{"Word", "Stemmed Form"}, #] &], #1, Top] &, ResourceFunction["RandomPretentiousJobTitle"]["English", 4]]](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/42fa9390037c342d.png)
![ResourceFunction["BulgarianStem"]@
StringSplit[
"Покълването на посевите се очаква с търпение, пиене и сланина.", RegularExpression["\\W+"]]](https://www.wolframcloud.com/obj/resourcesystem/images/ae5/ae5d019b-df7a-43bf-8fcf-bf94ea84172c/72ed3914356eb222.png)