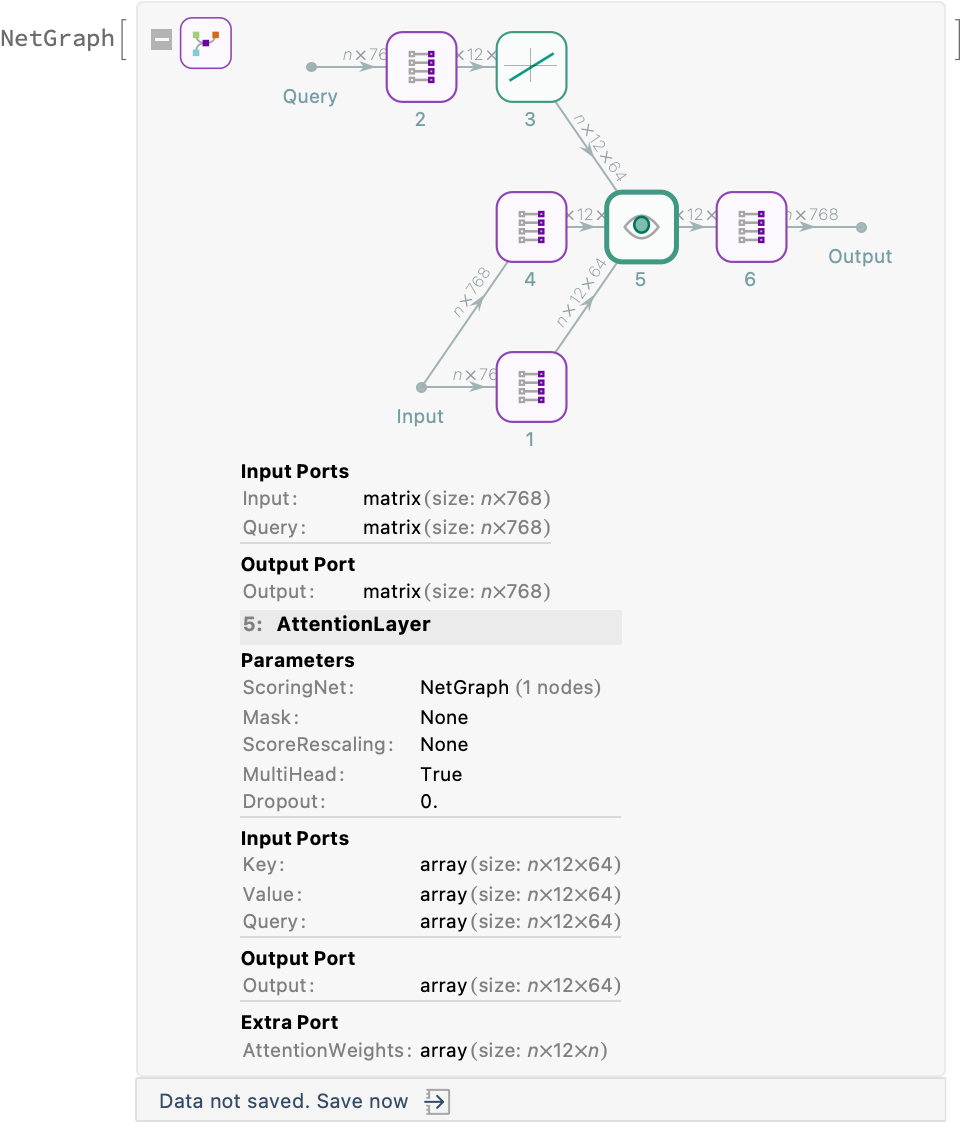
Details and Options
AttentionBlock is a key component in transformer-based neural network architectures. It allows the model to attend to different parts of the input sequence simultaneously by splitting the attention mechanism into multiple heads. Each head focuses on a different subspace of the input, enabling the model to capture diverse features or relationships within the data.
The number of attention heads, n, must divide the dimension dim:
Self-attention focuses on relationships within a single sequence, letting each element attend to all others in the same sequence.
Cross-attention connects two sequences, where one sequence attends to another, learning relationships between them.
RoPE (Rotary Positional Encoding) embeds positional information by rotating query and key vectors, improving generalization to longer sequences.
The following properties are supported:
| "Mask" | None | prevent certain patterns of attention |
| "CrossAttention" | False | allow attention between different sequences |
| RoPE | False | encode positional information using Rotary Position Embedding |
| None | no masking |
| "Causal" | causal masking |
| "Causal"→n | local causal masking with a window of size n |

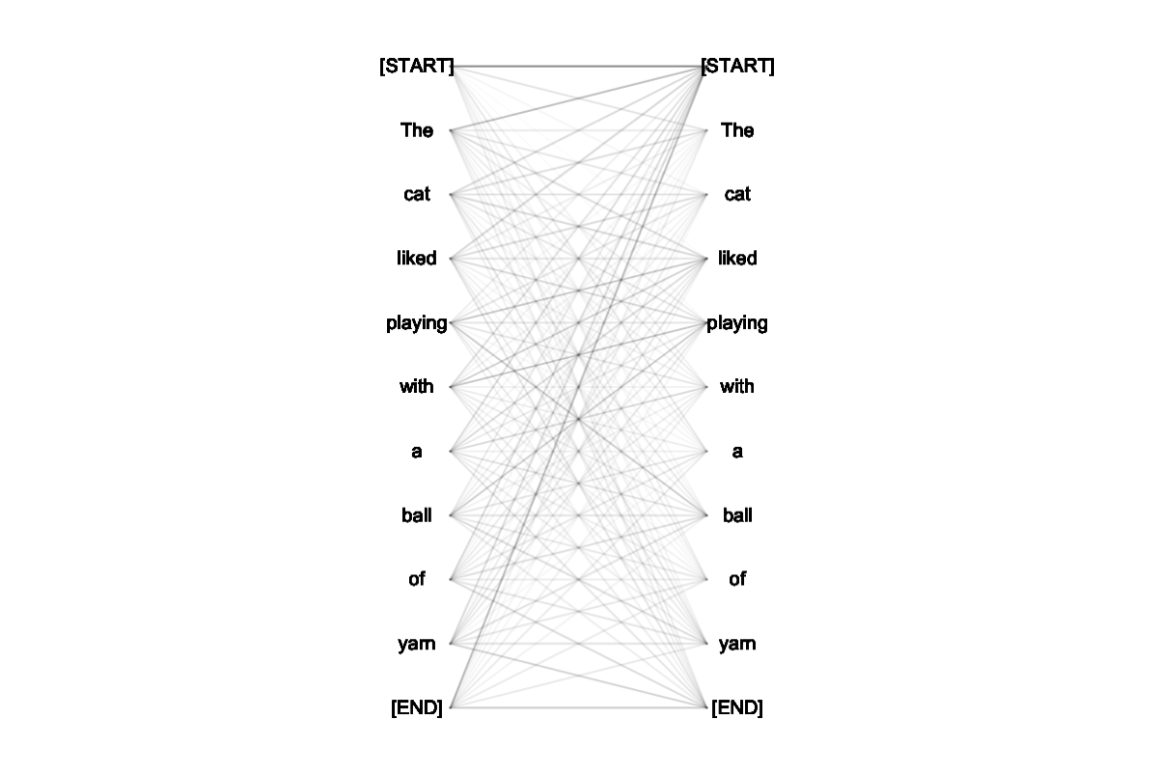
![input = "The cat liked playing with a ball of yarn";
weights = net[input, NetPort[{"encoder", 1, 1, "attention", -2, "AttentionWeights"}]];
tokens = {"[START]", Splice[StringSplit[input]], "[END]"}](https://www.wolframcloud.com/obj/resourcesystem/images/d29/d2998bab-2b23-4d9c-8494-1814fcc181ac/7e1589607e60760e.png)
![Graphics[{s1, heads, s2} = Dimensions[weights]; avgWeights = Mean[Transpose[weights]]; headColors = Table[Hue[h/Max[heads - 1, 1]], {h, heads}]; lines = Table[{Opacity[3 avgWeights[[i, j]]], Line[{{0, -i}, {4, -j}}]}, {i, s1}, {j, s2}]; lines1 = Flatten[lines, {{1}, {2, 3}}]; lines2 = Flatten[lines, {{2}, {1, 3}}]; attentionColors = Table[Graphics[{Opacity[weights[[i, h, j]], headColors[[h]]], Rectangle[{0, 0}, {1, 1}/8]}, ImageSize -> Scaled[0.1`^14.5`]], {i, s1}, {j, s2}, {h, heads}]; g = Table[Row[attentionColors[[i, j, All]]], {i, s1}, {j, s2}]; attendTo = Table[Inset[g[[i, j]], {8, -j}], {i, s1}, {j, s2}]; toAttend = Table[Inset[g[[i, j]], {-4, -i}], {j, s2}, {i, s1}]; Table[t1 = Text[tokens[[i]], {-0.5`, -i}]; t2 = Text[tokens[[j]], {4.5`, -j}]; {Mouseover[t2, Style[Join[{Lighter[Red], t2}, Riffle[lines2[[j]], Red, {2, -1, 3}], toAttend[[j]]]]], Mouseover[t1, Style[Join[{Lighter[Blue], t1}, Riffle[lines1[[i]], Blue, {2, -1, 3}], attendTo[[i]]]]], Opacity[avgWeights[[i, j]]], Line[{{0, -i}, {4, -j}}]}, {i, s1}, {j, s2}], ImageSize -> 600, FrameTicks -> None, PlotRange -> {{-7, 11}, {-s1 - 1, 0}}]](https://www.wolframcloud.com/obj/resourcesystem/images/d29/d2998bab-2b23-4d9c-8494-1814fcc181ac/28f75274715bb9ac.png)