Wolfram Function Repository
Instant-use add-on functions for the Wolfram Language
Function Repository Resource:
Select rows from Tabular data based on explicit column values
ResourceFunction["SelectByColumnValues"][tab,col→val] selects all rows in Tabular data tab where column col has value val. | |
ResourceFunction["SelectByColumnValues"][tab,col→{val1,…}] selects rows where col has one of the given values vali. | |
ResourceFunction["SelectByColumnValues"][spec] is an operator form of ResourceFunction["SelectByColumnValues"] that can be applied to expressions. |
Create tabular data:
| In[1]:= |
| Out[1]= | 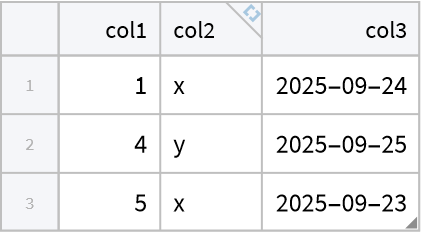 |
Select the rows where "col2" is x:
| In[2]:= |
| Out[2]= | 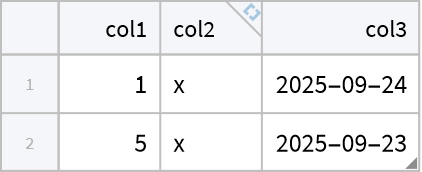 |
Select rows where "col1" is any of the given values. Values that aren't present will be ignored:
| In[3]:= |
| Out[3]= | 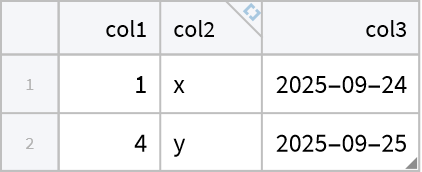 |
Define an operator:
| In[4]:= |
| Out[4]= |
Define a dataset:
| In[5]:= |
| Out[5]= |  |
Use the operator on the dataset:
| In[6]:= |
| Out[6]= | 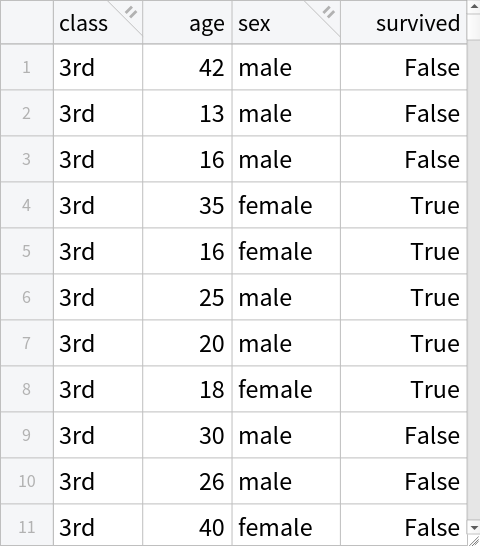 |
Select based on a large number of possible values:
| In[7]:= |
| Out[7]= | 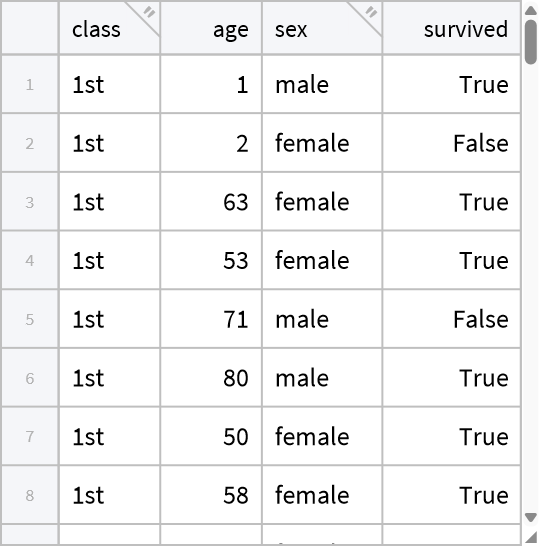 |
An empty Tabular is returned if no matching rows were found:
| In[8]:= |
| Out[8]= |
SelectByColumnValues is designed to be fast for large datasets:
| In[9]:= | ![n = 10^6;
SeedRandom[1234];
tab = ToTabular[<|"a" -> Range[n], "b" -> RandomChoice[Alphabet[], n],
"c" -> RandomReal[1, n]|>, "Columns"]](https://www.wolframcloud.com/obj/resourcesystem/images/6cb/6cbf112c-9a38-4812-abe5-735bdebfbf25/0dcc8a9ebdb05eea.png) |
| Out[10]= |  |
Selecting based on values in the a column is much faster with SelectByColumnValues than using Select and MemberQ because MemberQ doesn't compile internally:
| In[11]:= |
| Out[12]= | 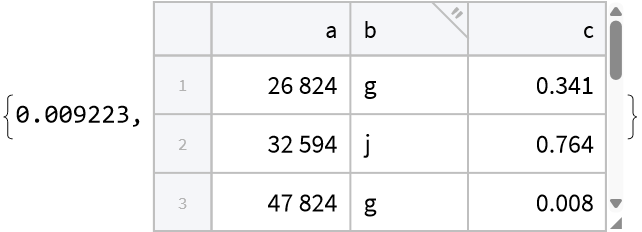 |
| In[13]:= |
| Out[13]= | 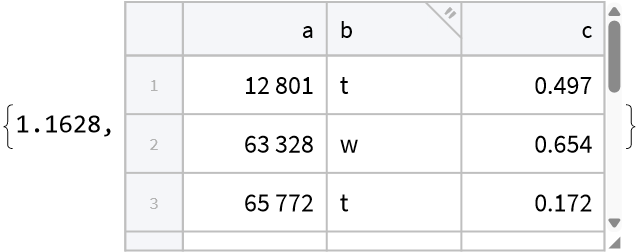 |
You can optimize Select by writing a query function that does compile:
| In[14]:= |
| Out[14]= |
| In[15]:= |
| Out[15]= |
However, this doesn't scale well for larger sets of query values:
| In[16]:= |
| Out[17]= |
| In[18]:= |
| Out[18]= |
SelectByColumnValues is still fast:
| In[19]:= |
| Out[19]= |
Tabular data without column headings cannot be used:
| In[20]:= |
| Out[20]= | 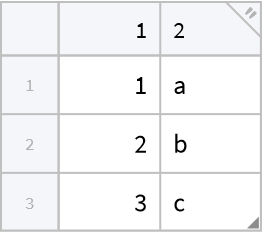 |
| In[21]:= |
| Out[21]= |
Use RenameColumns to add column headings:
| In[22]:= |
| Out[22]= | 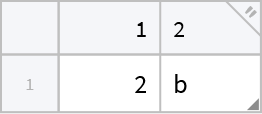 |
This work is licensed under a Creative Commons Attribution 4.0 International License