Wolfram Language Paclet Repository
Community-contributed installable additions to the Wolfram Language
ArXivExplore helps the deep data analysis of all research articles on ArXiv
Contributed by: Daniele Gregori
ArXivExplore helps the deep data analysis of all 2.6M physics, math, cs, etc. articles on ArXiv, providing functionality for e.g. title/abstract word statistics; TeX source/formulae and citations dissection; NNs for classification or recommendation; LLM automated concept definitions and author reports.

To install this paclet in your Wolfram Language environment,
evaluate this code:
PacletInstall["DanieleGregori/ArXivExplore"]
To load the code after installation, evaluate this code:
Needs["DanieleGregori`ArXivExplore`"]
The first article ever on ArXiv:
| In[1]:= |
| Out[1]= |
| In[2]:= |
| Out[2]= |
| In[3]:= |
| Out[3]= |
| In[4]:= |
| Out[4]= |
A DateListPlot showing the trends in the most popular title words in theoretical physics category (hep-th):
| In[5]:= | ![Block[{words = {"black", "gauge", "gravity", "string"}},
InterpretationBox[FrameBox[TagBox[TooltipBox[PaneBox[GridBox[List[List[GraphicsBox[List[Thickness[0.0025`], List[FaceForm[List[RGBColor[0.9607843137254902`, 0.5058823529411764`, 0.19607843137254902`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3]]], List[List[List[205.`, 22.863691329956055`], List[205.`, 212.31669425964355`], List[246.01799774169922`, 235.99870109558105`], List[369.0710144042969`, 307.0436840057373`], List[369.0710144042969`, 117.59068870544434`], List[205.`, 22.863691329956055`]], List[List[30.928985595703125`, 307.0436840057373`], List[153.98200225830078`, 235.99870109558105`], List[195.`, 212.31669425964355`], List[195.`, 22.863691329956055`], List[30.928985595703125`, 117.59068870544434`], List[30.928985595703125`, 307.0436840057373`]], List[List[200.`, 410.42970085144043`], List[364.0710144042969`, 315.7036876678467`], List[241.01799774169922`, 244.65868949890137`], List[200.`, 220.97669792175293`], List[158.98200225830078`, 244.65868949890137`], List[35.928985595703125`, 315.7036876678467`], List[200.`, 410.42970085144043`]], List[List[376.5710144042969`, 320.03370475769043`], List[202.5`, 420.53370475769043`], List[200.95300006866455`, 421.42667961120605`], List[199.04699993133545`, 421.42667961120605`], List[197.5`, 420.53370475769043`], List[23.428985595703125`, 320.03370475769043`], List[21.882003784179688`, 319.1406993865967`], List[20.928985595703125`, 317.4896984100342`], List[20.928985595703125`, 315.7036876678467`], List[20.928985595703125`, 114.70369529724121`], List[20.928985595703125`, 112.91769218444824`], List[21.882003784179688`, 111.26669120788574`], List[23.428985595703125`, 110.37369346618652`], List[197.5`, 9.87369155883789`], List[198.27300024032593`, 9.426692008972168`], List[199.13700008392334`, 9.203690528869629`], List[200.`, 9.203690528869629`], List[200.86299991607666`, 9.203690528869629`], List[201.72699999809265`, 9.426692008972168`], List[202.5`, 9.87369155883789`], List[376.5710144042969`, 110.37369346618652`], List[378.1179962158203`, 111.26669120788574`], List[379.0710144042969`, 112.91769218444824`], List[379.0710144042969`, 114.70369529724121`], List[379.0710144042969`, 315.7036876678467`], List[379.0710144042969`, 317.4896984100342`], List[378.1179962158203`, 319.1406993865967`], List[376.5710144042969`, 320.03370475769043`]]]]], List[FaceForm[List[RGBColor[0.5529411764705883`, 0.6745098039215687`, 0.8117647058823529`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[44.92900085449219`, 282.59088134765625`], List[181.00001525878906`, 204.0298843383789`], List[181.00001525878906`, 46.90887451171875`], List[44.92900085449219`, 125.46986389160156`], List[44.92900085449219`, 282.59088134765625`]]]]], List[FaceForm[List[RGBColor[0.6627450980392157`, 0.803921568627451`, 0.5686274509803921`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[355.0710144042969`, 282.59088134765625`], List[355.0710144042969`, 125.46986389160156`], List[219.`, 46.90887451171875`], List[219.`, 204.0298843383789`], List[355.0710144042969`, 282.59088134765625`]]]]], List[FaceForm[List[RGBColor[0.6901960784313725`, 0.5882352941176471`, 0.8117647058823529`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[200.`, 394.0606994628906`], List[336.0710144042969`, 315.4997024536133`], List[200.`, 236.93968200683594`], List[63.928985595703125`, 315.4997024536133`], List[200.`, 394.0606994628906`]]]]]], List[Rule[BaselinePosition, Scaled[0.15`]], Rule[ImageSize, 10], Rule[ImageSize, 15]]], StyleBox[RowBox[List["ArXivPlot", " "]], Rule[ShowAutoStyles, False], Rule[ShowStringCharacters, False], Rule[FontSize, Times[0.9`, Inherited]], Rule[FontColor, GrayLevel[0.1`]]]]], Rule[GridBoxSpacings, List[Rule["Columns", List[List[0.25`]]]]]], Rule[Alignment, List[Left, Baseline]], Rule[BaselinePosition, Baseline], Rule[FrameMargins, List[List[3, 0], List[0, 0]]], Rule[BaseStyle, List[Rule[LineSpacing, List[0, 0]], Rule[LineBreakWithin, False]]]], RowBox[List["PacletSymbol", "[", RowBox[List["\"DanieleGregori/ArXivExplore\"", ",", "\"DanieleGregori`ArXivExplore`ArXivPlot\""]], "]"]], Rule[TooltipStyle, List[Rule[ShowAutoStyles, True], Rule[ShowStringCharacters, True]]]], Function[Annotation[Slot[1], Style[Defer[PacletSymbol["DanieleGregori/ArXivExplore", "DanieleGregori`ArXivExplore`ArXivPlot"]], Rule[ShowStringCharacters, True]], "Tooltip"]]], Rule[Background, RGBColor[0.968`, 0.976`, 0.984`]], Rule[BaselinePosition, Baseline], Rule[DefaultBaseStyle, List[]], Rule[FrameMargins, List[List[0, 0], List[1, 1]]], Rule[FrameStyle, RGBColor[0.831`, 0.847`, 0.85`]], Rule[RoundingRadius, 4]], PacletSymbol["DanieleGregori/ArXivExplore", "DanieleGregori`ArXivExplore`ArXivPlot"], Rule[Selectable, False], Rule[SelectWithContents, True], Rule[BoxID, "PacletSymbolBox"]][words, {"hep-th", All}, PlotRange -> Full, PlotLegends -> words]]](https://www.wolframcloud.com/obj/resourcesystem/images/d64/d64a1e95-2d49-46a8-ab0e-5fc84166f916/1-0-2/1b234771b51b08ce.png) |
| Out[5]= | 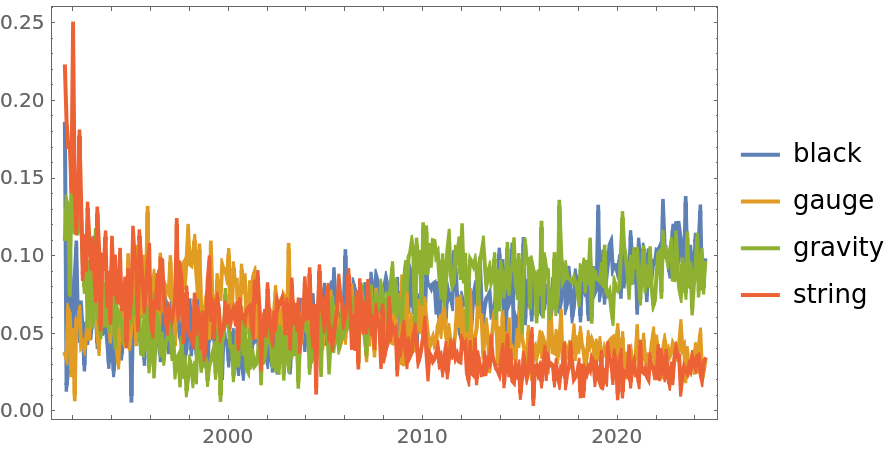 |
All the 50 most common 2-neighbour title words on the whole ArXiv, ever:
| In[6]:= |
| Out[6]= |  |
Let us also show an author's citations graph, with the tooltip indicating the articles ids:
| In[7]:= |
| Out[7]= | 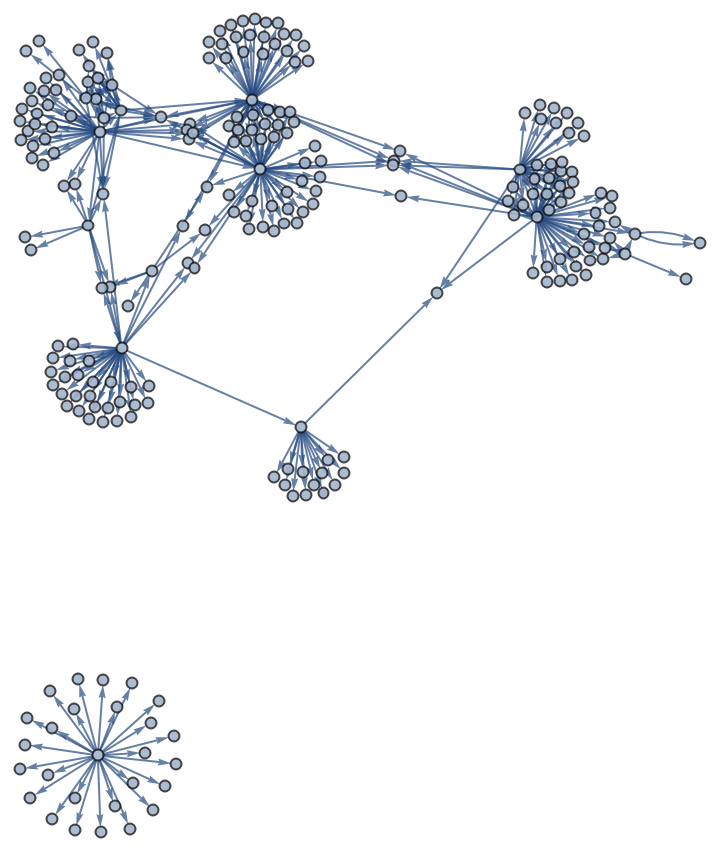 |
The dimensions whole ArXiv dataset (at the end of July 2024):
| In[8]:= |
| Out[8]= |
Let us create a super-database with all computer science "cs" type primary or cross-list categories:
| In[9]:= |
and then let us visualize the most frequent and less frequent title words:
| In[10]:= | ![Block[{cat = {"cs", All}, tabs, colrules, tabskey, compl, cut = 160, res = 10},
colrules = {"learning" -> Style["learning", Purple, Bold], "using" -> Style["using", Purple, Bold], "theory" -> Style["theory", Red, Bold], "understanding" -> Style["understanding", Red, Bold]};
tabs = MapAt[Apply[Sequence, #] &,
MapIndexed[
Partition[
Riffle[Map[Style[#, Bold] &, Range[res*(First[#2] - 1) + 1, res*First[#2]]], #], 2] &, Partition[
Normal@InterpretationBox[FrameBox[TagBox[TooltipBox[PaneBox[GridBox[List[List[GraphicsBox[List[Thickness[0.0025`], List[FaceForm[List[RGBColor[0.9607843137254902`, 0.5058823529411764`, 0.19607843137254902`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]], List[List[0, 2, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3], List[0, 1, 0], List[1, 3, 3]]], List[List[List[205.`, 22.863691329956055`], List[205.`, 212.31669425964355`], List[246.01799774169922`, 235.99870109558105`], List[369.0710144042969`, 307.0436840057373`], List[369.0710144042969`, 117.59068870544434`], List[205.`, 22.863691329956055`]], List[List[30.928985595703125`, 307.0436840057373`], List[153.98200225830078`, 235.99870109558105`], List[195.`, 212.31669425964355`], List[195.`, 22.863691329956055`], List[30.928985595703125`, 117.59068870544434`], List[30.928985595703125`, 307.0436840057373`]], List[List[200.`, 410.42970085144043`], List[364.0710144042969`, 315.7036876678467`], List[241.01799774169922`, 244.65868949890137`], List[200.`, 220.97669792175293`], List[158.98200225830078`, 244.65868949890137`], List[35.928985595703125`, 315.7036876678467`], List[200.`, 410.42970085144043`]], List[List[376.5710144042969`, 320.03370475769043`], List[202.5`, 420.53370475769043`], List[200.95300006866455`, 421.42667961120605`], List[199.04699993133545`, 421.42667961120605`], List[197.5`, 420.53370475769043`], List[23.428985595703125`, 320.03370475769043`], List[21.882003784179688`, 319.1406993865967`], List[20.928985595703125`, 317.4896984100342`], List[20.928985595703125`, 315.7036876678467`], List[20.928985595703125`, 114.70369529724121`], List[20.928985595703125`, 112.91769218444824`], List[21.882003784179688`, 111.26669120788574`], List[23.428985595703125`, 110.37369346618652`], List[197.5`, 9.87369155883789`], List[198.27300024032593`, 9.426692008972168`], List[199.13700008392334`, 9.203690528869629`], List[200.`, 9.203690528869629`], List[200.86299991607666`, 9.203690528869629`], List[201.72699999809265`, 9.426692008972168`], List[202.5`, 9.87369155883789`], List[376.5710144042969`, 110.37369346618652`], List[378.1179962158203`, 111.26669120788574`], List[379.0710144042969`, 112.91769218444824`], List[379.0710144042969`, 114.70369529724121`], List[379.0710144042969`, 315.7036876678467`], List[379.0710144042969`, 317.4896984100342`], List[378.1179962158203`, 319.1406993865967`], List[376.5710144042969`, 320.03370475769043`]]]]], List[FaceForm[List[RGBColor[0.5529411764705883`, 0.6745098039215687`, 0.8117647058823529`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[44.92900085449219`, 282.59088134765625`], List[181.00001525878906`, 204.0298843383789`], List[181.00001525878906`, 46.90887451171875`], List[44.92900085449219`, 125.46986389160156`], List[44.92900085449219`, 282.59088134765625`]]]]], List[FaceForm[List[RGBColor[0.6627450980392157`, 0.803921568627451`, 0.5686274509803921`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[355.0710144042969`, 282.59088134765625`], List[355.0710144042969`, 125.46986389160156`], List[219.`, 46.90887451171875`], List[219.`, 204.0298843383789`], List[355.0710144042969`, 282.59088134765625`]]]]], List[FaceForm[List[RGBColor[0.6901960784313725`, 0.5882352941176471`, 0.8117647058823529`], Opacity[1.`]]], FilledCurveBox[List[List[List[0, 2, 0], List[0, 1, 0], List[0, 1, 0], List[0, 1, 0]]], List[List[List[200.`, 394.0606994628906`], List[336.0710144042969`, 315.4997024536133`], List[200.`, 236.93968200683594`], List[63.928985595703125`, 315.4997024536133`], List[200.`, 394.0606994628906`]]]]]], List[Rule[BaselinePosition, Scaled[0.15`]], Rule[ImageSize, 10], Rule[ImageSize, 15]]], StyleBox[RowBox[List["ArXivTopTitles", " "]], Rule[ShowAutoStyles, False], Rule[ShowStringCharacters, False], Rule[FontSize, Times[0.9`, Inherited]], Rule[FontColor, GrayLevel[0.1`]]]]], Rule[GridBoxSpacings, List[Rule["Columns", List[List[0.25`]]]]]], Rule[Alignment, List[Left, Baseline]], Rule[BaselinePosition, Baseline], Rule[FrameMargins, List[List[3, 0], List[0, 0]]], Rule[BaseStyle, List[Rule[LineSpacing, List[0, 0]], Rule[LineBreakWithin, False]]]], RowBox[List["PacletSymbol", "[", RowBox[List["\"DanieleGregori/ArXivExplore\"", ",", "\"DanieleGregori`ArXivExplore`ArXivTopTitles\""]], "]"]], Rule[TooltipStyle, List[Rule[ShowAutoStyles, True], Rule[ShowStringCharacters, True]]]], Function[Annotation[Slot[1], Style[Defer[PacletSymbol["DanieleGregori/ArXivExplore", "DanieleGregori`ArXivExplore`ArXivTopTitles"]], Rule[ShowStringCharacters, True]], "Tooltip"]]], Rule[Background, RGBColor[0.968`, 0.976`, 0.984`]], Rule[BaselinePosition, Baseline], Rule[DefaultBaseStyle, List[]], Rule[FrameMargins, List[List[0, 0], List[1, 1]]], Rule[FrameStyle, RGBColor[0.831`, 0.847`, 0.85`]], Rule[RoundingRadius, 4]], PacletSymbol["DanieleGregori/ArXivExplore", "DanieleGregori`ArXivExplore`ArXivTopTitles"], Rule[Selectable, False], Rule[SelectWithContents, True], Rule[BoxID, "PacletSymbolBox"]][cat, cut], UpTo@res]], {All, All, 2}] /. colrules;
tabskey = First@Cases[
tabs, _List?(MemberQ[#[[All, 2]], Alternatives["theory", "understanding"] /. colrules] &)];
compl = Text[Style[
"... " <> ToString[Round[First@tabskey[[1, 1]] - 1, 10]] <> "+\n
words more\n
popular than\n
\"understanding\"\n
or \"theory\"\n
in CS !", Bold, 9, TextAlignment -> Center]];
GraphicsRow[{TextGrid@tabs[[1]], compl, TextGrid@tabskey}, ImageSize -> Medium]]](https://www.wolframcloud.com/obj/resourcesystem/images/d64/d64a1e95-2d49-46a8-ab0e-5fc84166f916/1-0-2/09bb8f9cd1966c96.png) |
| Out[10]= |  |
Let us compute the 4 most frequent categories, with their meaning:
| In[11]:= |
| Out[11]= |  |
Using only titles and abstracts, we can train a NN to classify different categories:
| In[12]:= |
| In[13]:= |
| Out[13]= |  |
| In[14]:= |
| Out[14]= | 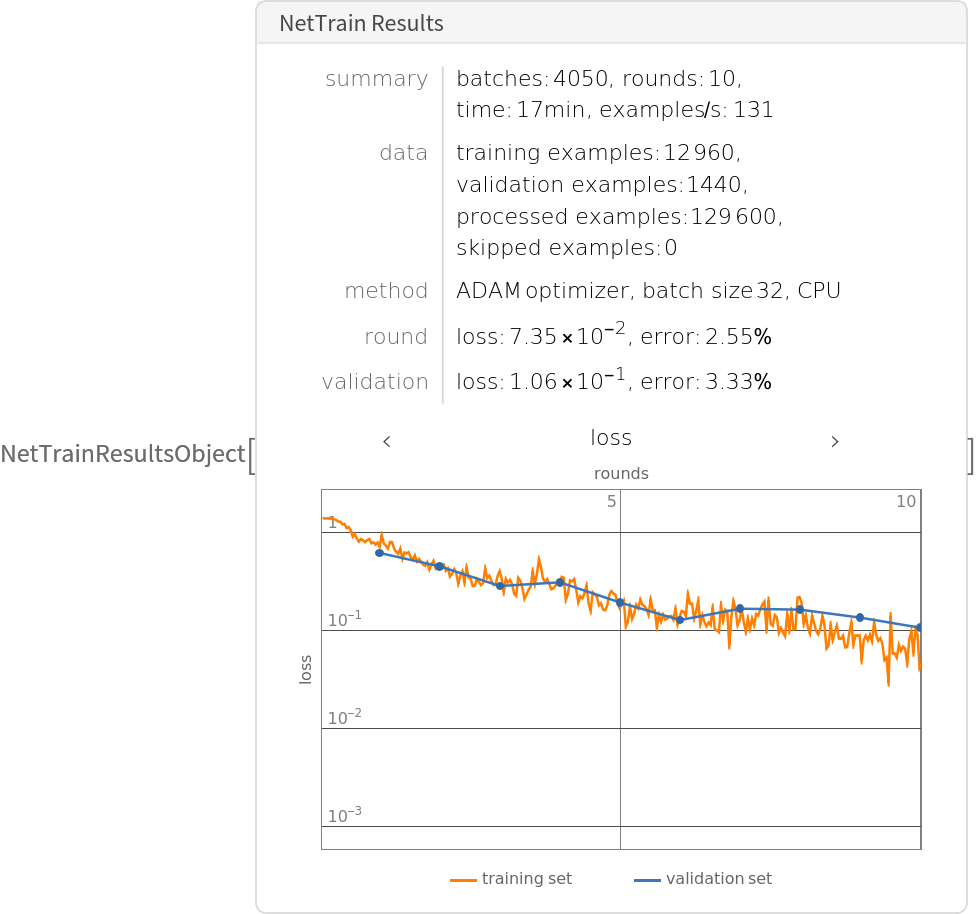 |
Even with a basic 17 minutes training on laptop CPU, we obtain 98% accuracy:
| In[15]:= |
| Out[15]= |
| In[16]:= |
| Out[16]= | 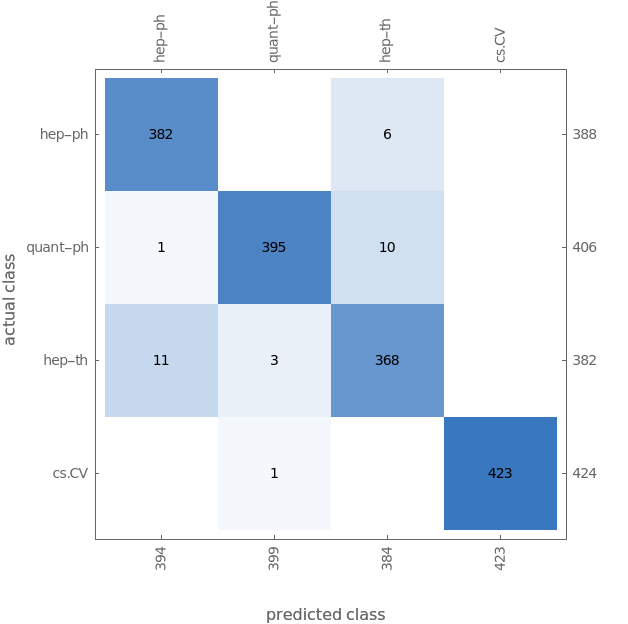 |
We could even classify authors within the same category, with ArXivClassifyAuthorNet.
Extracting TEX introduction:
| In[17]:= |
| Out[17]= |  |
also TEX formulae:
| In[18]:= |
| Out[18]= |  |
Explain a technical concept using an article introduction and LLMSynthesize:
| In[19]:= |
| Out[19]= |  |
Let us visualize all authors with more than 7 papers, in primary category "cs.NA":
| In[20]:= |
| Out[20]= | 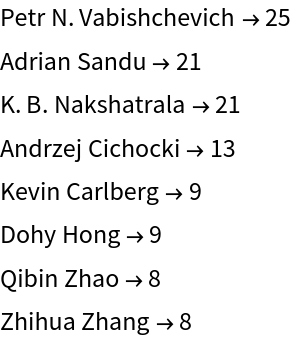 |
Let us pick a random author among them and use LLM functionality to explain his overall work:
| In[21]:= |
| Out[21]= |  |
Wolfram Language Version 14