Wolfram Language Paclet Repository
Community-contributed installable additions to the Wolfram Language
ArXivExplore helps the deep data analysis of all research articles on ArXiv
Contributed by: Daniele Gregori
ArXivExplore helps the deep data analysis of all 2.6M physics, math, cs, etc. articles on ArXiv, providing functionality for e.g. title/abstract word statistics; TeX source/formulae and citations dissection; NNs for classification or recommendation; LLM automated concept definitions and author reports.

To install this paclet in your Wolfram Language environment,
evaluate this code:
PacletInstall["DanieleGregori/ArXivExplore"]
To load the code after installation, evaluate this code:
Needs["DanieleGregori`ArXivExplore`"]
The first article ever on ArXiv:
| In[1]:= |
| Out[1]= |
| In[2]:= |
| Out[2]= |
| In[3]:= |
| Out[3]= |
A DateListPlot showing the trends in the most popular title words in theoretical physics category (hep-th):
| In[4]:= |
| Out[4]= | 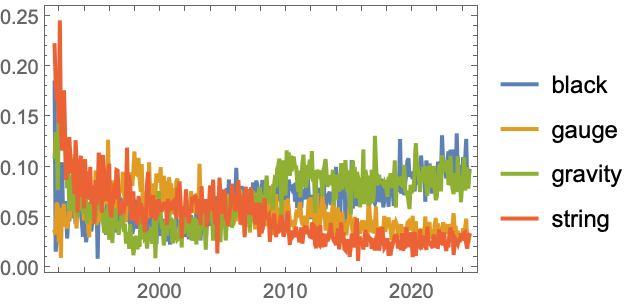 |
All the 100 most common 2-neighbour title words on the whole ArXiv, ever:
| In[5]:= |
| Out[5]= |  |
Let us also show an author's citations graph, with the tooltip indicating the articles ids:
| In[6]:= |
| Out[6]= | 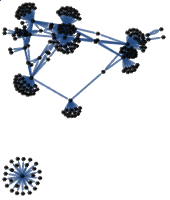 |
The dimensions whole ArXiv dataset (at the end of July 2024):
| In[7]:= |
| Out[7]= |
Let us create a super-database with all computer science "cs" type primary or cross-list categories:
| In[8]:= |
and then let us visualize the most frequent and less frequent title words:
| In[9]:= | ![Block[{cat = {"cs", All}, tabs, colrules, tabskey, compl, cut = 160, res = 16},
colrules = {"learning" -> Style["learning", Purple, Bold], "using" -> Style["using", Purple, Bold], "theory" -> Style["theory", Red, Bold], "understanding" -> Style["understanding", Red, Bold]};
tabs = MapAt[Apply[Sequence, #] &,
MapIndexed[
Partition[
Riffle[Map[Style[#, Bold] &, Range[res*(First[#2] - 1) + 1, res*First[#2]]], #], 2] &, Partition[Normal@ArXivTitlesWordsTop[cat, cut], UpTo@res]], {All,
All, 2}] /. colrules;
tabskey = First@Cases[
tabs, _List?(MemberQ[#[[All, 2]], Alternatives["theory", "understanding"] /. colrules] &)];
compl = Text[Style[
"... " <> ToString[Round[First@tabskey[[1, 1]] - 1, 10]] <> "+\n
words more\n
popular than\n
\"understanding\"\n
or \"theory\"\n
in CS !", Bold, 12, TextAlignment -> Center]];
GraphicsRow[{TextGrid@tabs[[1]], compl, TextGrid@tabskey}]]](https://www.wolframcloud.com/obj/resourcesystem/images/d64/d64a1e95-2d49-46a8-ab0e-5fc84166f916/1-0-1/45e7eaaf9690885d.png) |
| Out[9]= | 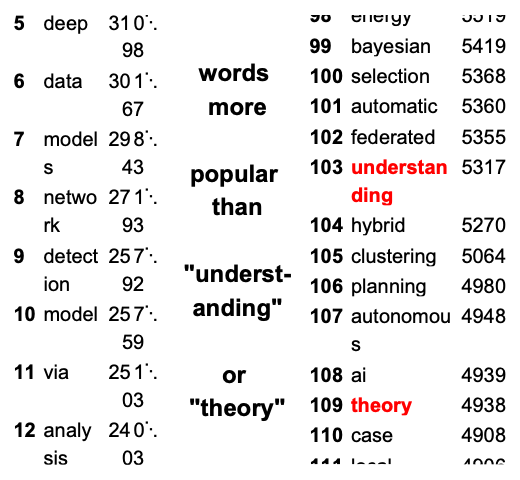 |
Let us compute the 4 most frequent categories:
| In[10]:= |
| Out[10]= |  |
with their meaning:
| In[11]:= |
| Out[11]= |  |
Using only titles and abstracts, we can train a NN to classify different categories:
| In[12]:= |
| In[13]:= |
| Out[13]= |  |
| In[14]:= |
| Out[14]= | 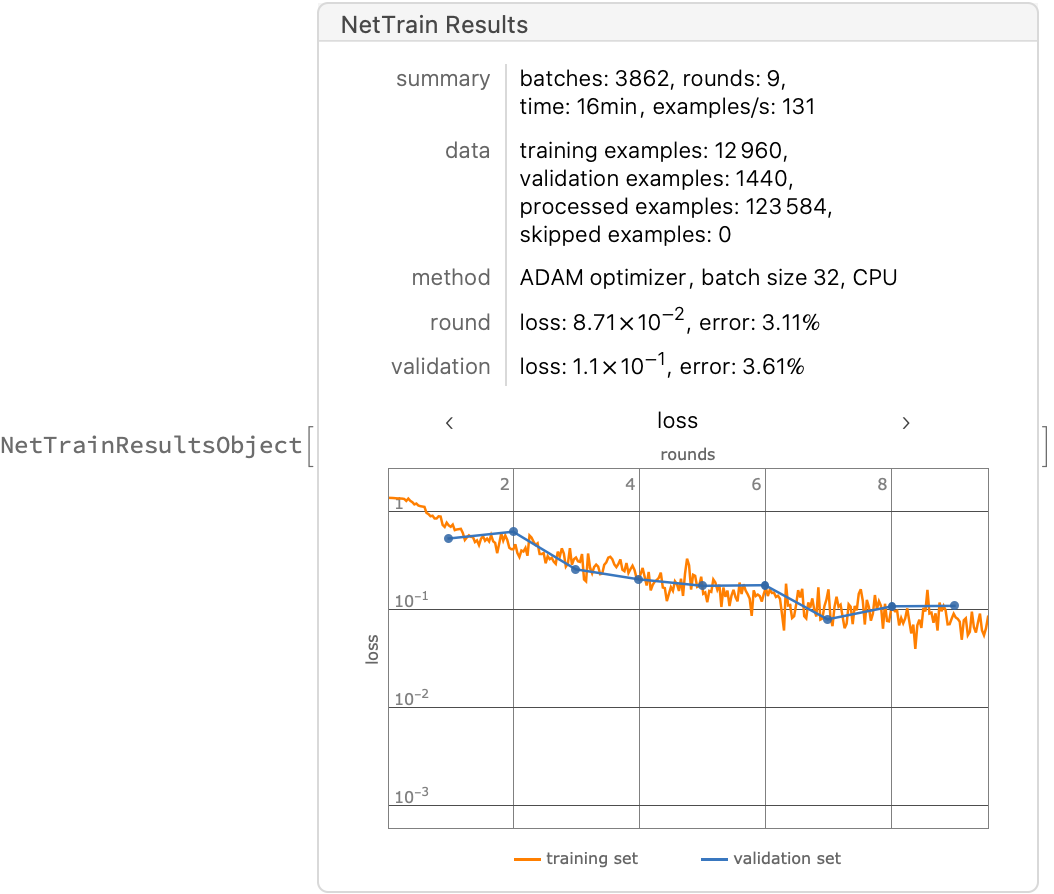 |
Even with a basic 15 minutes training on laptop CPU, we obtain 95% accuracy:
| In[15]:= |
| Out[15]= |
| In[16]:= |
| Out[16]= | 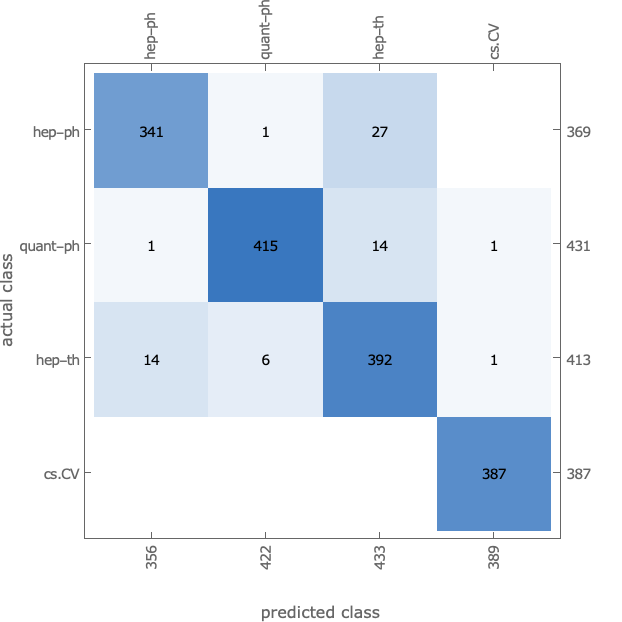 |
We could even to classify authors within the same category, with ArXivClassifyAuthorNet.
Extracting TEX introduction:
| In[17]:= |
| Out[17]= |  |
also TEX formulae:
| In[18]:= |
Explain a technical concept using an article introduction:
| In[19]:= |
| Out[19]= |  |
Let us visualize all authors with more than 7 papers in primary category "cs.NA":
| In[20]:= |
| Out[20]= | 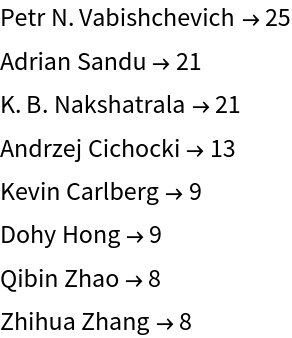 |
Let us pick a random author among them and use LLM functionality to explain his overall work:
| In[21]:= |
| Out[21]= |  |
Wolfram Language Version 14