Wolfram Language Paclet Repository
Community-contributed installable additions to the Wolfram Language
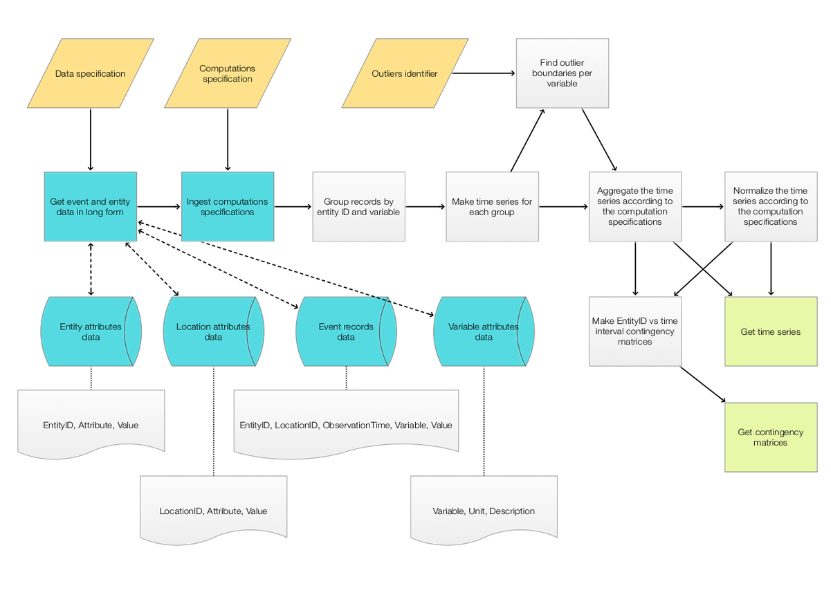
ERTMonUnit[] ⟹ | initialize the monad pipeline |
ERTMonSetEventRecords[eventRecords] ⟹ | ingest event records |
ERTMonSetEntityAttributes[entityAttributes] ⟹ | ingest event attributes |
ERTMonSetComputationSpecification[compSpec] ⟹ | ingest computation specification |
ERTMonGroupEntityVariableRecords ⟹ | group records per {EntityID, Variable} |
ERTMonEntityVariableGroupsToTimeSeries["MaxTime"] ⟹ | align the event records and create time series |
ERTMonAggregateTimeSeries | aggregate the time series(according to the computation specification) |
WeatherEventRecords |
Symbol | |
WeatherEventRecords[ citiesSpec_: {{_String, _String}..}, dateRange:{{_Integer, _Integer, _Integer}, {_Integer, _Integer, _Integer}}, wProps:{_String..} : {"Temperature"}, nStations_Integer : 1 ] gives an association with event records data. | |
WeatherEventRecords |
1 EntityID | ||||||||||||
|
2 LocationID | ||||||||||||
|
3 ObservationTime | ||||||||||||
|
4 Variable | ||||||||||
|
5 Value | ||||||||||||
|
1 EntityID | ||||||||||||
|
2 Attribute | ||||
|
3 Value | ||||||||||||||
|