Wolfram.com
WolframAlpha.com
WolframCloud.com
Wolfram Language
Example Repository
Ready-to-use examples of Wolfram Language
Primary Navigation
Categories
Astronomy
Audio Processing
Calculus
Cellular Automata
Chemistry
Complex Systems
Computer Science
Computer Vision
Control Systems
Creative Arts
Data Science
Engineering
Finance & Economics
Finite Element Method
Food & Nutrition
Geography
Geometry
Graphs & Networks
Image Processing
Life Sciences
Machine Learning
Mathematics
Optimization
Physics
Probability & Statistics
Puzzles and Recreation
Quantum Computation
Signal Processing
Social Sciences
System Modeling
Tabular Processing
Text & Language Processing
Time-Related Computation
Video Processing
Visualization & Graphics
Alphabetical List
Submit a New Example
Learn More about
Wolfram Language
Related Pages
Related Symbols
BioSequence
BioSequenceTranscribe
BioSequenceTranslate
BioSequenceModify
SequenceAlignment
ResourceFunction
Related Categories
Life Sciences
Visualize Mutations in DNA Sequences
Example Notebook
Open in Cloud
Download Notebook
For a given DNA sequence, use
BioSequenceTranscribe
to transcribe it into an RNA sequence:
I
n
[
1
]
:
=
s
e
q
=
"
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
A
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
"
;
I
n
[
2
]
:
=
s
e
q
t
r
a
n
s
c
r
i
b
e
=
B
i
o
S
e
q
u
e
n
c
e
T
r
a
n
s
c
r
i
b
e
[
B
i
o
S
e
q
u
e
n
c
e
[
"
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
A
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
"
]
]
O
u
t
[
2
]
=
B
i
o
S
e
q
u
e
n
c
e
T
y
p
e
:
R
N
A
S
e
q
u
e
n
c
e
C
o
n
t
e
n
t
:
A
U
G
A
G
G
…
G
G
G
(
3
9
l
e
t
t
e
r
s
)
Use
BioSequenceTranslate
to translate it into the corresponding peptide sequences:
I
n
[
3
]
:
=
s
e
q
t
r
a
n
s
l
a
t
e
=
B
i
o
S
e
q
u
e
n
c
e
T
r
a
n
s
l
a
t
e
[
s
e
q
t
r
a
n
s
c
r
i
b
e
]
O
u
t
[
3
]
=
B
i
o
S
e
q
u
e
n
c
e
T
y
p
e
:
P
e
p
t
i
d
e
S
e
q
u
e
n
c
e
C
o
n
t
e
n
t
:
M
R
D
E
P
Q
…
F
K
G
(
1
3
l
e
t
t
e
r
s
)
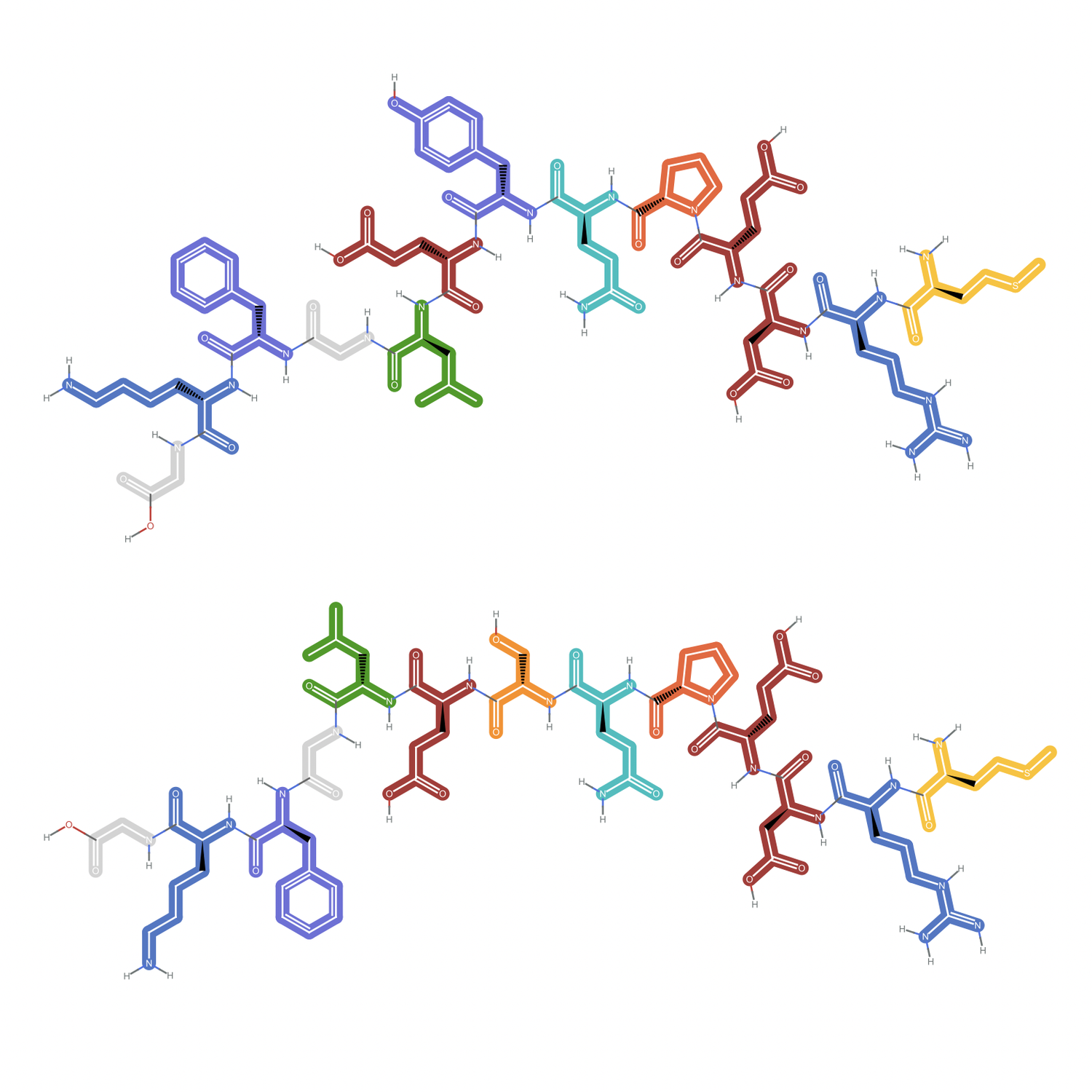
Use the
BioSequenceMoleculePlot
f
unction from the
Wolfram Function Repository
to visualize the sequence:
I
n
[
4
]
:
=
R
e
s
o
u
r
c
e
F
u
n
c
t
i
o
n
[
"
B
i
o
S
e
q
u
e
n
c
e
M
o
l
e
c
u
l
e
P
l
o
t
"
]
[
s
e
q
t
r
a
n
s
l
a
t
e
]
O
u
t
[
4
]
=
M
e
t
A
r
g
A
s
p
G
l
u
P
r
o
G
l
n
T
y
r
L
e
u
G
l
y
P
h
e
L
y
s
Introduce a single nucleotide mutation to the above sequence:
I
n
[
5
]
:
=
m
i
s
s
e
q
=
S
t
r
i
n
g
R
e
p
l
a
c
e
P
a
r
t
[
s
e
q
,
"
C
"
,
{
2
0
,
2
0
}
]
O
u
t
[
5
]
=
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
C
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
Use the
DNAAlignmentPlot
function to illustrate the letter replacement:
I
n
[
6
]
:
=
R
e
s
o
u
r
c
e
F
u
n
c
t
i
o
n
[
"
D
N
A
A
l
i
g
n
m
e
n
t
P
l
o
t
"
]
[
s
e
q
,
m
i
s
s
e
q
]
O
u
t
[
6
]
=
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
A
C
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
Translate it into the corresponding peptide sequences:
I
n
[
7
]
:
=
m
i
s
s
e
q
t
r
a
n
s
l
a
t
e
=
B
i
o
S
e
q
u
e
n
c
e
T
r
a
n
s
l
a
t
e
[
B
i
o
S
e
q
u
e
n
c
e
[
m
i
s
s
e
q
]
]
O
u
t
[
7
]
=
B
i
o
S
e
q
u
e
n
c
e
T
y
p
e
:
P
e
p
t
i
d
e
S
e
q
u
e
n
c
e
C
o
n
t
e
n
t
:
M
R
D
E
P
Q
…
F
K
G
(
1
3
l
e
t
t
e
r
s
)
Use
SequenceAlignment
to find that tyrosine (Y) is replaced by serine (S) in the new peptide sequence:
I
n
[
8
]
:
=
S
e
q
u
e
n
c
e
A
l
i
g
n
m
e
n
t
[
s
e
q
t
r
a
n
s
l
a
t
e
[
"
S
e
q
u
e
n
c
e
S
t
r
i
n
g
"
]
,
m
i
s
s
e
q
t
r
a
n
s
l
a
t
e
[
"
S
e
q
u
e
n
c
e
S
t
r
i
n
g
"
]
]
O
u
t
[
8
]
=
{
M
R
D
E
P
Q
,
{
Y
,
S
}
,
E
L
G
F
K
G
}
Visualize the sequence:
I
n
[
9
]
:
=
R
e
s
o
u
r
c
e
F
u
n
c
t
i
o
n
[
"
B
i
o
S
e
q
u
e
n
c
e
M
o
l
e
c
u
l
e
P
l
o
t
"
]
[
m
i
s
s
e
q
t
r
a
n
s
l
a
t
e
]
O
u
t
[
9
]
=
M
e
t
A
r
g
A
s
p
G
l
u
P
r
o
G
l
n
S
e
r
L
e
u
G
l
y
P
h
e
L
y
s
Now introduce another type of mutation, inserting a single nucleotide into the sequence:
I
n
[
1
0
]
:
=
i
n
s
s
e
q
=
S
t
r
i
n
g
I
n
s
e
r
t
[
s
e
q
,
"
G
"
,
2
0
]
;
I
n
[
1
1
]
:
=
R
e
s
o
u
r
c
e
F
u
n
c
t
i
o
n
[
"
D
N
A
A
l
i
g
n
m
e
n
t
P
l
o
t
"
]
[
s
e
q
,
i
n
s
s
e
q
]
O
u
t
[
1
1
]
=
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
A
T
G
A
G
G
G
A
T
G
A
G
C
C
G
C
A
A
T
-
G
A
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
A
C
G
A
A
T
T
G
G
G
G
T
T
T
A
A
G
G
G
G
Translate it into the corresponding peptide sequence:
I
n
[
1
2
]
:
=
i
n
s
s
e
q
t
r
a
n
s
l
a
t
e
=
B
i
o
S
e
q
u
e
n
c
e
T
r
a
n
s
l
a
t
e
[
B
i
o
S
e
q
u
e
n
c
e
[
i
n
s
s
e
q
]
]
B
i
o
S
e
q
u
e
n
c
e
T
r
a
n
s
l
a
t
e
:
I
n
c
o
m
p
l
e
t
e
c
o
d
o
n
d
r
o
p
p
e
d
f
r
o
m
t
r
a
n
s
l
a
t
e
d
r
e
s
u
l
t
:
G
.
O
u
t
[
1
2
]
=
B
i
o
S
e
q
u
e
n
c
e
T
y
p
e
:
P
e
p
t
i
d
e
S
e
q
u
e
n
c
e
C
o
n
t
e
n
t
:
M
R
D
E
P
Q
…
V
.
G
(
1
3
l
e
t
t
e
r
s
)
Notice that the translated sequence includes the stop codon:
I
n
[
1
3
]
:
=
i
n
s
s
e
q
t
r
a
n
s
l
a
t
e
[
"
S
e
q
u
e
n
c
e
S
t
r
i
n
g
"
]
O
u
t
[
1
3
]
=
M
R
D
E
P
Q
.
R
I
G
V
.
G
Use
BioSequenceModify
to drop the letters from the peptide sequence after the stop letter:
I
n
[
1
4
]
:
=
B
i
o
S
e
q
u
e
n
c
e
M
o
d
i
f
y
[
i
n
s
s
e
q
t
r
a
n
s
l
a
t
e
,
"
D
r
o
p
F
r
o
m
S
t
o
p
L
e
t
t
e
r
"
]
[
"
S
e
q
u
e
n
c
e
S
t
r
i
n
g
"
]
O
u
t
[
1
4
]
=
M
R
D
E
P
Q
Create the molecular diagram:
I
n
[
1
5
]
:
=
R
e
s
o
u
r
c
e
F
u
n
c
t
i
o
n
[
"
B
i
o
S
e
q
u
e
n
c
e
M
o
l
e
c
u
l
e
P
l
o
t
"
]
[
B
i
o
S
e
q
u
e
n
c
e
M
o
d
i
f
y
[
i
n
s
s
e
q
t
r
a
n
s
l
a
t
e
,
"
D
r
o
p
F
r
o
m
S
t
o
p
L
e
t
t
e
r
"
]
]
O
u
t
[
1
5
]
=
M
e
t
A
r
g
A
s
p
G
l
u
P
r
o
G
l
n
See Also
DNAAlignmentPlot
BioSequenceMoleculePlot
Related Symbols
BioSequence
BioSequenceTranscribe
BioSequenceTranslate
BioSequenceModify
SequenceAlignment
ResourceFunction
Publisher Information
Contributed by:
Wolfram Staff