Inception V1
Trained on
Places365 Data
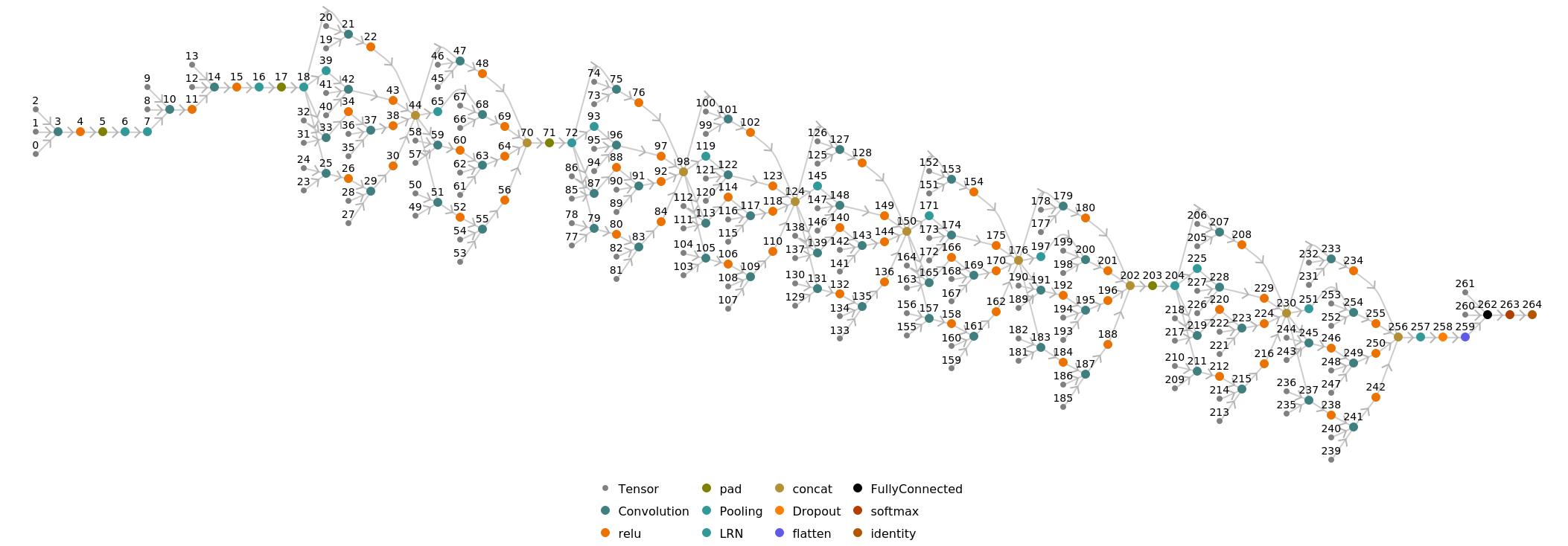
Number of layers: 147 |
Parameter count: 6,347,677 |
Trained size: 26 MB |
Examples
Resource retrieval
Get the pre-trained net:
Basic usage
Find the type of scene of an image:
Obtain the probabilities of the most likely scenes:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
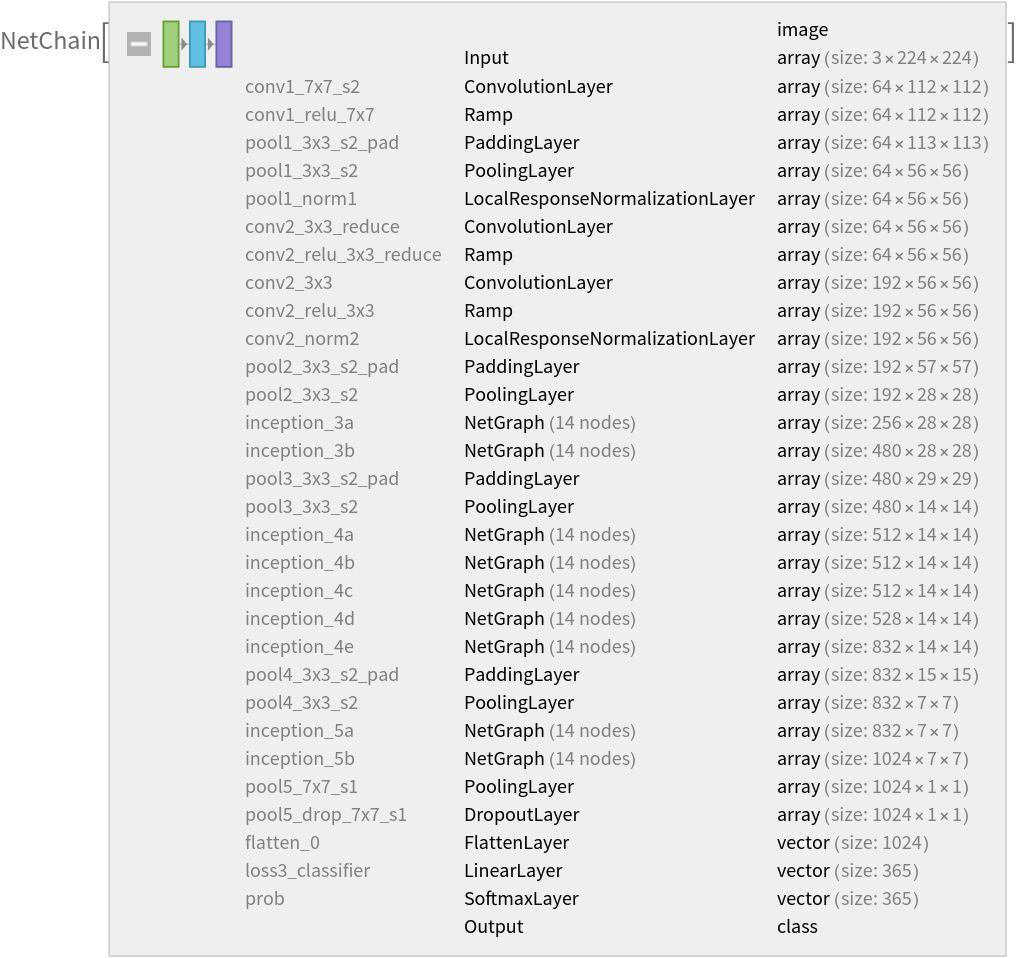
Represent the MXNet net as a graph:
Requirements
Wolfram Language
11.1
(March 2017)
or above
Resource History
Reference
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/a817913b-3304-441e-bd4b-ebb82688778d"]](https://www.wolframcloud.com/obj/resourcesystem/images/fc6/fc68fcfd-26a4-4bb5-a4c7-699590294814/28bd6cea155dbb17.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/00abde0b-d496-4d15-8a30-29e8852cda39"]](https://www.wolframcloud.com/obj/resourcesystem/images/fc6/fc68fcfd-26a4-4bb5-a4c7-699590294814/67e98d386e331abd.png)