ConceptNet Numberbatch Word Vectors V17.06
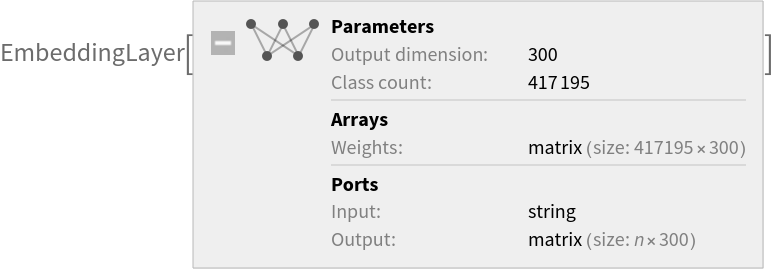
Released in 2016, these word representations were obtained by combining knowledge from the human-made ConceptNet graph and multiple pre-trained, distributional-based embeddings: GloVe, word2vec and the fastText algorithm trained on the Open Subtitles 2016 dataset. This net encodes more than 400,000 tokens as unique vectors, with all tokens outside the vocabulary encoded as the zero-vector. Underscores in the original model's tokens have been replaced with white spaces.
Number of layers: 1 |
Parameter count: 125,158,500 |
Trained size: 503 MB |
Examples
Resource retrieval
Get the pre-trained net:
Basic usage
Use the net to obtain a list of word vectors:
Obtain the dimensions of the vectors:
Use the embedding layer inside a NetChain:
Feature visualization
Create two lists of related words:
Visualize relationships between the words using the net as a feature extractor:
Word analogies
Get the pre-trained net:
Get a list of tokens:
Obtain the vectors:
Create an association whose keys are tokens and whose values are vectors:
Find the eight nearest tokens to "king":
France is to Paris as Germany is to:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
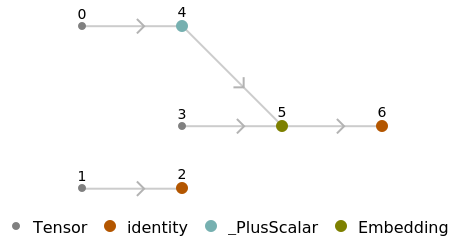
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
Represent the MXNet net as a graph:
Requirements
Wolfram Language
11.3
(March 2018)
or above
Resource History
Reference