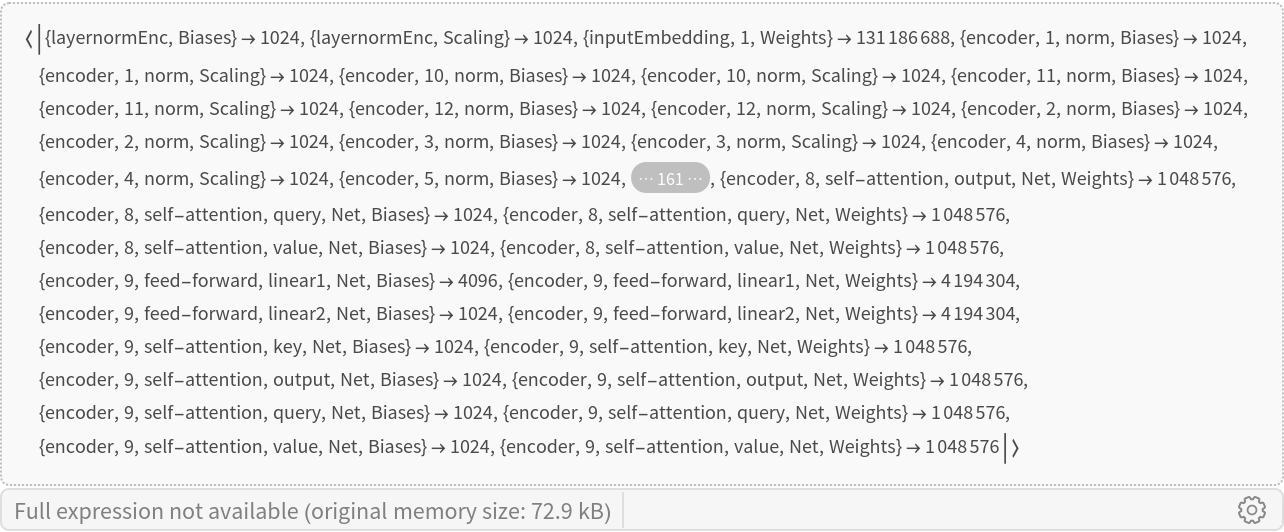
Translation procedure
The translation pipeline makes use of two separate transformer nets, encoder and decoder:
The encoder net features a "Function" NetEncoder that combines two net encoders. A "Class" NetEncoder encodes the source language into an integer code and a "SubwordTokens" NetEncoder performs the BPE segmentation of the input text, still producing integer codes:
The source language (which has to be wrapped in underscores) is encoded into a single integer between 128,005 and 128,104, while the source text is encoded into a variable number of integers between 1 and 128,000. The special code 3 is appended at the end, acting as a control code signaling the end of the sentence:
The encoder net is ran once, producing a length-1024 semantic vector for each input code:
The decoding step involves running the decoder net several times in a recursive fashion, where each evaluation produces a subword token of the translated sentence. The decoder net has several inputs:
• Port "Input" takes the encoded features produced by the encoder. The data fed to this input is the same for every evaluation of the decoder.
• Port "Prev" takes the subword token generated by the previous evaluation of the decoder. Tokens are converted to integer codes by a "Class" NetEncoder.
• Port "Index" takes an integer keeping count of how many times the decoder was evaluated (positional encoding).
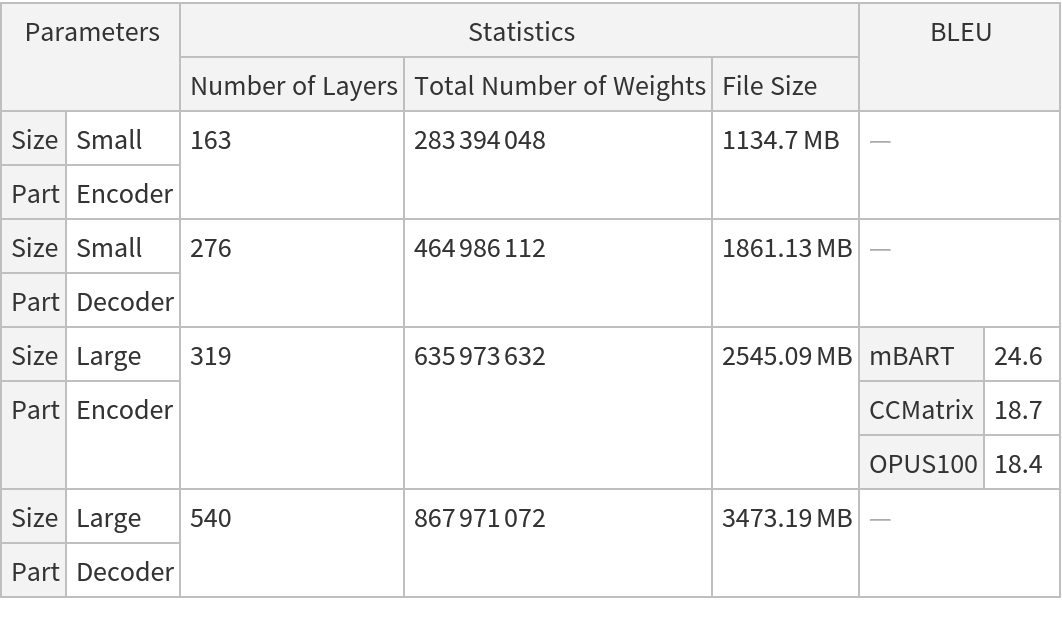
• Ports "State1", "State2" ... take the self-attention key and value arrays for all the past tokens. Their size grows by one at each evaluation. The default ("Size" -> "Small") decoder has 12 attention blocks, which makes for 24 states: 12 key arrays and 12 value arrays.
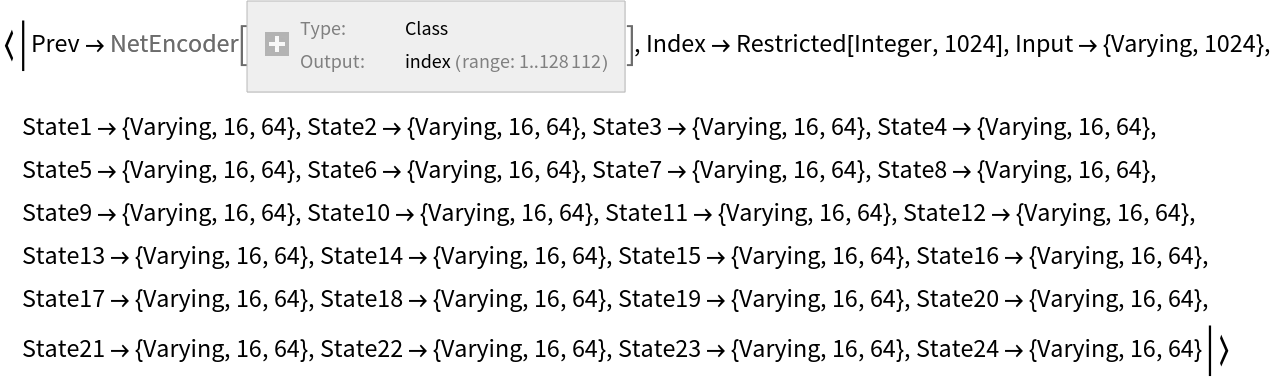
For the first evaluation of the decoder, port "Prev" takes EndOfString as input (which is converted to the control code 3), port "Index" takes the index 1 and the state ports take empty sequences. Perform the initial run of the decoder with all the initial inputs:
The "Output" key of the decoder output contains the generated token. For the first evaluation, it is a language token that has no meaning and gets ignored:
The other keys of the decoder output contain new states that will be fed back as input in the next evaluation. Key and value arrays have dimensions {16, 64}, and the value of the first dimension is 1, which shows that only one evaluation was performed:
The second run is where the first subword token of the output is generated. For this step, the "Prev" input takes the target language. It will take the previous token for all subsequent evaluations:
Check the generated token and check that the length of the output states is now 2:
The recursion keeps going until the EndOfString token is generated:
The final output is obtained by concatenating all tokens. Check the translation result alongside the starting sentence:



![decodestepfunction[decoder_, encoderOutput_] := Function@Block[
{states, ind, decoderOutput},
states = KeyMap[StringReplace["OutState" -> "State"], KeyDrop[#PrevOutput, "Output"]];
ind = #Index + 1;
decoderOutput = decoder@Join[
<|"Prev" -> #PrevOutput["Output"], "Input" -> encoderOutput, "Index" -> ind|>,
states
];
<|"PrevOutput" -> decoderOutput, "Index" -> ind|>
]](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/7c4e04bd0776e76a.png)
![netevaluate[text_, sourceLanguage_, targetLanguage_, modelSize_ : "Small", maxSteps_ : 500] := Block[
{encoderOutput, states, firstOutput, result},
$encoder = NetModel[{"M2M-100 Multilingual Translation Net", "Size" -> modelSize, "Part" -> "Encoder"}];
$decoder = NetModel[{"M2M-100 Multilingual Translation Net", "Size" -> modelSize, "Part" -> "Decoder"}];
(* Encode the input text *)
encoderOutput = $encoder[{"__" <> sourceLanguage <> "__", text}];
(* Decoder initialization step *)
states = Association@Table[
"State" <> ToString[i] -> {},
{i, Length[Information[$decoder, "OutputPortNames"]] - 1}
];
firstOutput = $decoder@Join[
<|"Prev" -> EndOfString, "Input" -> encoderOutput, "Index" -> 1|>,
states
];
(* Overwrite the first generated token with the target language *)
firstOutput = Append[firstOutput, "Output" -> "__" <> targetLanguage <> "__"];
(* Output generation loop *)
result = NestWhileList[
decodestepfunction[$decoder, encoderOutput],
<|"PrevOutput" -> firstOutput, "Index" -> 1|>,
#PrevOutput["Output"] =!= EndOfString &,
1,
maxSteps
];
StringTrim@
StringJoin@result[[2 ;; -2, Key["PrevOutput"], Key["Output"]]]
]](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/2adc2a84ca1cef2c.png)

![Sort@StringTrim[
NetExtract[
NetModel[{"M2M-100 Multilingual Translation Net", "Part" -> "Decoder"}], {"Prev", "Labels"}][[-108 ;; -9]], "__"]](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/4ef585cf71b2f3af.png)



![FeatureSpacePlot[{"__" <> First[#] <> "__", Last[#]} -> Last[#] & /@ Join[languageSentences, cookingSentences], FeatureExtractor -> NetModel["M2M-100 Multilingual Translation Net"],
LabelingFunction -> Callout]](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/75e818b11edccd28.png)



![firstOutput = decoder@Join[
<|"Prev" -> EndOfString, "Input" -> encodedFeatures, "Index" -> 1|>,
emptyStates
];](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/2ebf88d9a3007374.png)

![secondOutput = decoder@Join[
<|"Prev" -> "__Italian__", "Input" -> encodedFeatures, "Index" -> 2|>,
states
];](https://www.wolframcloud.com/obj/resourcesystem/images/f62/f6287002-1612-4bd7-9ce8-51dc792ccf15/21d0ddeb2c56aee5.png)