SlowFast Video Action Classification
Trained on
Kinetics-400 Data
Inspired by human biology, this family of video recognition models was released in 2021 and features a slow pathway, operating at low frame rate, to capture spatial semantics and a fast pathway, operating at high frame rate, to capture motion at fine temporal resolution.
Examples
Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
Classify a video:
Obtain the probabilities predicted by the net:
Feature extraction
Remove the last three layers of the trained net so that the net produces a vector representation of an image:
Get a set of videos:
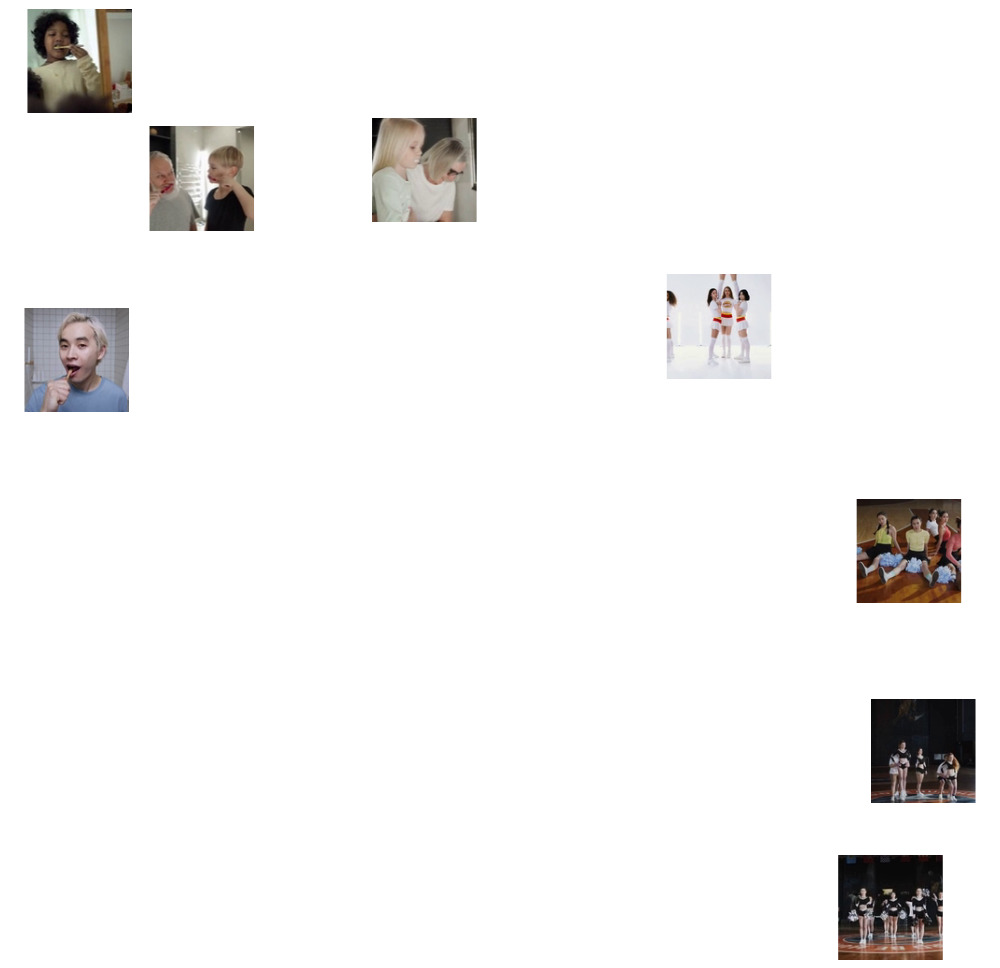
Visualize the features of a set of videos:
Transfer learning
Use the pre-trained model to build a classifier for telling apart videos from two action classes not present in the dataset. Create a test set and a training set:
Remove the last three layers from the pre-trained net:
Create a new net composed of the pre-trained net followed by a linear layer, an aggregation layer and a softmax layer:
Train on the dataset, freezing all the weights except for those in the "Linear" layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
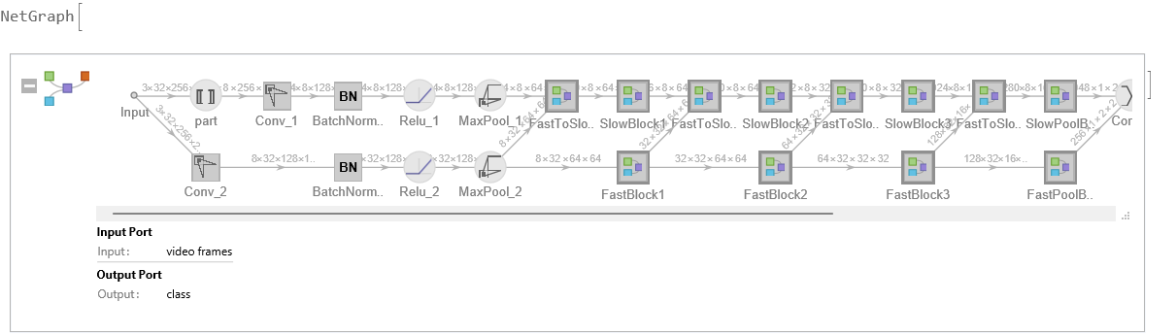
Display the summary graphic:
Requirements
Wolfram Language
13.1
(June 2022)
or above
Resource History
Reference
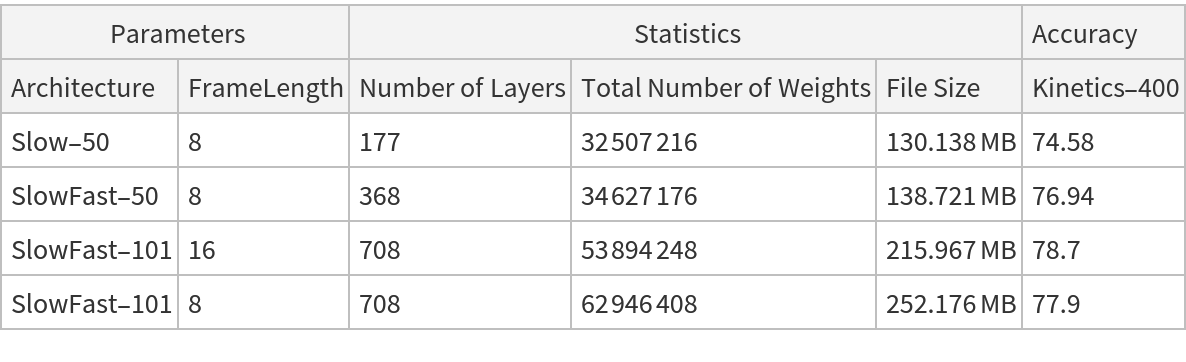
![NetModel["SlowFast Video Action Classification Trained on Kinetics-400 Data", "ParametersInformation"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/73419f0ce7dd5f1e.png)

![NetModel[{"SlowFast Video Action Classification Trained on Kinetics-400 Data", "Architecture" -> "SlowFast-101", "FrameLength" -> 16}]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/7a09aa44ae7ba58d.png)
![NetModel[{"SlowFast Video Action Classification Trained on Kinetics-400 Data", "Architecture" -> "Slow-50"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/7fe16673f8bb28d2.png)
![extractor = NetTake[NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "Transpose_1"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/78c7fe299a1dd064.png)

![videos = Join[ResourceData["Cheerleading Video Samples"], ResourceData["Tooth Brushing Video Samples"]];](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/2f4cf31086503ba0.png)
![FeatureSpacePlot[videos, FeatureExtractor -> (extractor[#] &), LabelingFunction -> (Placed[Thumbnail@VideoFrameList[#1, 1][[1]], Center] &), LabelingSize -> 70, ImageSize -> 500, Method -> "TSNE"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/5d3c09cd5b25cd0b.png)
![videos = <|
VideoTrim[ResourceData["Sample Video: Wild Ducks in the Park"], 10] -> "Wild Ducks in the Park", VideoTrim[ResourceData["Sample Video: Freezing Bubble"], 10] -> "Freezing Bubble"|>;](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/1b419b024a0a350e.png)

![dataset = Join @@ KeyValueMap[
Function@With[{frameCount = Information[#1, "FrameCount"][[1]]},
Table[
VideoTrim[#1, {Quantity[i, "Frames"], Quantity[i + maxFrameNumber - 1, "Frames"]}] -> #2,
{i, 1, frameCount - Mod[frameCount, maxFrameNumber], Round[maxFrameNumber/4]}
]
],
videos
];](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/05f288824ec52768.png)
![tempNet = NetTake[NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "Transpose_1"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/33f8b3b422d7388d.png)

![newNet = NetJoin[tempNet, NetChain[{"Linear" -> fc, "GlobalAveragePool" -> AggregationLayer[Mean, ;; -2], "SoftMax" -> SoftmaxLayer[]}], "Output" -> NetDecoder[{"Class", {"Freezing Bubble", "Wild Ducks in the Park"}}]];](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/50517923a41e0a49.png)
![Information[
NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/7d4b756783638341.png)

![Information[
NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/691fbaaca071b59d.png)
![Information[
NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/36c4daf96287ad99.png)

![Information[
NetModel[
"SlowFast Video Action Classification Trained on Kinetics-400 Data"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/ec7/ec7637f5-dd10-47bf-9977-b031d1165284/7a35a59ff9784eee.png)
