Wav2Vec2 XLSR-53
Trained on
Multilingual Data
These models are derived from the "Wav2Vec2 Trained on LibriSpeech Data" family. The XLSR family of models learns cross-lingual speech representations by pre-training a single Wav2Vec2 model from the raw waveform of utterances in multiple languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pre-training significantly outperforms monolingual pre-training.
Examples
Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter. Inspect the available parameters:
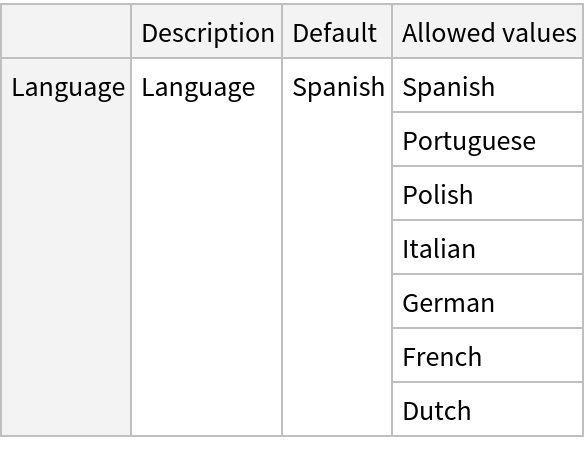
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Define an evaluation function that runs the net and produces the final transcribed text:
Basic usage
Record an audio sample and transcribe it:
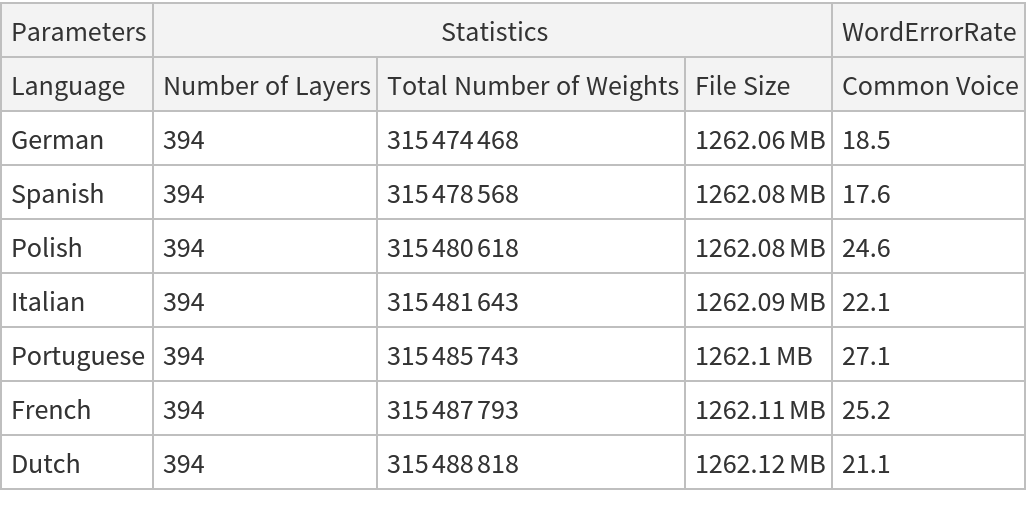
Evaluation for non-default languages
Get a set of utterances in different languages:
Get transcriptions:
Feature extraction
Take the feature extractor from the trained net and aggregate the output so that the net produces a vector representation of an audio clip:
Get a set of audio clips:
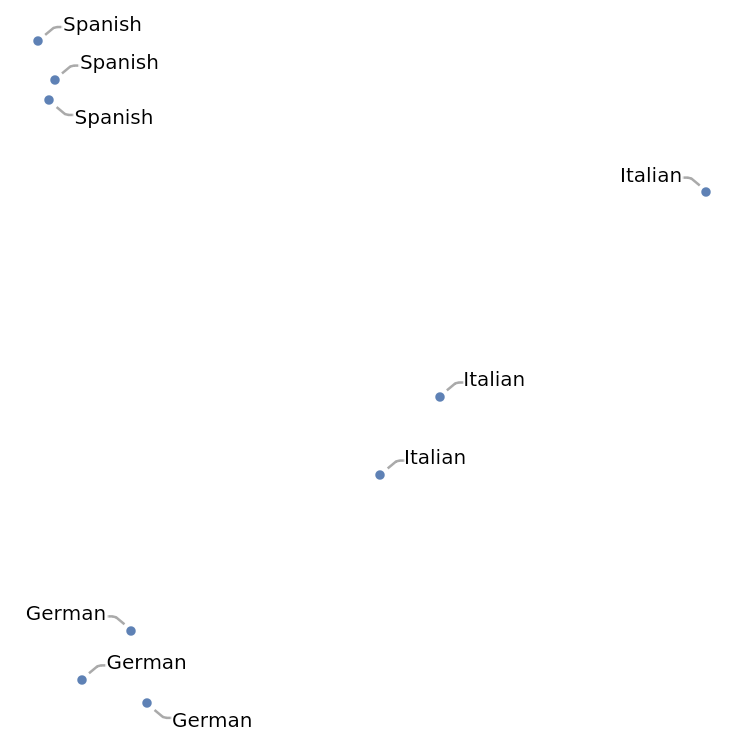
Visualize the features of a set of audio clips:
Net information
Inspect the sizes of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
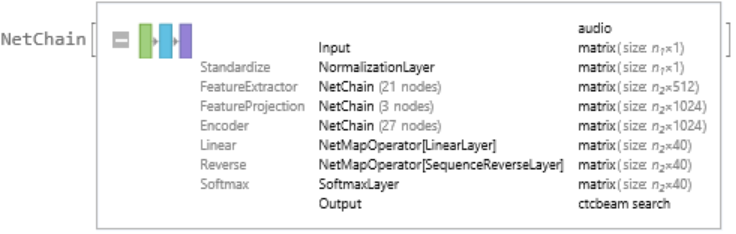
Display the summary graphic:
Requirements
Wolfram Language
13.2
(December 2022)
or above
Resource History
Reference
![netevaluate[audio_, language_ : "Spanish"] := Module[{chars},
chars = NetModel[{"Wav2Vec2 XLSR-53 Trained on Multilingual Data", "Language" -> language}][audio];
StringReplace[StringJoin@chars, "|" -> " "]
]](https://www.wolframcloud.com/obj/resourcesystem/images/e3c/e3cbdefb-6b90-4de4-8aff-35332089c00c/3b9b962f880fd3e9.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/e49d0738-cee8-4492-85dd-962e5aad5d1e"]](https://www.wolframcloud.com/obj/resourcesystem/images/e3c/e3cbdefb-6b90-4de4-8aff-35332089c00c/4f8c2915b25860d5.png)

![extractor = NetAppend[
NetTake[NetModel["WWav2Vec2 XLSR-53 Trained on Multilingual Data"], "FeatureExtractor"], "Mean" -> AggregationLayer[Mean, 1]]](https://www.wolframcloud.com/obj/resourcesystem/images/e3c/e3cbdefb-6b90-4de4-8aff-35332089c00c/5a42918b9881cddf.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/a5ac5c20-e5f1-4ac4-9cc3-9afa937e6640"]](https://www.wolframcloud.com/obj/resourcesystem/images/e3c/e3cbdefb-6b90-4de4-8aff-35332089c00c/1865b0fd9c21fc7d.png)