Wav2Vec2
Trained on
LibriSpeech Data
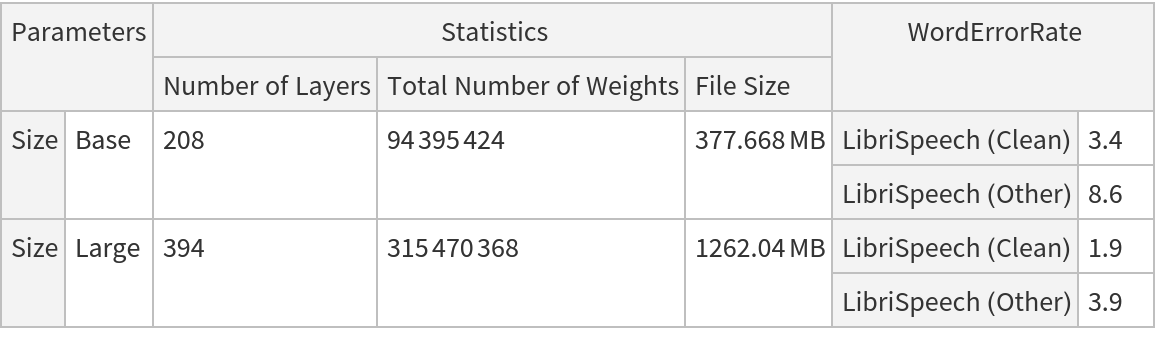
This family of models was trained using self-supervised learning in order to learn powerful representations from speech audio alone, followed by a fine-tuning on transcribed speech. At training time, Wav2Vec2 encodes raw speech audio into latent speech representations via a multilayer convolutional neural network. Parts of these feature representations are then artificially masked and fed to a transformer network that outputs contextualized representations, and the entire model is trained via a contrastive task where the output of the masked data at masked time steps is penalized for being distant from the true representation. Wav2Vec2 achieves state-of-the-art performance on the full LibriSpeech benchmark for noisy speech, while for the clean 100-hour LibriSpeech setup, it outperforms the previous best result while using 100 times less labeled data.
Examples
Resource retrieval
Get the pre-trained net:
NetModel parameters
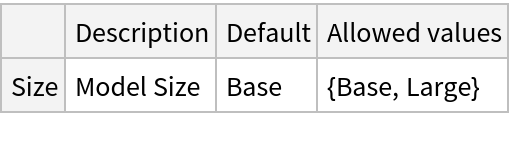
This model consists of a family of individual nets, each identified by a specific parameter. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Define an evaluation function that runs the net and produces the final transcribed text:
Basic usage
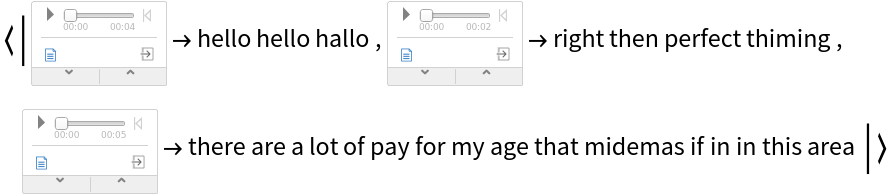
Record an audio sample and transcribe it:
Try it over different audio samples. Notice that the output can contain spelling mistakes, especially with noisy audio. Hence a spellchecker is usually needed as a post-processing step:
Feature extraction
Take the feature extractor from the trained net and aggregate the output so that the net produces a vector representation of an audio clip:
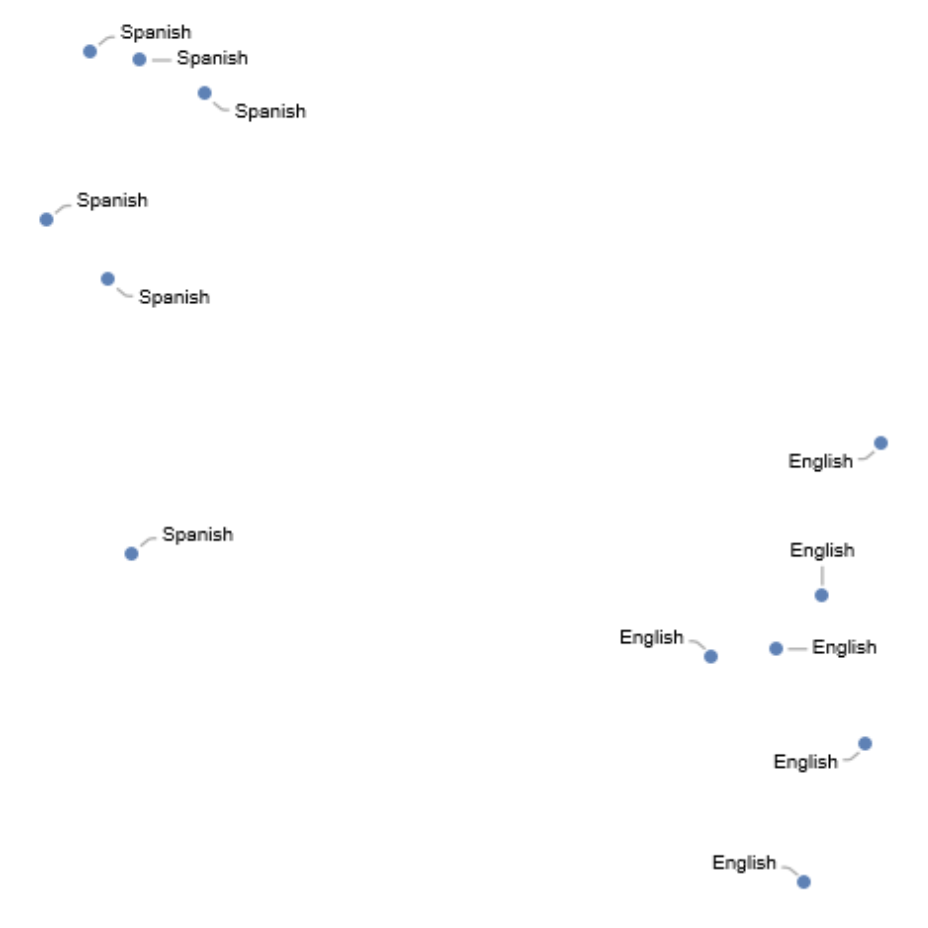
Get a set of utterances in English and Spanish:
Visualize the utterances in feature space:
Net information
Inspect the sizes of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Requirements
Wolfram Language
13.2
(December 2022)
or above
Resource History
Reference
![netevaluate[audio_] := Module[{chars},
chars = NetModel["Wav2Vec2 Trained on LibriSpeech Data"][audio];
StringReplace[StringJoin@chars, "|" -> " "]
]](https://www.wolframcloud.com/obj/resourcesystem/images/dee/dee14dce-11ca-4913-a1a7-0773b924a858/1c79bb51483a12ff.png)
![extractor = NetAppend[
NetTake[NetModel["Wav2Vec2 Trained on LibriSpeech Data"], "FeatureExtractor"], "Mean" -> AggregationLayer[Mean, 1]]](https://www.wolframcloud.com/obj/resourcesystem/images/dee/dee14dce-11ca-4913-a1a7-0773b924a858/7a7a41050f7c654f.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/7f452647-8ab1-4beb-a361-2eb460ae4984"]](https://www.wolframcloud.com/obj/resourcesystem/images/dee/dee14dce-11ca-4913-a1a7-0773b924a858/7d8276803b228527.png)