Resource retrieval
Get the pre-trained net:
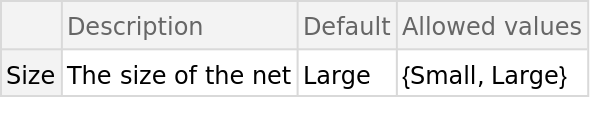
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default model by specifying the parameters:
Pick a non-default untrained net:
Basic usage
Identify an Audio object:
The prediction is an Entity object, which can be queried:
Get a list of available properties of the predicted Entity:
Obtain the probabilities of the ten most likely entities predicted by the net:
The probabilities do not sum to 1 since the net was trained as a collection of independent binary classifiers, one per each class. This reflects the possibility of having multiple sound classes in a single recording.
The network was trained on the AudioSet dataset, where each audio signal is annotated with the sound classes/sources that are present in the recording. The labels are organized in an ontology of about 632 classes that span a very wide domain of sound types or sources, from musical instruments and music types to animal, mechanical and human sounds. Obtain the list of names of all available classes:
Feature extraction
The core of the network takes a fixed-size chunk of the mel-spectrogram of the input signal and is mapped over overlapping chunks using NetMapOperator. Extract the core net:
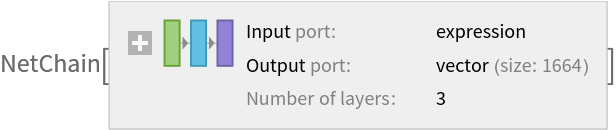
Chop off the last few layers in charge of the classification:
This net takes a single chunk of the input signal and outputs a tensor of semantically meaningful features. Reconstruct the whole variable-length net using NetMapOperator to compute the features on each chunk and AggregationLayer to aggregate them over the time dimension:
Get a set of Audio objects:
Visualize the features of a set of recordings:
Transfer learning
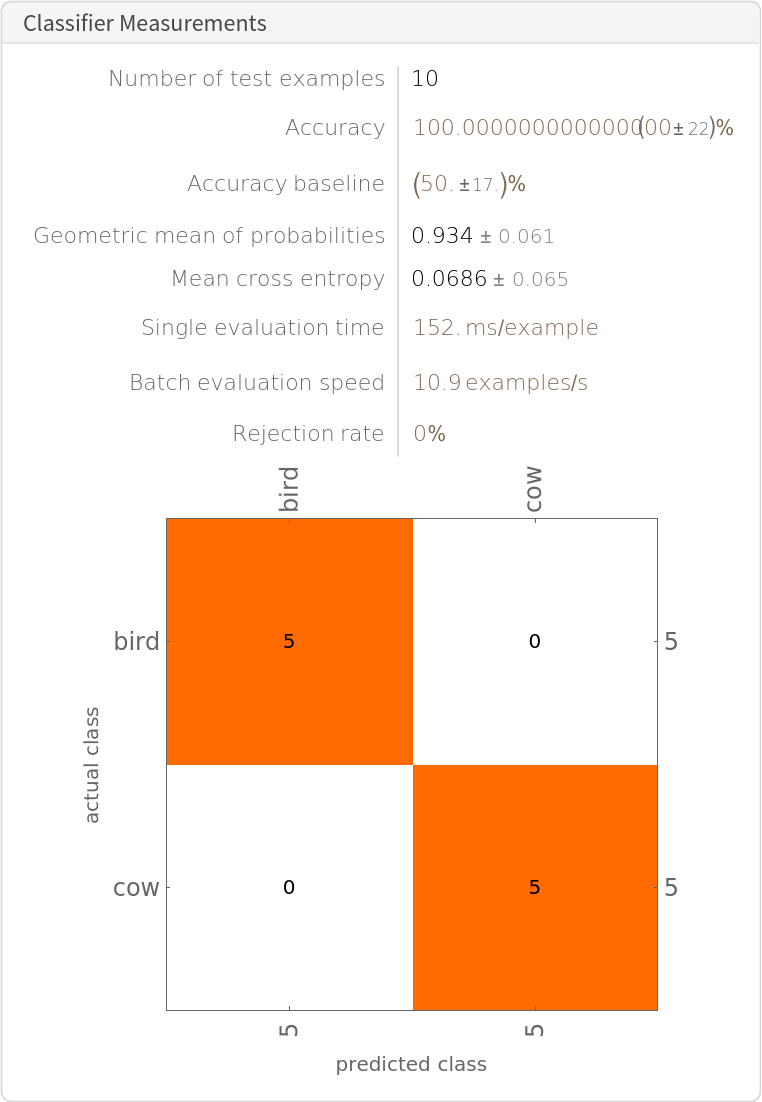
Use the pre-trained model to build a classifier for telling apart recordings of cows and birds. Create a test set and a training set:
Remove the classification layers from the pre-trained net:
Create a classifier net using a simple LinearLayer:
Precompute the result of the feature net to avoid redundant evaluations. This is equivalent to freezing all the weights except for those in the new classifier net:
Train on the dataset (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:


![NetModel[{"Wolfram AudioIdentify V1 Trained on AudioSet Data", "Size" -> "Large"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/196973703bece726.png)


![EntityValue[
NetExtract[
NetModel["Wolfram AudioIdentify V1 Trained on AudioSet Data"], "Output"][["Labels"]], "Name"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/34d1ee3eb9dfc3a3.png)

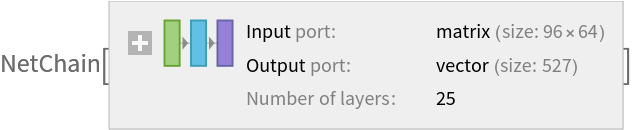

![extractor = NetChain[{NetMapOperator[singleFrameFeatureExtractor], AggregationLayer[Max, 1], FlattenLayer[]}, "Input" -> NetModel["Wolfram AudioIdentify V1 Trained on AudioSet Data"][[
"Input"]]]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/570487725b376325.png)
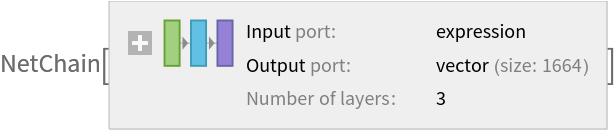

![featuresNet = NetChain[{NetMapOperator[
NetDrop[NetExtract[
NetModel[
"Wolfram AudioIdentify V1 Trained on AudioSet Data"], {1, "Net"}], -3]], AggregationLayer[Max, 1], FlattenLayer[]}, "Input" -> NetModel["Wolfram AudioIdentify V1 Trained on AudioSet Data"][[
"Input"]]]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/3f7125e23fab32de.png)
![NetInformation[
NetModel[
"Wolfram AudioIdentify V1 Trained on AudioSet Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/11932276e6bf1e79.png)

![NetInformation[
NetModel[
"Wolfram AudioIdentify V1 Trained on AudioSet Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/56f8031e52a23afd.png)
![NetInformation[
NetModel[
"Wolfram AudioIdentify V1 Trained on AudioSet Data"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/56a473799a763825.png)
![NetInformation[
NetModel[
"Wolfram AudioIdentify V1 Trained on AudioSet Data"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/42a05ab015cd83a7.png)
![jsonPath = Export[FileNameJoin[{$TemporaryDirectory, "net.json"}], NetModel["Wolfram AudioIdentify V1 Trained on AudioSet Data"], "MXNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/6c87c2b1ee6a1e6f.png)