Wav2Vec2
Trained on
Multiple Datasets
These models are derived from the "Wav2Vec2 Trained on LibriSpeech Data" family. They explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which may differ from the test data domain. The results show that pre-training on multiple domains improves generalization performance on domains not seen during training. The models are pre-trained using a single large Wav2Vec2 model on four domains (Libri-Light, Switchboard, Fisher and Common Voice) and fine-tuned on the LibriSpeech and Switchboard datasets.
Examples
Resource retrieval
Get the pre-trained net:
NetModel parameters
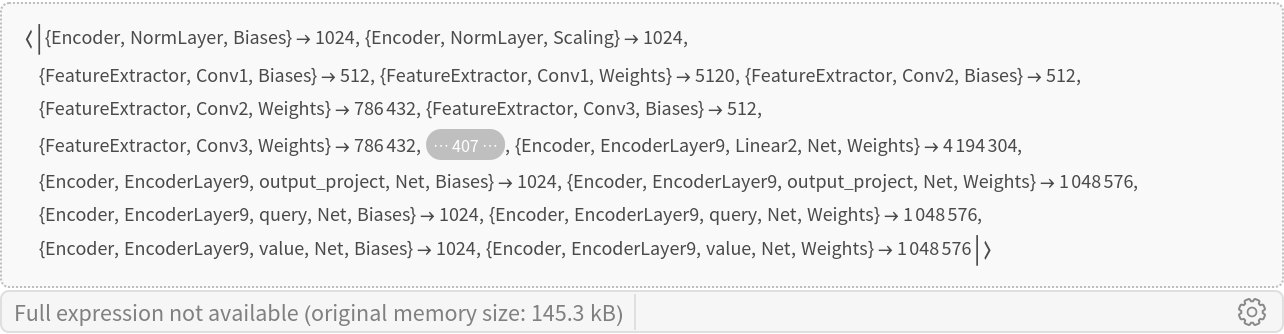
This model consists of a family of individual nets, each identified by a specific parameter. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Define an evaluation function that runs the net and produces the final transcribed text:
Basic usage
Record an audio sample and transcribe it:
Try it over different audio samples. Notice that the output can contain spelling mistakes, especially with noisy audio. Hence a spellchecker is usually needed as a post-processing step:
Feature extraction
Take the feature extractor from the trained net and aggregate the output so that the net produces a vector representation of an audio clip:
Get a set of utterances in various languages:
Visualize the features of a set of audio clips:
Net information
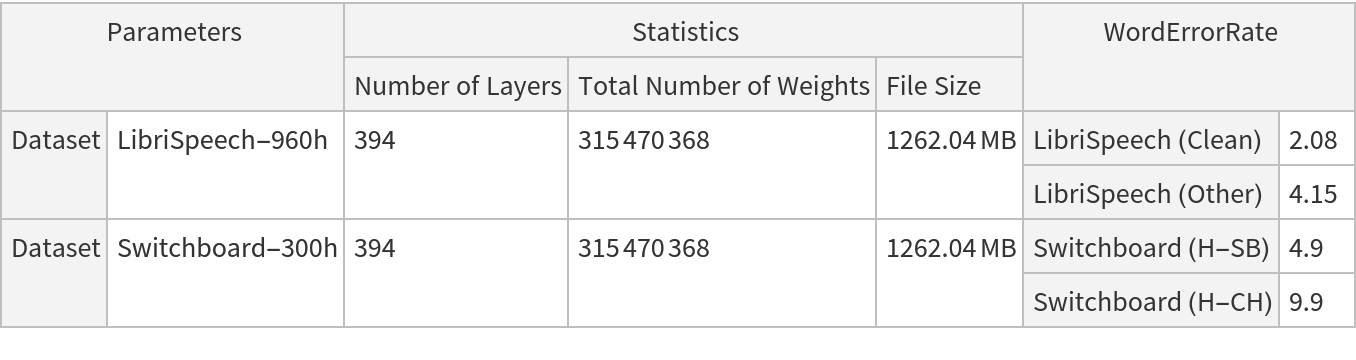
Inspect the sizes of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
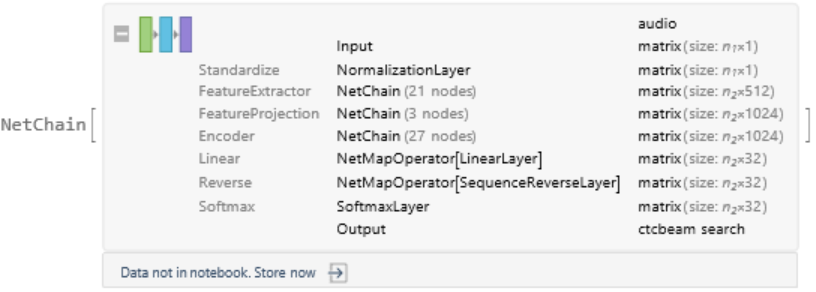
Display the summary graphic:
Requirements
Wolfram Language
13.2
(December 2022)
or above
Resource History
Reference
-
W.-N. Hsu, A. Sriram, A. Baevski, T. Likhomanenko, Q. Xu, V. Pratap, J. Kahn, A. Lee, R. Collobert, G. Synnaeve, M. Auli, "Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-training," arXiv:2104.01027 (2021)
- Available from: https://github.com/facebookresearch/fairseq
-
Rights:
MIT License

![netevaluate[audio_] := Module[{chars},
chars = NetModel["Wav2Vec2 Trained on Multiple Datasets"][audio];
StringReplace[StringJoin@chars, "|" -> " "]
]](https://www.wolframcloud.com/obj/resourcesystem/images/d2a/d2a66024-522f-464b-bdaf-f0054d95e3fc/7840fb030f9232e1.png)
![extractor = NetAppend[
NetTake[NetModel["Wav2Vec2 Trained on Multiple Datasets"], "FeatureExtractor"], "Mean" -> AggregationLayer[Mean, 1]]](https://www.wolframcloud.com/obj/resourcesystem/images/d2a/d2a66024-522f-464b-bdaf-f0054d95e3fc/16397244825e015f.png)
![\!\(\*
GraphicsBox[
TagBox[RasterBox[CompressedData["
1:eJzsved322ba/5ktL/bl/gH7Zk/e7h+w+3LPnhO3OL1nZvJkJnHGyTPJTPJk
yjOZlhlP3GR1yzWWq9xLZFuy7MRFbmrsVRJFUqIoiVRvpERK2Eu8Y/wQEoRA
AARg8fs5OjoUSELghetz3/d1AwT+z19+9sqW//mZZ5754n+jX6+8/4f/9/PP
3//Tq/87/fH6p19s/ejTDz/Y8Ol/ffjRh5//37/8X2jh4P/0zDP/+F+feWbl
MQcAAAAAAAAAAAAAAAAAAAAAMCtTU1OBQMAOwBOcTidlhdGJaXYgDhACa+QA
a4AQWCMHWAOEwJo1A+1Hh8MRj8eN3hBgItLpNGUFmW70hpgXiAOygDWrAmtA
FrBmVWANyALWrBmwE0E+kBsSIDhAFCSGBAgOEAWJIQGCA0RBYqwBsBNBPpAb
EiA4QBQkhgQIDhAFiSEBggNEQWKsAdTvxJlEKr20rMnGAFMBwSVQGZy5ZHox
DWvWILBGApXBSS4uJRaXtNoYYB5gjQQqg5NKL88m08vL6G7WGrBmDaB+J17o
GO4KTqZQha05ILgEKoNzyzXa6h+fX8B4cq0BayRQGRxrePq6LT42s6jV9gCT
AGskUBmcgbHE+fbhwfGkVtsDTAKsWQOo34k7rgZ+fcTrjMwuYZpFX/r6+sbG
xkRnt1Kp1MTEhMqJLwgugcrg1N+LfPit5wfPeArHwvRlYGBgZGQknU7nPkUL
yRpyR836YY0EKoNDvmw54jn1cGgBx8L0hZSJRCILCwu5Ty0tLc3MzCQSCTXr
hzUSqAxO9/DcJ8d8e5rCswlVLRsolMnJyVAoND8/n/sUjc1mZ2fn5ubUrB/W
rAHU78SalvCmav8nx7xkuiabBGTicDii0WhunUUjSRI/GAxS56hm/RBcApXB
Ofs4+lKN971Dnke9EziArCc+n4/UWFzMPpJCHtEgs6+vT3ScKR9YI4HK4Nz3
j79zwPf6XnejZQRnv+tJOBzu7u4WrbNisVhvby9VYWrWD2skUBmcwMjclnrv
5mrPodv9Scxd6Eg8Hne73dPT07lPUXUWCATGxsbUrB/WrAE0KMFuhl+ocm6q
6f79GX8ormoqDBSEaAmWSqWo/rJYLCQ4SrDioTI459qGXq91Pb83sLXeYw2J
NNGgSFAJRoJklWBkyuDgoM1m8/v9yaSqM3ZgjQQqg9PqH/vFATdZ87P9zpuu
UZx3oRv9/f1UguXO59Mgk7ohGmeiBCseKoPTOzy39aj3+dqel6vtpx5GF1Ko
wnQiXwlG9ZfH43E6nSjBgCYl2IvVzud2dm6s8v75XPfgeAFV2DP/7c/6Ubkx
JQX1fTRuFJZgNLAMBoM0kuzq6urr60MJVjw0KMH2utaVWcma3xzzugYKqMJg
jRqoyMoqwVKpVCQSIZs6OztpnImjYMVDgxLsoHtDuWNDhesX+x13PKPy3wtr
1EAlWE9Pj/AoGHUuIyMjNIwka2g8OTs7q2b9sEYC9SXYr+s9Gyvd68tsr1bZ
zrVFC5q7gDiKYSWYcHaCRmtUdnm9XhqhoQQDnGYlmGvdzo51Ozo2Vnq2Xekd
npQ7jQy71ZBVgtGosre312KxUPFFfSJKsKKiSQm2frf1uR3tGyu9X572+Yfk
jmFgjRqySrB0Oh0Oh61WK7lDPSNKsKKiRQnmoRLsuR1tGytcHx52Pu6dkPle
WKOGrBKMepahoSHamz6fj5Qhp0TPtpIPrJFAqxKMrNlQZnu92nrdHpNfhEEc
xeSWYFRzUeXlcrlYdzM6WsAkUi6wZg2gXQnWSYNJ+r2xwr3zal9c3kWrYLca
WAnG6qxkMkldJNVfNLxkj8lxlGDFQ5sSrIxKsLYVayo9fzrjD4zI+jYlrFED
K8HYNTeoEOPrr7m5uWAwSONJnIhYPDQqwZzPbW97bmfHxgrnx/Xurr4pOe+F
NWpgJRg7ETGdTkejUZvNRvUXVV5Ui6EEKyqalWBkzY72DXts79Y5bjrjMt8O
cRQjPBFxeXmZ/mT11/j4ODsWRkvUrB/WrAG0LcFYFUZd5L7v+8dnV6/CYLca
WAlGDxKJBHWCVH8NDAzQqJJkRwlWbLQrwdr5uYt/fxfoH139PF5YowYaN1LZ
RWosLCwEAgGqv/r6+tjYkkozlGBFRbMSLGMNq8J+d9Lriqw+/oc1amAlGKlB
4lAvQ9aQKWx6n0owVoupWT+skUDDo2BMHKrC3tvvuO+XdRYcxFEMK8HYObrD
w8O0Hz0eD9Vf9OfExARKMMAVoQRbGU/uttDY8tCdgVWrMNitBqfTSd0fCU69
oc1mY/UXl5lvoSUowYqKtiXYijW7ujaUO3Ze6xsYW6UKgzVq8Pv9NJ6k0WMw
GKSRJJVd/OlVOApWbDQuwVas6SRr/nDG742uch4vrFEDKUMdCtVZkUiEdiKV
Y/zpVSjBio3mJdi6nR0b9tg/POxqC0yuekYixFEMVVhUZ1G1NTIy4nA4qP6i
x+wpKsRwIiLgilOCPbe9bX2ZjYaXN51x6dsewW41uFyuvr4+EtlisVDPyN/P
iCovlGDFRvMSjKxZt9u6ocJ14sGg9C2bYY0amBrsqDHVXMKCCyVYsdG8BFs5
j3dXF1mz61rf2KzUl/hgjRoGBgaozqLKy2q10m/h/YxQghUbzUuwzBHklbOV
Pj/li4yJ3LVKCMRRDFVYbrc7EAiw41+Tk5P8UyjBAKMoR8F2dq7fbfnVQUd7
YCIlefeWXLs9QIB05J1OJ5ucZNc/5K8wgBJMB7Q/CrZijfVndfYmeywped1g
WCONdORJjWAGm82WdZ1tlGDFRvsSbGfHujLrG7X2Ew8Gp+alTrqANdJIR55d
lD4UCtEepFGlcDCJEqzYFKEE61i32/Jylb3iRig2tUpzB3GkkQgdK8HIHfpN
ozXhaYcowQCjKN8FK7P/9qTPPbj6jUJy7R6KxfDDfqTt5jIlWDQapREjO6Uq
EAiw0SNKMB3QuATLWLPliPd+9/iqt5yFNWqsYZfjSCQS/I3A+OtpowQrNpp/
F2x9me1n+5yXOoYWJU+34GCNOmvC4TC7ZE0sFqN+xyM4pQolWLHRugSj+sv6
eq3jwA/h2WR61bdDHMXiUM3lyRz8IlmoCnM4HCMjI+wS1ijBAEPjKyLu6tpQ
ZvuywRceXeXoNgMTLNJIR4/dmpkeLCws0OjRYrFQL8m+2ILLcRQbba+ISA8+
PuqxhhRe283oPDUX0tFjl+NIZ4hEIuzCbuyLLbgcR7HR9oqIZM37h9wtrviy
jEtswxpppKPHjoIxNdjtwGhIyS4sMDw8TINJlGDFQ8srIpI1uy1v1zlPPBxM
rzrZlwHiSCMROuEVEUkWeky7knyh9orqMlyOA3DalWDP7exct6vz+XL7X88X
cHdmnGasBuF9wRYXF6mX5C9URSVYIBBACVY8tLovGKu/Pj/pk393ZlijBuF9
wfjbG1FvODU1hRKs2Gh2X7BM/fXREc9dr9x7m8IaNQjvC0bW8JfXHh0djUaj
ZA1KsOKh3VGwlUul/fyA63x7FPcF0wHhfcH4sov2JilD4vh8PpRgQKsSbP1u
26Y91m1XesdnU/LfC7vVkHVr5nQ6TX9SFUZqU+eIEqyoaFKCbdjjWL/b8ocz
Ppl3BGPAGjVk3ZqZ9BkeHmaXq6LuksaZuDVz8dCiBHPTYHLdrq7/POZtk31f
Zg7WqCPr1sxkDZvVp46GfuNExKKiTQlW5SVr3j/ovmodKejtEEcxWbdmJmtI
E5KFXZ2DGBuTO4MkCqxZA2hQgrWENle5N1c69jT1TUp+IToX2K2GrBKMy1Rh
Q0NDNputq6srGAyiBCse6kuwV2vdVIL9/WJPeLSA+ouDNerIKsG4JzfNpMEk
WdPd3Y0SrHioLcF8Yz874KbB5Oen/PZwYWN+WKOGrBKMwWb1Ozs76Tf/hUpl
wBoJVJdgs7+u926q6d5yxPO9q+AvH0EcxWSVYAx2khL1NU6nEyUYUL8TK5r7
Xqv17L01IH0ZN1FgtxpI4awSjHtybpXFYsFRsKKiMjgNjwbf2Ove9l1wZKrg
AT+sUQOVYOFwWFiCcZkqbHR0lPYpPYsSrHioDM5d78qJiP91uscfXf1aT1nA
GjWQMrklGJepwtwZssaZhQJrJFAZnO7h2Y/qvR/W+x90KxnwQxzFiJZgxNzc
XHd3N+1WlGBA/U48eGfg8J3wXLKA8w95YLdiaNBotVqpBMuts2jJyMgIdZoo
wYqHyuBc7ByuaQkOTcj91qQQWKMGj8cjvIODkFgsFgqFUIIVD5XBedA9Xt7c
54ooOecN1qghGAz6/X7hHRx4pqamqK/BiYjFQ2VwAiNzu6/33fMrHO1DHMWw
y4eSILlPzc7O9vf344qIQP1O7B9NyLuyDtASKsFIcBJZ9Gpg6XSauks5FwqT
AIJLoDI4Q5PJxKKqAhkoY2xsjPpE0dkJWkjWkDtq1g9rJFAZnPHZRfrRamOA
fEiZ8fFxUTWol0kkEqmUkjlYHlgjgcrgzC2khydVXWIIKGNubi4ej+eb06Pl
uPQTwE58eqERo8oiSxrkhgQIzlMKs6Z44iAxJEBwnlLIF4lzKtQLhcSQAMF5
SmHWoK8BEphhJzqdzqYMPT09/MLbt2+zhVq9pdho8inoQdMT6L06bLYEZsgN
02J4cGANrHnqMDw4sCbXGsOV4UyQGGbGDMEpNOVMaI3iraKnIpGI/NfrhhkS
A6jE8J1Iuc2SeXJykh7Qb3rclYHLKPPw4UP1b3nqPoUZMDw3zIyxwYE1sOZp
BNaY5FOwB+xZer3h+sAaCQwPTqEpZ0JrFG8Vq7b4EszwTyHE8MQA6jF8JwqH
T5TSlNicYNqBl4WW8y+T+Zan8VPQA+H8jLEYnhtmxtjgyFeAT7mn15pVPwWs
eVqANeb5FDwYTJocw4NT6PDGhNYo+BSsZGMHi/kSzPBPIcTwxADqMXwnCnsE
5khWbmcdBVb2lmKjyafgBMe4DbebM0FumBljgwNrOFjzFAJr1KOVNaLPGgWs
kcDw4BSacia0RvFWsdeIll2GfAohhicGUI/hOxHdYtZb2MvYScs6fgIRDM8N
M4PBpHpgTakBa9SjYQnG5vkxcWFyDA8OSjCUYKBIGL4T0S1yYjOTom/RGcNz
w8xgMKkeWFNqwBr1aG4NK8RwSpVpMTw4KMFQgoEiYfhOFPYIMk8bVvCWp+VT
CIHgZuZp+VaLmrc8LZ9CCKwxM7DGPJ9CCKwxM4YHp9CUM6E1irdKWILJeb2e
GJ4YQD2G70RcpYp/C7+EvcXwawUbnhtmBtd2M8mngDVPEbDGJJ8iyxqcvmtm
DA9OKV8RMasEM/xTCDE8MYB6zLAT5dysQXgtQZlv0RlNPoXwDkd6brwoZsgN
02J4cGQqIEy5p9QabrVPAWueFgwPDqwRtQbfBTMzZghOocMbE1ojc6uyBmlZ
JVju6w3EDIkBVIKdCPKB3JAAwQGiIDEkQHCAKEgMCRAcIAoSYw2AnQjygdyQ
AMEBoiAxJEBwgChIDAkQHCAKEmMNgJ0I8oHckADBAaIgMSRAcIAoSAwJEBwg
ChJjDYCdCPKB3JAAwQGiIDEkQHCAKEgMCRAcIAoSYw2AnQjygdyQAMEBoiAx
JEBwgChIDAkQHCAKEmMNgJ0I8oHckADBAaIgMSRAcIAoSAwJEBwgChJjDYCd
CPKB3JAAwQGiIDEkQHCAKEgMCRAcIAoS4ymltbX1mQz0ADsR5AO5IQGCA0RB
YkiA4ABRkBgSIDhAFCTGUwoVXw0NDewxdiLIB3JDAgQHiILEkADBAaIgMSRA
cIAoSIynkdbW1meffZb/EzsR5AO5IQGCA0RBYkiA4ABRkBgSIDhAFCTG04ji
EswO1hAy97iSDCsN5McQrBk0TIzSRH4MwVpCq8QoTWQGx+idDDRGq8QApgJH
wYBMkBsSIDhAFCSGBAgOEAWJIQGCA0RBYijjdzv7nvm/WjtcM+zPM81x+pMW
6vPfUYIBmajMjWeeeWbr1q0NDQ30IBAIaLJJX3755ZYMNTU1wuU9PT25C+Wj
YFMhDhAF1kgAa4AosEYCWANEMaE16tFhq0RLsDe+8Bbjf+WCEgzIRGVuUJrt
2LFDqBJ1W1sEbNu2jb3ywYMH9GdjY6Oc1Yr2gGwhv0L1m7oqEAeIAmskgDVA
FFgjAawBomhuDUFq8NbI1ERbFAhSKFklmM6gBAMy0URwdgcE4XLqvL788kvh
EvXdokrybaoEEAeIAmskgDVAFFgjAawBomhuzfHjx4V2UOaTAmq3UvVWSbC7
PkLFFP/DqiphhfXGF156zF7Mlme9+P/4/9rZn8KjYPQU/7L/510bv1z4dsUf
ECUYkMmqucHf2qAgsrrFLT+FPcX6PtHZmNxukVaYNdXJ/XQWlP939AJazp9h
Qt2xgu1nQBwgCqyRANYAUeQkhgJxYA1Yw2huTb4JB1aaCTOZqUGyMCNY2m/L
wP5kD+iNnMAaoTj0GuFq1dd6VEyxckm0BGPFGv3mco6CsYKLL8GEfwq/JkYr
p3+R77/zd1vmyfdK2iPr1q3j/4TdIB/SucFSTphLMil0ZpJ1cPyf+WYmt+Q5
OYS9XtgUsH+U7/UygThAFFgjAawBoqyaGMrEgTVgDaOtNcLsFcJOTWQlEiua
OMHpuA8yCMsxfj0kTlbaC+1jsxO0ROWxZv4wFv2wEkm0BBMWUNIlGCvWqPji
1y+s7FR+a2zr1q3C+zJzsBvkR05uPPvss0XqFrNO5ucnSWR2i1lzm+z1wn/N
JmoK2nIhEAeIAmskgDVAFJmJUag4sAasYbS1RliC8UdvaaHwGBa/UPQbkewo
GHuKRONLMCYdD/8v+LcrLsGoOOLPCaRaqaglGIOtkD+gVijsABmVxvwS2A3y
kZsbz+ShoIPdcrpFNtnCDnmz/rHQbpH/U/j6QrtFarvyHVCGOEAUWANrQKGI
JoZ6cWANWMNobo0w25kXrATLkojLc8hMtAQTSsHsU1aCiQrCF1bsjEFhCUZL
+K90cT8tu4TfBeNkn4jII7pQ/omIO3bswImIQA6r5gY7qFroavN1i0Kdef25
JyfwK+gW2WvYqpR1ixJtF8QBosAaWAMKRU5iKBAH1oA1jObWsCkINh3Be5F1
jQ5GoSUYeyVbv7ISTFQQVg2x4ouKJv44F392Iqu8shay41xUagkvuyE8tiW8
ygdfarEjbrnX6CgUXI4DyETOt1oKWmG+CwULn+K7LeFha+GxbyH8mfa5h7n5
b3qy70Qr6xbZlVHRLQL5wBpYAwpF5rda5K8Q1oA1j+bWcD+98saWJ9MRuRec
kV+CCd/OVq6sBJMQ5OkCJRiQCXJjx44dODkEFAQSA9aAQkFiwBpQKCWVGBKC
PF2gBFsbpNPpUCgUkEckElleXi70X5RyblDQpE/oLeXgPNX09/fLtIZemUql
Cl1/KScGrFmrRKNRmdYEg8FkMlno+ks5MWDNWmV8fFymNcTs7Gyh6y+RxFhV
kKeLYpRgNLoPjyZGpxcKH+YDhZDdV65cOZXhiiQXLlyg1zgcjkL/RYkIrgz1
waGieHA8MTyZTKWXNNkksCpUUl29erWhoYGMuHz5soQ19Cy95u7du4X+C1gj
gSbBic8sDowlkouwRj9aWlrOnj1LRlBvIt3d0GuuXbtW6PphjQSaBGc6kQ7F
5+eSafWrAjJ5/Pjx+fPnyQj6LW0NdUnkV6EzfrDmaaQYJdjIVPJXh1w1N0Pz
CxBcV8hut9u96stu375NrUGhK4fgEqgPzkwy9cez/q8v9Q5NFjxpDNRAXV57
e957LPLQa+iVha4c1kigPjiJxXTNrf7fnvB6Bmc02SQgE+pBbt26terL/H4/
9UqFrhzWSKA+OKn08neWkV8edLX6xzXZJCATh8NB9Vc6vcrAOB6PkzWFHgiD
NU8jxSjB7nhGX97r/6LBN50orIrfv3//5cuX1W8AIxgMfv311/Rb9FnqPuhZ
ZWtW894iQbbevXuXtA0EAqu++HGGQv8FBJdAfXAswcn/ONL74RFPIDZX6Hs1
FKekrFleXqbC6syZM3IOCtNrUIJpi/rg9I3M/dfZvjf3uR90FzyYhDWKIWsu
XrwopxOh/gglmLaoD87ozMKupv4Xqj3n2gYLfS8GaYrxer3sINeqr6ThHEqw
EkGrEkx4zuHOq4Hnqzxb6z1jMwv05+Tc4kLKgLNESsruRCJB3WJWCTY6Ojoy
MpL7YpRgmqMsOMJv5B27P/BStefnB1zuyDT9OT2fSiwu6X8qb0lZQ/Hv7Ow8
e/assASbnJyMRERus4gSTHPUB+d71+ibde7X97pvuVZunTmXTM8m0/prU1LW
cJkd19jYKOxEFhcXRT8+SjDNUT9I8w7OvH/I82K1+2jrAP2ZTC1NzaeWlgz4
3khJiUMuNDU1ZXUiPp9vaSl7eIwSrHRgX23jx+3KdiL1ep19kxOzK8e8phOp
9/bb1++x/3yfrX80QfVXZUv4nn88JUNwNsHCrDxx4sTXGXLPdqCX8c/SY375
109gRvN/ij7LDOXXw6+EXyKc6ikrK2MLOzo6uJ/aTU8Jt8FAkslkVgnW3Nz8
ySef8Lc14UEJpjkKgkMdn2NgemhyZZpiIZX+01nfhgrX69W2juDk/EK6/t7g
NVtsVt65+nLEgTWiLCws0DYLSzAqyrZs2UK/s16JEkxzFARnMb3kj84Ghudp
PEmDxn3f92+ocL9cZb/cNZJKLzdaY8cfDI7OLMpZFaxRTCqVam1tFXYi4+Pj
H3zwwc2bN7NeiRJMcxQEJ7203D867+yfTi+tFGJN9tiGcufmCnt1S4gGZm29
EzW3+sNj83JWhUGaYpaXl7u6urI6ERqh1dXVZVVhKMFKCnZ1R4IaVWU7sdE6
sn53V5NjZR7yB8/YW7W29w/YX6+2eKOzjv7pF2u8Hx3xDMv4hkuW3bSE/iR9
cl/G5GKvZMYx5YVvEU6w0BJmK/8sM5QtpDcyQ3lthWvOfZZ/oO1BeTWMjY2x
a3EISzDymuzOrcJQgmmOguA86B5/s8515N4gjSqtoclfHbS/u9f2epXljnes
Lzb3wdGet+oc9v5pOauSIw6sySWdTp85cyb36jSnT5/OrcJQgmmOguB4B2e2
HHH/9WLPTCIdHp3/4xn/a9XWt2otx+8PRscTf7sc2lzpbHHG5awK1iiGXWcj
qxOh+iu3CkMJpjkKgjM0mfzqQs8H37rpwcTc4u7rwRf2dP1in23bd73x6YVD
d6ObarqP3BuQsyoM0hTDviqS1YnQ2Cy3CkMJVrIUtBPZkWvqCr9o8G6uCx57
MJRKL+28FvzoW1d9a+SVSsujnolbrtHX9no2lDvrWwe90Rn+xzM40zuS/Z0X
od3MLPr9dc7RZF5kLqMtuZZ1OJu9nV/IHvBvZ88KJ0n4/yK09UQG/vXCf8dP
zphEbS4zwTKSIZFICJeLVmEowTRHfnBImuWVw15Lu64GNu8N7Gnun02kjt2P
/OqQo+5W+L399ktdIyTOlqM9z9f07GkKWsNTvujsijIkDlkzLNIsyxEH1ogS
j8fJmtzOLrcKQwmmOfKDs5xp4tJL3KlHgxsqXX+8EI5OJG57x7Z869p1re+L
U96K5qC9f/pP5/s21/X997mejr7J3hGyZpb1Nf4hWKMl4+PjZM3U1FTW8twq
DCWY5hRgzfLy0soPd8c79kKV44Njfa6B6e7h2a317r+c795xNfD5KS91LuU3
Bmj8tuVbd6t/PDAyR74wa+ip3HVikKaY6elpsoZ6nKzluVUYSrCSRf5OHJ5K
tgUmuoJTx+8Pbi63bCh37boeCsfnf3nQsf1qn3Ng+qUKa6M1dvB2/6uVXR8c
dr9WbX+t0vJ61Y8/r1R0UTuQtU7FdrOX5bObPSsky27+lfw8DPfEbuHGcDl2
507+GAJ5/SA/9+7d++KLL8hx/gAZSjDNkRmcsZkFS2iKxDnfPvTOXvvGat9X
F3ppfPjfZ/1/POPvCk7++oj70J1Iw6PB9w86f77f8Xq19dUVa7p+tIZUOiRy
4Qhlg8kSt2ZyclLCGuKrr74SVmEowTRHZnBmkmnqUMiaJnv8k6OeTTX+3xz3
tfdOHLjd/+sjrjue0W8aA3+92HvVFvu43vlmre0X+92vCKyhDug/DsAabVhc
XGxvb5ewZvv27cIqDCWY5sgMTmIx7Ruaedgzfsc7/pfzPdTX/MchT7M91uKM
/6zOfrlz+MzjofcPur73jP3prO+liq5fHnK/XGF948kIjax5d68td7UYpCmD
+hEJa44ePUrWUBXGXowSrGSRvxOvdA1TtfWLfbY3a+2fHff+6qD985OeRsvI
82VdN52jE3Op16ps396NfHnK8+lxNw076akLHUMXO4bZz/mOoZuu7NkAfSZY
GOonWNhrzDDH0tzc/AdJqP4iwS9cuMBejxJMc2QGp9U/8dtT/l/sd7xVa/u4
3v3Rt65Pj3vOtUep2qpvHZxKpD474dt5te/rSz1b613fu0dve8epWLvQ/qM4
59ujzQ6Rk6x0mM9nrCVraCQpbc2nn35K1lRVVbHXowTTHJnBcQ/O/Oms/+1a
yzt7bR8edn9c7/r1EeeRe5E/nvH/41Lv2Gyq6kb481P+iubgR986Tz+OPu6Z
OEfKdP6PvuaaLZa7WlijgP7+fmlrvvjiC7KGfrPXowTTHJnBiU4kv2kMvFlj
/Vmd7b0Dzk+PuT887Chv6qtuCW857B4cTzbZ4+/sdRy+O0A2Vd8M2cPTZ9ui
/CDtQsfwFYvItbwwSFNAMpn86quvJKz58ssvyRoap83MrNxcAyVYySJ/Jw5O
JG+5482O2A1HrH80cfB2/+s11s9Pet+ottJT9IL39tn/frH7lUrL9u8CMu+b
qdhu4UJaw9eCU4WzTjPmp2KYoey9+U4zFn2Wfy+32vV8TELuYW6UYJojMzjx
6YVW/ziVUU32WO/ILNVWv9hv/89jnjdrbW2BCXrBn8/5vzjlfbfO/ofTvuh4
YtUVMpQNJjlYk5+hoSEaRlK/OTk5yZagBNMcmcGZmk+RHdftMepu3JGZ256x
X9e7fnnI+f4B55nHQ/SCI3cHPjjkoJHk1iMuh7yvT3KwpgjQUHP79u0kDunD
lqAE0xzZR8GW7P3T1+wjN5yx9sCkNTT1ZYP37b32T+rd2xtXzodp9Y29XtVF
Hc27e223nKMy/zsGaZqT+20RlGAli+Kd2OKMv1zt2Fjh+teVALvl+h/P+Gkk
uaHCdax1UIcSjMu5nA735CI5wZ9ee4e/YA67Tg4tER6qLvRiO6LfRdUfdl8w
2rBoNCpcLvplT5RgmqMsOJ19k+8f8m6q8f/+TPfA2ErBVXUjtGJNuaOsKTQm
78JunIrBJFfa1rD7gtGGZd1NL7f+4lCCFQFlwekdmf2ioXvz3sCWb93W0ErB
dblz+K0a6/rdlj+c6Q7FZV3YjYM1KmDWuN0/+SpBbv3FoQQrAsqCMzqz+E1j
kKx5q9Z+I3MqhTU89Xat7cUK6y8Pu+3h7K/15QODNMV4vV7aqgcPHggXin5b
HyVYyaJ4JzoHZt6odW6s9Fy3xRfTK6N9Gkw+X+HYUOluccRTaQNuOVFSiN4X
jB6LXvIUJZjmKAtOMD738THf5rrAkXuRmcx9zM88Hny1xrmppuf4g8G5BVlX
pAeKEb0v2MjISG79xaEEKwLKghObXvjnlb4X9oX+3dgXn165p8M939i7dc7n
9wa2N/aNz8qduACKEb0vWG79xaEEKwLKgjOTSB+6E9lc1/fpCT+bpugZnt3y
rfv52t5Pj3sjss+4AIoRvS+Y6DWrUYKVLIp34sBY4p299jeqLf6hGVZunX4c
fanG80J5V0ffpBE3/Ss5cu8LdufOnUOHDuXe+A8lmOYoCw4NF397wrNhVzuN
IZkit1zxdw941+22XLWOsKkMUFRy7wtGu5IGk1n1F4cSrAgovg3lnqbgup2d
DY+i7Kq81vDUr4/5N1S49/8Qnl+ANUUn975g5Ms//vGPrPqLQwlWBJQFZyG1
dLZtaP1u685rAdaz0Jjtj+d6N1X7/nrBPzWf0nozQTai9wX729/+lnvnVpRg
JYvinTiXTP/9ct+Oxj6+B/zBM/pq3cqVB4KxOco97bYRiCB6X7B8oATTHGXB
SS9z5c3Br877B55MQnYFJ39Z3/tqteNx74SmGwhEyHdfMFFQgmmOsuAsLS9f
6Bj5/enuruCPZ08FRua+PBfcVOG42JFdAoBiIHpfMFFQgmmOsuDQEOxhz+Rv
T/qbbD9e0Ck+vbDzev/GKm/VjSAGaDogel8wUVCClSxqdmIoPj8ylVx6csTL
Hp6iEuyzE77JOZwZUnTYfcFQghmF4uAMTSSjE0n+gFdgZHbLsd73Drq7xe5k
BDQnHo9fvHgRJZghKA7O2MxCeHQ+8eRM3eHJ5N+u9L9a47rrlXtVAaCG8fHx
27dvowQzBMXBmU2m+mJz0/M/jsem51P77kQ3VrhOPRjUbutAXqanp0kZlGBA
Ag13Ymg08Xq1/V+XemeT+EpL0Umn06FQiLSlnjEgSW9vLzUCbW1thf4LCC6B
VsGJTy98ctT7u5M+dnUOUGz6+/svXLjQ3NwsbQ07jf/q1auFrh/WSKBVcKYT
qW8ag+/td1hDcq8qANQQjUZv3rx58eLFnp4eaWvu3r175syZQtcPayTQKjjJ
1NLJh0OvVFib7SK3bACaMz4+fu/evYaGBr/fL21NZ2cnjeXm5uYKWj+sWQNo
uBPnkunypuBNZ3whhZPziw7ZfUU2165dGxkRueWHNBBcAq2Cs5hePnI3cr59
CCfn60AqlaKqSqY1jY2Nvb29hf4LWCOBVsFJL3FXrbHDdwaGMvdDAcWmpaVF
fnfjcrkKXT+skUCr4CwtLbcHJiuagj3DOONCD9ghMJk8fPiw0PXDmjUAdiLI
B3JDAgQHiILEkADBAaIgMSRAcIAoSIw1AHYiyAdyQwIEB4iCxJAAwQGiIDEk
QHCAKEiMNQB2IsgHckMCBAeIgsSQAMEBoiAxJEBwgChIjDUAdiLIB3JDAgQH
iILEkADBAaIgMSRAcIAoSIw1AHYiyAdyQwIEB4iCxJAAwQGiIDEkQHCAKEiM
NQB2IsgHckMCBAeIgsSQAMEBoiAxJEBwgChIjDUAdiLIB3JDAgQHiILEkADB
AaIgMSRAcIAoSIw1AHYiyAdyQwIEB4iCxJAAwQGiIDEkQHCAKEiMNYAdgPwY
nZ7mxeg9A8yL0blpXozeM8C8GJ2b5sXoPQPMi9G5CdRidAYBU2N0epoXo/cM
MC9G56Z5MXrPAPNidG6aF6P3DDAvRucmAAAAAAAAAAAAAAAAAAAAAABkY7fb
JwAQA4e5JYA4QBRYIwGsAaLAGglgDRAF1qwBYLcQREMIBJcAqSIE0eCBNRIg
T4QgGjywRgLkiRBEgwfWrAGQz0IQDSEQXAKkihBEgwfWSIA8EYJo8MAaCZAn
QhANHlizBkA+C0E0hEBwCZAqQhANHlgjAfJECKLBA2skQJ4IQTR4YM0awDz5
7HQ6Ozs7Y7GYcGEwGHz8+HEoFNJnGwyMxvDwcEdHh9vtHh8fN2obsoDgEphE
nEAg8PDhw8HBQeHCoaEhssbj8ei2GUZFY3R01GazWSyWsbExQzYgF1gjgUms
IV/u3bvX398vXEgNb3t7u55baGA0qKOhJiIejxu1AVnAGglMYg1ly927d6nH
yVrelUG3zTAwGt3d3ffv36fu1agNyALWrAFMYjf1CCdOnNi3bx/1jDSsYgsH
BgYuXbpUXl7e2NgYiUR02AyjokH1V1NTU21t7aFDh2gYYMg25ALBJTCDOMFg
8OzZs3V1dZQ8/NzFyMhIS0tLRUVFQ0NDX1+fPltiSDSooaDmgqw5ePAgjQ1M
MncBayQwgzXU2F65coWsuXDhQjQaZQuphH/w4EFVVdXhw4e9Xq8+W2JUNCwW
C3186m2vXr1qkioM1khgBmuIGzdu7N+/n8Zp1O/wC61Wa20Gm82mz2YYFQ1q
FqijoU967tw5vt0wFlizBjCJ3Y8ePdq9e/eePXsqKytbW1tpCdVc58+f3759
Oy2hwiR37qUYGBIN0vnatWs7duzYtWsX/a6pqTFJFQbBJTCDOD6fj+ygaovc
oRQazUAd5c6dO0ml8vJyl8ulz5boHw0aOt65c4c+Jn1YsobicPPmTTMcC4M1
EpjBmsHBQao+yBrqXM6ePctGU1TCUy5RC7xt27a2tjZ9tsSQaFDnUl1dvSMD
fd7vvvsu68wTQ4A1EpjBmvHx8fr6enLk3//+99GjR1kVRrlEwxXyiDogao31
2RJDouF0Oqn8/Oabb8ga+rxnzpzJOvPEEGDNGsAMdk9kypDr16+zToE6CBpP
UpJTwtOf5Dj1ifyhsaKifzSo0rx06RLzmho3GgCwKuz+/fuGjychuARmEGdk
ZOT27dvULZaVldHvixcv0oBqZwbqE2/duqXbFLfO0aAPTgUXfUyy5p///CeJ
Q9ZQBFpaWgyf1Yc1EpjBGupKOjo6qqqqyBFKm4aGhhs3bpBB2zM0NjYODw/r
syU6R4NG0Q8fPiwvL6ePSR0NG09SEKjdMHxWH9ZIYAZrKHlcLheVIdTqsirs
+++/r6ys/CbD6dOn9TlPacKIQZrNZqNBKX1MZg1rKE6ePBkOh3XekixgzRrA
DHYzBgcH2cEgBl9/UXepT/01obvd/f39VH/RJ6UBAA0JaDjN/qQPzo4G6vbB
RYHgEphEHCpG7t27R/lDOUM9I6u/6PHdu3f1LEb0jMbQ0BCVWvQZafRIv6nR
oD/ZYJKqsOvXrxs7qw9rJDCJNdSudnZ2siqMrKEsYuOrpqYmPb/ooWc0qDW4
f/8+1V/UPvzrX/+ijubBgwfUbrA69Pz588bO6sMaCUxiDVVhbrd737597GAx
c4eKESrhs75WWVR0jkZXVxeNQtl8BVWa7e3t1G6wOvTYsWPCczL1B9asAUxi
NyMajdJoitSmnoJ+19XVUUep58EgnaPx6NEjGjRWVFRQwUWP6ZNGIpHvvvuO
ZCfN6+vre3p69NyeLCC4BOYRhyoOGk1RCjFr6LfwC5X6oGc0PB4Pf/olO9I3
PDz8ww8/0J+0UM9vJYgCayQwjzUkiNVq3bt3L/nCzgC/cePGyMiIntugZzSo
Z9m/fz99WBpMXrlyhbpaEqetrY1UYofRHz9+rNvG5AJrJDCPNROZ5vfw4cNs
0o9y6fLlyzoX73pGg4ZkR48epQ9Ln7ShoYEqTapDaQNoaEofnwox6nd025hc
YM0awFR2T2S+K33nzp19+/ZR5tO26fwVe52j0d3dfeLEiQMHDgjPtKS+8tq1
a9XV1TQkMPbaOxBcAlOJQ6Opjo6OQ4cOUefIanmdN0DPaFA/SP0+dYLff/89
f8CL2o27d+/W1NRcuHBhYGBAt43JBdZIYCprSBOXy1VfX0+F2O3bt/U/eKpn
NKi6pA6FCq7r16/zpx1Su9He3k4qHT9+XLdL94gCayQwlTVET0/PqVOnamtr
KZf0P3iqZzRo/Hnv3r2qqirqVvjTDmmh0+k8lEG3S/eIAmvWAGazeyLTWZDj
wWBQ/9PwdI4GjQHoY9KHzTpnjJo1v99v+Pc9IbgEZhOHZKFBVCAQMOTLUDp3
i5FIpLu7O+uYBQ2haSHOzzczZrOGcomsyc0lfdDZmqGhIRoxZn3ti9oN6oD0
udqVBLBGArNZQ4RCIZ/PZ8gUsf7fOyZrsqb1yKbeDMZehhfWrAFMaLeBIBo8
VB5CcAmQKkIQDQaskQZ5IgTRYMAaaZAnQhANBqxZGwQCAT2/SgmeFsLhMASX
AOKAXGCNNLAG5AJrpIE1IBdYszaYmppyOBwQHAgZGxujrIDgEkAckAWsWRVY
A7KANasCa0AWsGYtQYIHAgE7AE9wOp2UFUYnptmBOEAIrJEDrAFCYI0cYA0Q
AmsAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAADIYmpqKhAI2AF4gtPppKwwOjHNAgQB
WUAQIRAEZAFBsqBoGL1PgImAIIBBaeBwOOLxuNEbAkxEOp2mrKCGwugNMR4I
AnKBIDwQBOQCQYQwR4zeCmAiIAhgBAIB9J4gl1gshvaBgyAgDxCEAUGAKBCE
B46AXCAIIJADIB/IDQ5BAPlBbnAIAsgPcoOBOABRkBgAOQDygdzgEASQH+QG
hyCA/CA3GIgDEAWJAdTnQHx6Ib20rMnGAFOB9oHTSJBUGoKsQSAIp5EgixBk
LQJBGCrjMDq9sJBa0mpjgHmAIEB9Dhy/H7nfPY4ibO2B9oHTIggnHgy2+sdT
MGTNAUE4LYJw+tHQbc/oIgaZaw4IwlAZhzOPh753j6IKW3tAEKA+B7Zd6f3g
W19H3xSGmHqyvLzs9/tHR0dFn00mk/mekg/aB06LIGxvDPzqsK8tMAlB9IQE
6e7ujsfj9CD32YWFBRJE9Cn5QBBOiyCUNYV+edj7qGdC5e4AhUKCxGIx0bAv
Li5CEK1QGYeKG+H3D3nu+8fhh85ICEI9yNjYGAQBKlGfA3uagptquj+q97gi
M5psEpADue9wOIaGhnIbAeo9e3t7g8Eg2gf1qA9CZXNoU7X/w289jgEIoh9M
kMHBwdynmCChUGhpSdXEMgThtAhCTUtoU5X3V4dd9vC0JpsEZOJ0OqPRaK4F
TJC+vj4Iogkq41B3K7yxyvv+IZc1hDtJ6YrL5aIeJNeCVCoVCARIkHQ6rWb9
EARoUoJtrnRuqvL99oTPH53TZKvAqtAIk/Zdbgm2sLBAvafFYqH2ASWYejQo
wW6EXqhybqr2fXrC5x2c1WSrwKqwEoxGmFnL2fCSBMEchSZoUILdDJMgG6t9
vznuxTyenoiWYCQIDS9ZD4ISTBNUxmHvrfCLGUE+OeZ19GOaQj9IkNwSjAQh
NUgQ0gSCAJVoUoI9X+l8bmfnxkrPlw3+YHxe/nuf+W9/1o/KjSkdRI+CJRKJ
np4eq9WKEaZWaFKCbX4iyOenfIGRAqYpIIhiREswEoTqLxKkq6sLgmiCJiXY
i9Wu53Z2kCCfHff0DEMQncgtwRYWFmhgyXoQlGBaoUEJtiLISg/y6TGPf6iA
eTwIoobcEowXhHoQlGBAPdqVYB3rdlAf6v7L+e7+UblVGNoHxeSWYDS89Pl8
1DiEw2F6gKNgmqBdCdbx3Iognq/Od4dkT1NAEMXklmBMEBpbkiAejwcjTE3Q
qgRbt7PzuR3t1IP8+Vx3X0xuFQZB1JBVgpEgfr+fCeL1ejHC1ApNSrAngnj+
eNYvfx4PgqghqwRLJpPd3d00xAqFQtSVQBCgHg1LMGofqJXYWOH6+lLv8OSC
nPeifVBMVgk2OztLo0rqPanFWFxc7OnpQQmmCZqWYEwQ998v9kQnknLeC0EU
w5dgzIK5uTk2QRGJREgQ6kl7e3vRgapH2xJs3cqxMNffzncPjCXkvBeCqEFY
gs3PzzNBBgYG2Mm6EEQrNCzBmCCZiW4IUnSEJRgThIZYTBCqvyAIUI+2JRgb
ZG4od5Y3B2NTq1dhaB8Uw5dgXKb+crvdNpuN/lzK4Pf7UYJpgrYlGC8IWTMM
QYqJUJDp6WkmCPWn6XSaXSwRHagmaFuC/TjIrHDtutY3NLn6NAUEUQMrwbjM
BAWbwaM/mSA9PT0QRCs0LMF4QbZfDciZx4MgamAlGPdEEKvVSoKkUikIArRC
8xJspYnY1bW+zFbVEqIqTLoIQPugGH6EOTU1RcNLdmkO1iBQH4oSTCs0L8F+
FGSPraI5NDyVlN5DEEQxlPzUgTJBvF4v1V/Dw8NMEHZDB3SgmqB5CUY/63d1
bdhjL28OUhUGQYqHy+WiISUJQsNL2o+s/uIygmCEqSHalmCsByFBaOg1OJGA
IMWDCTI9Pc16EF4Q8gKHiYEmFKMEe2572/o99vVl1tvesbTkHWnRPiiGjTCp
zqJWwmq18sNLLtM+oATTimKUYCuClNmpCrvlHpW+ZTMEUQwlP6lBFrjdbovF
wk9QcE8EQQeqCcUowTKC2DbscTQ7Yqk0BCkWTBD6zR//YsvJC5RgGqJ5Cfaj
IOWO6/bYIgQpGtR3BAIB1oOwMyjYcpRgQCuKcxTMsn635b9Oed2RmaUCR5ge
IEAidOwoWCQSYRcQptYgmfzxtASUYBpSnKNgJIj185Me58C0pB8QZBUkQsdK
sIGBgVAoZLVacwVBB6oJxSjB1u220M8Xp3z28FShk3hGp6S5kI680+kkQdgV
tqnmSiR+/HoRSjBtKcJRMBLE+rtTPisEUYd05EmQ/v5+UUFQggFN0P67YLst
G8ts/7jcG5bxddHc9mEoFsMP+5FuH/gTEVOpVDgcpkEmNRFskIkSTEO0/y5Y
RpC/X+oNQRBdBFlcXKRulATp7u4WCoIOVBO0/y7YLsuGPbavzvkDsdUvHApB
FAvCZUaYrAfhBWGDTJRg2qJpCdbGBPnzWX/P8OpXp4cgKgVhX/4aGBggQajX
mJ9faZRQggGt0LYEW7/b+ny57ZvvArFphRd8M3ZKxGxIhE54tYF0Ok1VmMVi
oSaC9aHUmaIE0wRtSzASZNMe27bvAiNTEEQDJEInvCIiCcIGmSTI3Nwcvuqi
IZqWYG3rVgSx/uu7gJxrcXAQZDWko8euNsAEoUEm9SA+n48EoacgiIZoV4Kt
CLKxzPr1lcDghMIrIhqdkuZCOnr8JUOJSCRCPQgEAdqiWQm2o2P9bsuLlfaK
5tDE7KLM9+JEZcUISzAuU4WxJsLr9U5PT1MJhjvPaoKGJRgJ8kLFyneoR2dk
3bKBgyAqyLovGAlCo01eEHSgWqHhrZlJkM0Vtt3X++LTEEQPhBelJ0HoMRNk
amqK7MBtj7RCqxKMBHm+3LbrWp+cy00zIIgahBelp98kiM1mgyBAQ7QqwdaX
2V+ustXdCs0l0/Lfi/ZBMbm3ZuabCI/Hw67UgRJMPZqUYC9UudbvcbxUZau9
FZ6BILqQe2tmXhC3280EQQeqHi1KsBCNMNfvsb9YaatuCU3PQxCdyLo1MylD
HQrtUCYIRphaoUkJtmGP48UKW9WN0ORcSv57IYgasm7NTAwPD9PeZEMsEoS/
QIcyIAhQnwPlTcENFa7XapxHWyOJxcISEu2DYnJLMLZwZGSEBpldXV2hUAgl
mHo0KMGagxszgnx7d2AeguhFbgnGZaqwWCxG+9RisWCOQhM0KcE2VbheqXYc
vjNQ0AweB0HUkVWCcRlreEGCwSBKME1QXYKFNlW6Xq52Hrw9MJOAIPqRW4IR
8XicltMQC5N4QD3qc2Dn1cDb+zynHw1JX/xQFLQPihEtwbjMIJOqMKvVihMR
NUF9EHZfC7xV5z71cChdeGsNQRQjWoKx5dSHkiDoQDVBg0m85uDb+z3HH0Sk
rz8vCgRRQ24JxiBBbDYbjoJphco4VN4IkSBHWyOLqYJ3BwRRg8vlyi3BWA9C
glAPgqNgQCXqc6C+NXKxYyilYHyJ9kEF1Cywe7Xn1lm0ZHR0tL+/HyWYetQH
gbrO8+1RBb0nB0FUQMlPgrCrDeQ+FYvFIIgmqA/C8fuRc+3RBQiiL5T8NIyM
RCISPQhKME1QGYeTDwfPtUWTixBEV8gC2nEkSK4F9NTY2BgEAepRnwMyL10F
tIU1AolEQnQYmU6nk8kkRpjq0UCQCQhiAJT84+Pj7OpVuVDXyd8mTDEQhNMi
CMOTSVXtFFAE34OIPgtBNERlHIYnE4WfYQQ0gHqQ+fl50XEUEwRDLKAS5MDT
y3KG4q0fucEhCE8zEEQHEISnFwiiD4jDUwoEAcXGDDngdDqbMvT09PALb9++
zRZq9ZZio3iT6NlIJFLQW/TBDLlhOGYIAgSBIKbFDEEoWUGy3kK/m36KUBz9
MUNumAHD4wBBIAgwJ4bnACnA9JmcnKQH9Jsed2XgMgY9fPhQ/VtM+CkYWe2A
sZ8iC8NzwwwYHgQIAkHMjOFBKFlBRN/CA0HMg7FxgCAQBJgWw3OAl4ggI8gL
TjDvzbvDrgJa0FtM/ilY+8CmZfgRprGfIgvDc8MMGB4ECAJBzIzhQShZQUTf
wjCDHZwJcsMkGBsHCMJBEGBWDM8BoRpMmSw7cg8WK3hLsVG8Sexloi0bjpKb
AcODAEEgiJkxPAglK0juW/insv40CsNzwyQYGwcIwkEQYFYMz4GSbR8YGGGa
HMODAEEgiJkxPAglK4jECNMMM/ycCXLDJKAEUw8EAWsSw3OgZNsHBkaYJsfw
IEAQCGJmDA9CyQqSb4TZ09Nj+JdcGIbnhklACaYeCALWJIbngFANmWcdK3iL
CT8FQzjClPkW3TA8N8yA4UGAIBDEzBgehJIVRPQtbLnway8GYnhumISn4rtg
Kt/ytHwKDoIAM2F4DpTs5XoYWSNMYz9FFobnhhkwPAgQBIKYGcODULKC5Lvg
2+3bt409OsxjeG6YBFwR0TyfgoMgwEyYIQfk3O5BeKEbmW/RGQWfgssZYea+
xUDMkBuGY4YgQBAIYlrMEISSFUT0LfofociHGXLDDBgeBwgCQYA5QQ6AfCA3
OAQB5Ae5wSEIID/IDQbiAERBYgDkAMgHcoNDEEB+kBscggDyg9xgIA5AFCQG
QA6AfCA3OAQB5Ae5wSEIID/IDQbiAERBYgDkAMgHcoNDEEB+kBscggDyg9xg
IA5AFCQGQA6AfCA3OAQB5Ae5wSEIID/IDQbiAERBYgDkAMgHcoNDEEB+kBsc
ggDyg9xgIA5AFCQGQA6AfCA3OAQB5Ae5wSEIID/IDQbiAERBYgDkAMgHcoND
EEB+kBscggDyg9xgIA5AFCQGQA6AfCA3OAQB5Ae5wSEIID/IDQbiAERBYgDk
AMgHcoNDEEB+kBscggDyg9xgIA5AFCQGkJ8DdrCG0DY31jDyg2D0LgVaom1u
rGHkB8HoXQq0RNvcWNvIDxdYM2iYGGANgxwA+VCZG88888zWrVsbGhroQSAQ
0GqrVFLoVkEQkA8IwkEQkJ+nWpAvv/xy27ZtmmwVHAGiQBCAxgHkQ2VuPPvs
szt27MgysbGxccsT6LEWm6nBVkkAQUA+IAgHQUB+NBdEaAdRU1Oj0ZaKkG+E
WaggHBwBeYAgAI0DyIcm7UNrayuZyJYcP35cOLCk9qGnp0ftVqreKmkgCMgH
BOEgCMiP5oKwEaY+UxPSI0z5gnBwBOQBggA0DiAfq+ZGQ0NDQSvMNy3DRp6M
Bw8e0BIaebKWhBynByQ7LdyWgf3JHtAb2XL+7XybQK8RrlbxUBaCgHxAEA6C
gPxoLojoCJOMYF5QSgszPPeAMrOGT3tmDYO8y1KMScTWqUYQDo6APEAQgMYB
5EM6N9gsx7p162Sujbc7azlrB5i/zH3+xST4gwzC0Sa/HmoTsiZh+FdymfaB
tRXs9YqPyEMQkA8IwkEQkB9tBeEkR5iU6pTJ7AW8FGysyBvEUp0ZJFwVG15m
jSG1EoSDIyAPEASgcQD5kJMbzz77rMwmQjjCFM6cCKfo+YX8CFO4BjbJz54i
8fkRJmtMePh/wb8dI0xQDCAIB0FAfrQVhMv5qgvLZJbeWQksnLRn8GNF4bvY
CFM0/7UShIMjIA8QBKBxAPnIzY1n8iDzcLnQUzafz0aYwuPdDNEjAqIjTOEM
DGs0lI0wqaETPXUZgoB8QBDRIADA0FwQiUn+rIVshJn19qKOMPMJwsERkAcI
AtA4gHysmhtbt24tyClmPTv2zY8wsy5BwCh0hMleydavbISZr6GDICAfEISD
ICA/mgsif4TJXpklSL4RJjvQzLzj0UoQDo6APEAQgMYB5EPOicqFrlN4BYAt
T84uFh4TZxP+8keYwrezlSsbYbJrqGKECeQDQTgIAvKjuSDyR5hcjkpc/hEm
99NL1vBfltREEA6OgDxAEIDGAeSjpHJjx44dOM8KFERJ5QYEAYVSUrmRTxCu
xOIA5FNSiSEhSClTUjkACqJEciMQCLBD5KLPlkgQgAJKJDcgCFBGieSGtCBc
ycQBFEqJJMaqgpQyJZIDa49EIuFyuRzy6OnpSafThf4L5AaHIDy1LCwsQBAd
QBCeUkgQt9sNQXQAcXgagSBABzTJgdTSsiU01T86v7ysfmVAFrFYrLGx8dSp
Uw0NDVckuXjxIr2MGpNC/wXaB06jIKSXl60kSHx+CYboxeTkZEGCKNjREITT
SpClZVt4Khyfpwfq1wbkQIJcvXpVjiCXL1+GIGpQH4eMINOhGATRDwgCdECT
HBgYT7xT56xpCS2kltSvDciHxA+FQqu+rKWl5fHjx4WuHO0Dp1EQBicSP9/v
qrwRSixCEF2RI8jy8vK1a9cgiDK0EuS9A67y5uBcsuCZZKAGmbNz9+7dgyCK
UR+Hocnk+4fcu6/3zUAQfSFB/H7/qi+DIEAZmuTAVevICzX+35/xzS8U1j7s
37//8uXL6jeAEQwGv/76a/ot+uytW7foWWVrVvPeIjE+Ps6maEZGRlZ9MW0/
2gdlaBKEJnvshRrff532FdqBQhDFTE9PQxAd0CQILc7Yi7W+z0/5puYXC3oj
BFEMCXLt2jUSJBAIrPrixxkK/RcQhKE+Drdc8Zf3+n970jsxC0F0AoIAHVCc
A8Izqv52sXtjpfeTo+6JucWlpeXoeCJpxOGwkmof2HfBskaY/RlyX4wRpmJU
CPI/DPn6Us/GSs/H9e6x2UVaTIIYcjispARh3wXLFYRd5j0LCKIYTXqQf10h
QdwfHXGPzayMMKMTyfnFpWXdz9otNUHcbnfWCDOfIBhhqkFZHITp/01j76ZK
z5Yj7thUkryITiTmFtL6n9UOQSAI0BZlOUAjyRvO0dFMd0ltwps1lo17bO/t
t0cnk/HpxX9e6bvlHpVz0jKbomFenzhx4usMJGPuy/hn6TG//OsnsDaB/1P0
WeY4vx5+JfwS4WRRWVkZW9jR0cH9tH2gp4TbYCBzc3NZI8zm5uZPPvkkt4nA
CFMxyoIwPrvY4orHplcEiU8n39lr3bjH/ot99oHxRHx6Ydt3QXp2Mb16FQZB
1JBIJHIF2bJlS2dnZ9YrIYhilPYgCzfs8eGJ5MrjmcWf77OvL7P9bJ89PJYY
JUEag02O2GIaPUhxYYIIR5h37twRFQQjTDUoiMNKD+KID00ssMf/sd+xvsz6
bp29Lz4/PrPwzdXgNXscghQbCAKKjbIcaHg0uKHCedMZ5zJnIb5S2bX1iOuN
GmvvyHxXcHJTlfeDw66hyeSq68lqH2gJ/UkC5r6M6cleyZxljYbwLcIpGlrC
fOefZY6zhfRG5jgvvnDNuc/yD7Q9rK+GaDR6KoNwhLm0tFRXV5dbhWGEqRhl
QTjbFt1Q4Wh2rAhy3TbyWtWKIK9XW/xDs9bQ1OZq7y8POiPjiVXXA0EUMzU1
1dDQICpIbh8KQRSjLAjn2qLr99iv2mL0mDR5u9b+0bfO16osnuisLTz9Yq33
/UPugTEIUkTGxsZYD5J1ntXp06dzBcEIUw0K4nCxY4gE+c6yIkiLM/7O3hVB
Xq+yOAdmHP3TL+/1vXfQFR6dX3U9EEQxEAToQEE5kF5aXlpaHp1Z/PUR1+a6
vhMPoqn08t8u9tCfpx9FXyzv7OibpIrspRr3hnJnzc3QHe/YPd/YXe+PP22B
iawVCtsH5ib9/jrneDTfFHAZ8cnWrAPi7O38QvaAfzt7VjjNwv8Xoe8nMvCv
F/47fnrHJI0DYzZD1qVQRaswjDAVU6ggy8srs/of17te2Bc8dj+6mFr6+8Xu
Xx9xNjwcJEHaApNN9tirtZ4NFa7qm+Hbnp8K0gtBtERCkKw+FIIoplBBuMxh
r/887t68L3ikNbqQWvrXld6t9e6GR4MvV1jud4/fcI6+WuveWOGqvBG+6xu7
5x9ndtxBD6I1TJBUKpW1PHeQiRGmGuTHgQkyPpv67ISHBDl8b0WQbxoDW4+4
Tz0cfLXSSjrcdI6+RoJUuituhO+tCDImEGQya4UQRA0QBBQb+TkQGJlrcsSb
bLGqG6ENu7vW77Htvh7si82/XWurbAn5ojObyrquW2M1N4Nv7bVTA/JWre2d
vfRjXfmptb5Va/30ePaVlxS3D+xl+doH9qyQrPaBfyU/k8M9aR+EG8PltA+5
00eGEAgEJC6ReunSpU8y8LM3GGEqpiBBmh2j122x6pbQxt2d68tsO6+tCPJu
nb28eUWQF/ZYrlpitTdDb++1kws/ClIrEOQYBNEGOYJQH+p0OtnrIYhi5Aeh
LzZ33TZywxGvaQk/v8dCgmxv7Osdnn1vv6OsKegdnH6pwnrFEqu7FX69uut3
J33v1jnfrrXygrxZbfn0uCdrnRBEGbSR0tfZ/uKLL0gQfudihKkGmXEIjs5f
t68IUnuz/4Vyy/o99m9IkJG59w84dl3r8w7OvFJpvdQ1sv+H/jdrLL894fvZ
vp8KUmP5DQTRCJmCWCwW9noIApQhPwe+s4z853HflsPO9w44/nK++5Oj7t+e
8JzvGFq3q/Nhz8Tk/OKL5ZZv70ZoGPn5SY9/aPaOd+ymM94i+Hlk0CQ/Q/0U
DXuNGWZprl+//gdJtm7d+sEHH9y5c4e9HiNMxcgPwlVrbEWQbzOCnPN/Uu/6
7LjnQsfQht1drd0T04nUK5W2Q3cGfnvc87uTHs/gzF1ftiDkUdY6IYgyZApC
L2OvhyCKkR+E6/b41iOuDw473jvg/Ov5nq1HnJ8ed19oH95U1nXXtyLIa1W2
Q3cjvz3hJkHckZm73nEIUiRu3rwpLcgnn3wiFAQjTDXIjEOzI/5x/Y+C/OV8
z8f1zt8cc59vH9pcZvnePTaTSL1ZYz9we4DGV58ddzv7p+/5xm+6BIK44g+6
x7PWCUGUAUGAPsjPgeHJJNVQ5Dj1gyNTyQO3w69VW39z3PNunX18buWyAz+r
s/3lQvcLe7rKm4IybyCouH0QLqQ1fC042TjrRGV+Moc5zt6b70Rl0Wf593Kr
XRHIJHR2dm7ZsuX06dP8EowwFSM/CCTF48CKIPQzMrVw+E7/69XW/zzmeWev
LT6z8q3qX+yz/eV894t7LGXX+uRci4ODIMUBgmhIYYL0Ttz3jzFB6lsj1IN8
XO9+d699eGpFkPcP2L8653+xvGvn1T6Zt5iEIMWgp6eHRphCQTDCVIPMOMSm
F6gHud+9IkhsauFoa+T1GtvWevc7tbZo5sI1Hx5y/vmc/6Xyru3fBWTeAAiC
FAMIArRCcQ7ccMRfqHRurHTtaQqy7vLLBu/bex0bK1xn24Z0GGFyORfk4Z5c
Zif406v38JfcYVfaoSXCg92FXq5H9Nus+sPuC3blypV4PC5cnju85DDCVIHi
INx0xl+qIkHcu68H2T0a/njG9/ZeOy05/XhIhxEmV9qCsPuCQZBiozgI37tH
X6lxbqzyUsHFxpN/Put/q9a2odJ98kE0Ke+uDRBEMey2RyRI1n1McoeXHEaY
6lAWh9ue0VdrnJuqfNsbA7OZG0r+9Xw3E+RYa0TmbU0giGIgCNABxTlgD0+9
XOVYX26/4/3x+vMVzcGNe+zr99jv+cZkHgUDihG9L5jT6cwdXnIYYapAcRCc
A9Ov1Tg3lDu/d8dTGR2qbgQ3ltvXlzvu+MZSEKTIiN4XDIJojuIguCLTb9Q6
NlQ4W5zxVOby2jUtoecrVpbcco2mZFxwG6hB9LZHosNLDiNMdSiLg2dw9u06
18YKd5M9xua0626FN68I4rrhiC8acevVkgKCAB1QnAMDY4lXKrveqbVGxhLL
md7y1MPBF6o9L1d0uQZmltF/Fp/c+4I9ePDgwoULua/ECFMxioMwOJF8vdry
Vo21f/RHQVauGlrtfrGiyx6eWkIJVnxy7wsGQTRHcRCiE8mf1TnerrX1xeaY
IOfahl6q8bxYYbEEp+CHDuTe9iifIBhhqkFZHIYmkr/Y53izxtozPMtuU36h
feiVWs/m8q7OPgiiBxAEFBvFOZBYXPrn5Z6678P8dOUtV/ylvd2/OuSMjq9+
RzCgEtH7guUDI0zFqBHkX1d69t4KJ59MV/7gHn2lrvv9g66IjBseAZWI3hcs
HxBEMYqDkFxc2t0Urr0Z5k+puuMZe21fz3sHnP2jEKTo5LvtkSgYYapBWRxI
kLLmcHVLaC7549e+Wr1jr+/v+cV+ZzA2p+kGAhEgCNABNTkwNJGcmEvxkzGW
4OSL1d4vTvn4FgMUldnZWWofhoaGVn0lRpiKUROE4cmF8dnFpSeHhG3hyZdr
vb876ZtOQBA9gCA6oCYI0YkECcKfMuEYmH51r++z497J+ewb8YBiwATBCLPY
KI4DDbHGZhZ4QVwD06/V+X5zzEvWaLZxID8QBBQbDXMgFJ9/pdK663qfzG9S
AzXw3wVraWlxSGKz2c6fP591M3c5oH3gNA1CeHT+tSrbjmt98xCk+PDfBVtV
ENrFJEhbW1uh/wKCcJoGYWAs8UaN/ZsrvbOYxCs+/FddmpubVxXkwoULEEQx
WsUhMp58q9a+7XLvTAJzFEUHggAd0DAHqN88fGegrXcC1+LQgVgs1tjYKH33
QB4ahY6PZ98xZFXQPnCaBmEuI8ijnnEIogOTk5MFCZJ14UQ5QBBO0yAkFpeO
3B142D2Oa3HoAAnCLhkqBxqFQhDFaBWH+YX00XuR+/5xmRfUBWqAIEAHkAMg
H8gNDkEA+UFucAgCyA9yg4E4AFGQGAA5APKB3OAQBJAf5AaHIID8IDcYiAMQ
BYkBkAMgH8gNDkEA+UFucAgCyA9yg4E4AFGQGAA5APKB3OAQBJAf5AaHIID8
IDcYiAMQBYkBkAMgH8gNDkEA+UFucAgCyA9yg4E4AFGQGAA5APKB3OAQBJAf
5AaHIID8IDcYiAMQBYkBkAMgH8gNDkEA+UFucAgCyA9yg4E4AFGQGAA5APKB
3OAQBJAf5AaHIID8IDcYiAMQBYkB7ADkx+j0NB6j9wAwNUanp/EYvQeAqTE6
PU2B0TsBmBejcxMYjNEJCEyN0elpPEbvAWBqjE5P4zF6DwBTY3R6mgKjdwIw
L0bnJgAAAAAAAAAAAAAAAAAAAAAAaIzdbp8AQAwcJecgCMgPBOEgCMgPBGHA
ESAKBAFoHIQgGkLQPnAQ5KcgGkIgCAdBfgqiIQSCMJAVQhANHggCoIMQREMI
2gcOgvwUREMIBOEgyE9BNIRAEAayQgiiwQNBAHQQgmgIQfvAQZCfgmgIgSAc
BPkpiIYQCMJAVghBNHggCDCPDjabraurKxaLCRcGAoFHjx6Fw2F9tsHAaESj
0ba2No/HMz4+btQ2ZIH2gTOTILQlnZ2dWYIEg0EShH7rtg36/KNcSJCOjg4S
xKgNyAWCcGYSxOFwUIaMjIwIF5Iajx8/DoVC+myDsYK0t7e7XC70IGbDJI5Q
blCGZAlCapAgfX19um2GUdEYGhqij+90OiEIMA8maRyo+Dp48GBVVdWdO3fi
8ThbSM3CyZMnv/nmm0uXLkUiER02w6ho0Kc7f/787t27a2traURtyDbkgvaB
M40gVqv10KFDJMgPP/wwOjrKFpIgp06dIkEuXrw4MDCgw2YYFY3BwUFqBMrK
yurq6mjAYMg25AJBONMIYrPZDh8+XFlZefPmTb4Hofrr9OnT//73v6l17e/v
12EzjBWE9SCtra0mGWRCEIYZHKHSgwSpqKhoaWnhBaH668yZMyQI/V7bE93R
aPTKlSskSE1NDQQB5sEMjQNBUuzOQKMsGmROZHrPEydOUONQXl5+9OhRfeb5
DYkGNX3nzp2jgfT2DDSKoCrMDE0E2gfONII8ePCA1GCO3Lp1ayIjCKu/SJD6
+np9pjENiQZVlxcuXGB27NixgwSh5mJsbEz/LckCgnCmEaStrW3Pnj1lGagK
m8gML0kQ1oPQ4DMQCOiwGUYJcvHixe1PoGG2SQaZEIRhBkfa29tJBNaJUBVG
6UEDj9OnT7Me5NChQ729vfpsif7RiEQiQkHo8969exeCADNghsZhInOMuKmp
aVcGEoRGXEeOHNm2bRv9uW/fPt02Uv9o0MCAjRMIagzpI9MgkzUR/MEOo0D7
wJlJkBs3bjBBaKh5/vz5o0eP8oJYrVZ9NkP/aFCl2dDQwAShz0u/2SCTBOHn
co0CgnCmEWRkZOTWrVs0vBQKQtmyc+fOuro6m82mz2boHw2qNNmRPtaDENSD
UAS+//57CGISzOAICUIpwQty7ty548ePM0H27t1rsVh02xKdo0GV5tmzZ7ME
oSEWNRcQBBiOGRoHxvDwMBtk0hCLyUKPDxw44HQ6ddsGnaPB11/UMNI4ob29
vbGxkT44tYrUSBo+yET7wJlJEOpDb968SVJQD8ILsn//fofDoduEnv6CsOFl
WVkZjRMePXp07do1ah+YILdv34YghmM2QagtJUHYWIvyhM3grVVB+vr62Ilk
7AwrEuT69eskCLUMpAwNubO+OqozEIRhEkcoGVgVxgTh6y+bzabnISE9oxEM
Bln9xQvS3NzMC0LNBQQBxmKSxoHBmojy8nIaX5Ey9fX1On/7XudoUJFF7QB9
WP5I39DQEA0yqWGsqqo6duyYPifP5APtA2c+Qaju2JOBBPn222/XtiD37t2j
j0kNAo0T2JE+dricCULtQ3d3t57bkwUE4UwmCJXk1KhWVFQwQQ4dOuRyufTc
AJ2j8fDhQ/qkJEhtbS07kMFmMumzkyBHjhyBIGbAPI6QIK2trSQI5QwTxOFw
6LwNekbj8ePH5Rmo/urs7JzICMImakgQ6kC9Xq9uG5MLBAHmaRwYo6Oj9+/f
p5bh7Nmzfr9f5/+u/yR/Q0MDjSSFBzJokNnc3ExFGY0/MclvOGYThFKCF0T/
7kN/QehjHj16VDhPywaZdXV1wkv3GAIE4UwpyKNHj0iQ06dPr3lBgsHgmTNn
qNTKEoQGmdSD/PDDDxDEDJjKERpitbW1kSCnTp0y5AKzekYjFAqdP3/+8OHD
FotFKMitW7dIEBwmBoZjqsaBQb3GwMBANBrV//uSOkdjbGxscHAwEolkfe2L
moj+/v6si8fqD9oHzpSCULaQIJQ5+l+SwihBsj4pqUERgCBmwISCsB6kFASh
LjJfDxIOhyGISTCbIyQIDTAobQy5JIWe0WCCUGuQNRdBapAgpIluWyIKBAFm
axyMBdHgodEL2gcOgvwURIMHgjCQEkIQDR4IwoOsEIJoMCAIIAKBgD43TAFP
F+FwGO0DB0FAHiAIA4IAUSAIDxwBuUAQQExNTTkcDrQPQMjY2BhlBdoHDoIA
MSAIDwQBuUAQIXAEZAFBAA+1D4FAwA7AE5xOJ2WF0YlpFiAIyAKCCIEgIAsI
kgUcAUIgCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGuMqampQCBgB+AJTqeTssLo
xDQLEARkUbKCwAWQBVwAgFGyLgDFUMI4HI54PG70hgATkU6nKSuoSTF6Q4wH
goBcSlMQuABygQsAMErTBaCGQCCAZgTkEovF0JJwEATkoQQFgQtAFLgAAKME
XQBqQLaAfCA3OAQB5KfUcqPUPi+QT6nlRql9XiAf5AaQD7IF5AO5wSEIID+l
lhul9nmBfEotN0rt8wL5IDeAfNRnS/9oYiG1rMnGAFOBloTTRpD5ZGpJk40B
pqLUBFH/ecPx+dQSOos1CFwoCJIgPDoPFdYkpeYCUIP6bDnSOnjNGkul0Zro
zfJycWOOloTTIghHW6ONlhEIoj8QRFvUf979tyM3HPgGjQEsZyje+uFCQSQW
l/Z+P3DXM6bV9gCZLD+heP+i1FwAalCfLduv9v38oPc2GhN9oTbE6/XGYjHR
ZxOJRL6n5IOWhNMiCLuuB392wHPLNVrkggBkwwQR7W2TySQEKRT1n/dvFwP/
cdj3uGdCk+0BMkmn0263e2xMvI+en59Xf2UJuFAQ8wtLvz/T89FRvz2Ma5jr
CrX8Ho9nYkKkCaKeYnZ2Np8m8ik1F4Aa1GfLnqa+TVW+9w662gKTmmwSkAM1
Fw6HY2hoKHeESY1Md3d3X1+fyqketCScFkGobA5urPL+/IDzUS8E0Q8mSDQa
zX1qYWGhp6eHBFlaUnWCaKkJov7z/uty7/O1PR9+63YOzGiySUAOqVSK9t3I
yEjuU1R/+Xy+UCik8l/AhYKYX1z64xn/87W9n53w9gzPabVVYFUSiQT1C6J1
1vT0tNfrjUQiKv9FqbkA1KBFCRZ8vtK5odK95Yi7sw+DTJ3IV4JRC+P3+7u6
uoLBIEow9WhQgt0IvVBFgnho5NkWwPy/TuQrwUiQ7u5uEgRzFIWiSQm2odyx
vsL56XGfKzKtyVaBVclXgs3NzdGYk1zo7+9X+S/gQkHMLaT/dLZ7Y6VnXZnt
j2e7+2LzWm0YkEa0BKOOgOovt9tttVoHBwdV/otScwGoQasS7LmdHRsrXL8+
4nJHCpjefOa//Vk/KjemdBAtwahL9fl81gwowTRBkxJs8xNBPvrW5RwoYOQJ
QRQjWoLNz8/7/X6yw2KxoAQrFK1KsOd2tG8od3523NMXK2D+Hy4oRrQEm5mZ
ofqLdRYowQpFoxLMTf3C+jLrn8/5oxMJ+W+HC4rJLcGoF5icnKT6izoF2q0o
wYCeaFiCUcdKg8wvTvn80VmZ70VLopjcEmx2dpZN40QiESrEUIJpgoYlGBPk
dyd9PghSfHJLsLm5OaEggUAAJyIWhIYl2LqVKszx53Pd4bjc+X+4oJjcEmx6
etrlctlsNnKBCjGciFgompVg5MLOjnW7Ldu+C4xMLsh8O1xQTFYJRt3E+Pg4
7U2n0zkwMED9Ak5EBHqibQlGvzdUOH/f4AvJ61jRkigmqwSbmZlhw0takk6n
2VddUIKpR9sSLHMszPllg69vRNb8PwRRTFYJxp9nQktIkN4MKMEKQsMSjI08
N+yx/e1Cz/BkUs574YJihCUYm/OnASfVX7FYjJ7q7u4OBoMq/wVcKAhhCbbi
wq7O9bu7dl4NTMwtynk7XFCMsAQjF+gBicCWJJNJKsFwRBjoicYlGOtYy51f
X+4dGF/9wDpaEsXwJRiXGV7SY9al0nIaYfr9fpRgmqBxCfZEkH9c6u0fgyBF
RFiCkSD8mJNdkZiGnSjBCkXbEuxHF8psNPKMT68+/w8XFCMswaj+smdgo1B6
ijoLlGCFom0Jxqqwjbu7am+Fp+ZTq74dLiiGlWCjo6P0mH5brf9/e3fi1raV
7g98/pf+L5M97XTv3OntTG8nbaazdzpL7/3NvdM2bTYIW0LIQnaW7GQjaRYC
BAIEjPGGwZjNxoABg9nBBv9efBqNYktClmRJoO/nycNDvCEdn+85emVZane5
XBQKdhdKMNCZ5iVYcjBp25pj/+6Wf3BiXroGwEiiGG1G0lYllWCTk5P0C40q
Y2NjrOZCCaYhzUswFpBtuR3fVvmTV+eUeo8QEMXSA8KdoJ4qLwoISrBMaV6C
sSzQv9zq/tHoOp+FIQuKUZ1F/Z9KsEgkQr9QHOgX7i521LrKP4EsZCS9BKN/
Ww/bdubaSp4E1v0sDFlQjJVgY0l2u93j8bD6i93V2dmJEgz0lI0S7Kf7m7fm
dlAV9tg1Fpe8ADxGEsXYFqbf76ef7e3tNL1yBRfbwkQJpolslGAsINtyHQ9d
YzEEJDv4AbHZbCMjIykBQQmWqWyUYD9m4XBbU886JwtFFhRjn4JRFugnbXby
rwKGEkyZbJRga1VYruOtArtjcJ2LhSELilGdxbJAQeDvi0igBAMjZKEEa96a
0771cNu3Vf6e0TnpIiB9JPEAj0TTseOsgsFgf38/lWA+n29+/sfv36EE01AW
SrC1gGw51PZNld83MreSYQlmdJc0F4mm4wIyMDBAAenu7k4JCEqwTGWjBNua
Y9+eYzt8ry8wsc7Xh5EFaRJNx0qwUCjEJgva/lxaWuLuQgmmQFY+Bcuxv57X
fuzxoIJPhI3ufeYi0XSsBKMsUAooC5SI5eVl7i6UYKAzrUsw2ry078zrOHKv
d3hy/S9Zp48kw+Ew/rF/0iMJ28Jk+/YDgQANJjR6sI1MlGAa0roEW6u/dhzp
yL3XNyTjLMQIiMqAsPPVUCGWHhCUYJnSvARb2+YscBx/NDAxu/5ZCJAFxVlg
JRg7EJfbI7G4uJhACaaU5iUYZeGdY87zdYGZRSXfBTO8B5rnn5wSLBKJUM9n
VRhtKbEqDCUY6E/TEmztkJLdefbix4OKT+xj7M4Ts5FoOv7pOGhLkm1k0lNm
Z2fZ2QZQgmlC0xLsx4AUPRyIyNjmTCAg65FoOv7pOCggQ0ND/ID4fD6UYJnS
tgSjLLxZYD9TH6TNUTnPRRakSTQd/3Qc8XicNjJtNhtVXrTNyb44jBIsU9qW
YFR/vX/MUdkcWo7LGpGQBWkSTcc/IyJVXtTzaV6guWApCSUY6EyzEiw5jLxZ
2HG2Lji9sP5uHAaHNCuWclJ6+km/2+12t9s9OTlJW5i4LpgmNCzBKCA/K+go
rQ3IOecVg4AolnJS+vSA4LpgmdKwBKMsvHvUUdEUWozJfQuQBcVSrgtGZRfb
I0EbnFNTU93d3QMDAyr/BLKQEX4JRln48ITrlm1E+ovzfMiCYinXBaNosD0S
XV1dkUiEfuK6YKAnLUqwXirBth1xvlPUUd4YWlzOYKsGI4li6ZdmJjTJsosM
0l34FEwTmpRguwtdFJC3CzsuNQzNLyEgeki/NDMJh8P8gKAEy4hGJZhzW27H
z4udN1pHZG9yrkEWFEu/NDO3R8KZhEszZ0qLEqxre4GH6q+PT7kfOMbWfw4P
sqBYSgmWSKaDyi6WBZfLhRIM9KRJCbY93/PBcefNttHlWGbb/BhJFBMswRLJ
S13Qe2qz2WhWRQmmniYl2PY89/vFzusvRpYQEL0IlmBkbGyMbqeA4GPiTGlQ
glX17Cjs/uiki7Y5M217ZEGx9BIskQxIOBymLc/29vZAIKDyTyALGaES7O+X
u3YW+T4766n3RtZ/wquQBcXSS7BE8nNh2pSiIFAc0qeMTFktC6CG+t6y/7b/
o1Oeu/bR9R+aBiOJYmIlWOJlFYYtTE2ob4SDdyggnbfbRxW8GwiIYmIlWOJl
QPApWKbUr+8/r/k+LvU+8WS2z59BFhQTLMESvCoMByJmSuX6zi+tfFnu/fSc
t6kn4/orgSyoIFiCJV5WYSjBQGfqe0tlU+iha0z63NpiMJIoRluPNFwIlmBk
cnIyEAigBFNPfSNcbl4LiPzj/PkQEMUoIOzkw2IBCQaDCEhG1K/vxYbg085x
Zc9FFhRbXl6myYKqrfS7KAK0OYqDrzKlcn0Xl1fO1QXWvRaeGGRBsbm5ufb2
9vFxgVGIqrCxsTGUYKAn9b1lfGZJkyWBjNDUOTU1xU4sLHgvd7ULxTCSJBCQ
DYsiEI1GpQOCEiwj6td3bHr9K5WA5lZWVigL3LXAUmCyUEDl+tLAMzGjts1B
AaqzaMNJrMNTUpAF0BN6y8alcgNyXegbCTTCRoaAaMtq67uZIAvastr6bibI
ApiHGXqL0+msTvL5fNyNNTU17EatnpJt6teCfla/Sv3xIWqYoW8YzgyNgIBw
T+FnhJ6rw2JLMEPf0JMZ1hdZEHwK/0ZDmKFv6MkM64ssIAuw0RneW6jKYEGb
mpqiX+gn/d6WlEhmrbGxUf1TNspacAxZixSG9w0zMLwREBDBp5iB4X1DZ4av
L7Ig+BR2o85rkcLwvqEzw9cXWUAWYBMwvLfwt6kobhQ6+qX65QdAXMrodu5h
Mp+yEdeCMWQV0hneN8zA8EZAQPhPoV8M38nJMbxv6Mzw9UUWUp6i52JLM7xv
6Mzw9UUWEsgCbHyG9xZ+9cHClTIUVKcdj6fgKdmmyVpwd5lkV7/hfcMMDG8E
BCTBSwR3tAn2UejP8PVFFrin0AMoC/QLy4Kxh6wnTNA3dGb4+iILCWQBNj7D
ewtGkkRazWWGzcuECfqGGRjeCAhIylPYw9jXAXRcAwGG9w2dGb6+yEKCt9lJ
D2M3si9I6rgGAgzvGzozfH2RhQSyABuf4b0FI0ni1RKMxhDDvwXGGN43zMDw
RkBAEmn7KMSeojPD+4bODF9fZCHx6mYn9wBkQWeGry+ykEAWYOMzvLfwN65k
Hp+s4CkbZS3Y7fzvhRnI8L5hBoY3AgKSeDUgHEy1OjN8fZEF7imGbzynMLxv
6Mzw9UUWEsgCbHyG9xac2CdlAKmpqTH8YGbG8L5hBoY3AgLCPYW/t5OegpPS
68zw9UUW+E/hNlmRBf0Zvr7IArIAm4AZeoucC0PwT4kj8yk602ot9N8TJcYM
fcNwZmgEBETwumB6LrwgM/QNPZlhfZEFwacYPmWYoW/oyQzriywgC7DRobeA
GPSNBBoBxFmtb1htfUE+q/UNq60vyIe+AfKht4AY9I0EGgHEWa1vWG19QT6r
9Q2rrS/Ih74B8qG3gBj0jQQaAcRZrW9YbX1BPqv1DautL8iHvgHyobeAGPSN
BBoBxFmtb1htfUE+q/UNq60vyIe+AfKht4AY9I0EGgHEWa1vWG19QT6r9Q2r
rS/Ih74B8qG3gBj0jQQaAcRZrW9YbX1BPqv1DautL8iHvgHyobeAGPSNBBoB
xFmtb1htfUE+q/UNq60vyIe+AfKht4AY9I0EGgHEWa1vWG19QT6r9Q2rrS/I
h74B8qG3gBj0jQQaAcRZrW9YbX1BPqv1DautL8iHvgHyye8tHbCJaNs3NjH5
jWD0Wwpa0rZvbA7y19fodw+0pG3f2Bzkr6/R7x5oSdu+AYDeAmLQNxJoBBBn
tb5htfUF+azWN6y2viAf+gbIh94CYlT2jZ/85Cd79+4tLy+nX/x+v1ZLJdOX
X365b98+9UuFgICYjRKQPXv2FBUVqV8AZAHEbOgsKPjryAKIUdM39Nxq0ioL
oAZGEhCjsm+89tprBw4c4Gf59u3be3gENwu1IlaCpS+VNAQExGgeEH46BHsv
n8/no4dduHBh3T8kljVkAbSyobOQaRASyAKIU9M3BLuiybMAamAkATGazKr1
9fWUZXYLK8HopxZLtw7pEoy/VNIQEBCjeUD4M+y6s61WJRiyAOpt6CxkGoQE
sgDi1JdgKV3R5FkANTCSgJh1+0Z5eXlGLyhYgjU0NNCN9JOKJv7wwv/IjD2F
G1vYjfR47kVoJOEeTC+VeFmCsdck9NyMFpWDgIAYzQPC7/+sn1O/5X5JvOzn
iWT33vMq7kXoFbgb2bPYVJv+yEwhCyAGWQBgrJYFUAMjCYiR7htsP8mWLVvk
v6BECUbjAw0L7AENSVwxxW70JXFjBf+l2DCSUmSxsYhegT1L8UGPCAiI0Twg
e9J2QVAHFpxqEyJ7O9k8m/6y7BVYrOTsIBWELIAYZAGAsVoWQA2MJCBGTt94
7bXX5A8mKd8FY5Fn8U8pkfg7ZxiumOI/i5VgghUW/0BElGCQDZoHROVUK3YI
Ctf/5R+jIghZADHIAgBjtSyAGhhJQEx63/iJCJkfrEt8CpZyI39I4WS1BKMh
UfDgZwQExGgekD2yDzhJZHOqRRYgU8gCALMpsyAWBFAJIwmIWbdv7N27N6NU
yi/B2CNTxgSxEox9yM6OWuRkWoKJDYkICIjRPCDcVMs/epZNtdynwClTbUrH
ZsffphyUm+lmJ7IAmUIWAJhNmYWMakaQDyMJiJFzSHNGLyi/BEu8HGE4CfES
LPHqV03ZjZmWYOwsrJhqQT7NA8Lv8PwJkfuSNQsFdzs/I+kP5vZLZLrZiSxA
ppAFAGZTZkEsCKASRhIQY6m+ceDAARxwAhnZrH0DWYBMbda+gSxApjZl3xAL
Aqi0KXsLaMIifcPv97MP2QXvtUgjgAKbr28gC6DM5usbyAIos8n6hnQQQKVN
1lusY3p6urm5uUkeu92+tLSU6Z9A30igETashYWFjAKyuLiY6Z+wWt+w2vpu
GtFoVGYQiMvlisVimf4Jq/UNq63vphEOh+Vnwev1rq6uZvon0DdAPk16y3J8
9ZFrzBuaXcm4t4JCkUjkyZMnZWVl165deyTphx9+KC8vV/BGYyRJaNQIsZXV
x64xz9BMHAnRy/T0tMyAPHz4kAJis9ky/RNWC4gm67uwvPLAEe4ZmVP/UiDT
2NgYzQKUhZs3b647WdDDurq6Mv0TyIIC0fnYA8fYwPiC+pcCmQKBQHV1NXXy
27dvS2eBPSwYDGb6J6yWBVBDk97SG557v9idW927uLyi/tVAPhoiaEhZ92G0
kdnU1JTpi2MkSWjUCAPj8z8/7jp8r3d+Ka7+1UA+BERDmqyvZ2jmzULn8ccD
6l8K5JudnaUsRCKRdR9JZZrD4cj09ZGFTK2srrb4p94ocFx4lvFGPqgxOjpK
WVj3uKDV1VV6mN/vz/T1rZYFUEOT3nKjdXhXoffLCu/CcmZbmCUlJTTgq18A
pq+v7+uvv6afgvc+evSI7lX2ymqemyVjY2OVlZU0RNB4su6DafmxhamMJo1w
yza6u8j7Rbl3ZiGzI3wQEMWi0SgCoi1N1rfseWhnUfc/r3VneoQPsqDY8PBw
eXk5ZYEKsXUfXFVVhRJsXerXdym2cqImsPOo79DdjDfykQXFqKQqS5LzYJRg
kG2Kewt//vxHpXd7vmfvWffUXCy+sto9PDuzGMv8EFq1LDWSLC0t0ZqmbGF6
vV7BNxRbmIppEpD/vtJFAfnsrHtiZmllddU3Mju9gIBk3eDgIAKiIcXru/Ly
+NtYfPV35907Cjr/fKmTNkGXYytdoZn5DHfcacJSWaBql3p+SgnW2toquHmJ
EkwO9VmYnF3+r9Mumhf+91o3/XdxeaVrmLabDDiOyFJZiMVidrs9pQSrq6sb
Hh5OfzBKMMg2Zb1lKLJw8VkwGFn7AnswsvBuYfv23PYPj9uHIouhyYW/X/Xf
aBtdkfG1F7Yzh40AFy9e/DqJYpv+MO5e+p27/euX2OjB/VfwXjYacK/DvQh3
C3+3Uk5ODrvxxYsXiVdHErqLvwxGicfj4XA4ZQvz6dOne/bsobk15cHYwlRM
WSOEphYvNQwNJg/yH5pc+OCofVtO+y+K7YGJxZGpxa+u+q+1jsTi68+2CIhi
tNmJgGhL2fr2j8+frw+Go2uH/fSMzu3KbduVZ//1aefE3PLA2PwXFb5qR1jO
6yALitFk0d/fn1KCXbt27fPPP0+5WmsCJZg8CtaXRqTukdmyhqHJ2RhtG9n6
olsOtlIW/nTRM7u00jk0Q1mo9U7IeSlkQbGlpSW2O4J/Iy3YF198kV6FoQSD
bFPWW0rrAtsLPPcdY/T7tRcj7xXZ/3jR806hrWt49oV/amdh53+WOAMT8+u+
TspIkkgeiE5RTX8YCzJ7JEs3G174T+HvzKFb2MjA3ctGA3YjPZGNBtwQwX/l
9Hu5X7Q9AEANdjxz+nFWFRUV6RuZ2MJUTFkjnK0PbM/33O1YC8iN1pEPjnb8
4aLn7QJbZ2i2tXdqd1HnhyWugXEEJIsikQgCoi0lm52JROHDfpos6rvWvoV0
oWHo7YL2P1/yfHC0nfo/3bjrmP/Ts56JmeV1XwpZUCwQCLAs8EuwlZWV4uLi
9CoMJZgcCtZ3fnnl+zv+7Ucc7f3R+Mrq8SeDb+bb/njR/fFJR2hysdoxvrtk
4Ityr5zvCyMLirH6K6UEW1xc3L9/f3oVhhIMsi2j3hJbWTt+PzCx8PEp567i
3nPPhhaW419d6f79Bc+N1uHdR9qa/FO328O78x3bjjj33eq92jJ8uTl0uZl+
Dlc2he7YU7+UwR9JWIrp59dpn1xzg0YiOURQrlM+OmdP525kv3BPZ/fyd8hw
f4U/MlxM4h7P/3PcjiCTDCPS0jcysYWpmIKADEUWPjlNAek7Uz+0uLzy/675
fn+hkwqx14+0Nfgm77SHXy+ggLi+qeq90hy6spYRBERXCIgymWWBtjJX1z72
+qC4Y0eR72rLyMJS/E+XOv94kSaLkZ05rfbB6SvNI1tzHVsPtx+823ftZRDY
v7vIQvYJVmEoweTIaH2X4ys0NdgHom8U2F8/2lXdEZ6aj/3mrPuvFd7LTSEq
xFzBmfPPQtsLOnfmtuf/MHDjxStZSH9BZEFzglUYSjDINvm9pWMweq4+eKlx
6OsbPdsOt23PbT94p7d7ePa9Invx40HfyCyNHnfsY0fu975XZPu/G/7/OuX6
1YkO9u/jk46PSjr+WtGZ8pqKRxL2MLGRhN3LlzKScI/k9vkkXo4k/IVJpI0k
6TuaDEHvWqkkmlVpI9PpdLLHYwtTMfmN4AhMn3+2FpBvbvp35Nq25bR/f9vf
FZr54Kj96KMBCsjuXNut9rGCH/rfP2r73+s9n5xypwXEm/KaCIgyMgPCnYge
AZFD/vq29k2V1gYuNgz9v6vdPz3UtuuIPf9Bvzc080ae7UxdsGt4dush2w+u
8YN3/O8W2v51w//LE06KABeHX51w/ONy6nnRkQVlGhoaJIJw6tQpCgLFgdvU
RAkmh8z1pcqrwRc5/XSQtp3+Vtm1Jcf+VmHHyZrAWjmWZ6tsGm7vj2471PbY
PfHNTR9tOP3rZu9/ljg+/ncQ1qaG9JdFFpS5f/++RBaKi4s/+eQTqsK4AydQ
gkG2ye8t9x1jf7jo+d15194z7px7fX+44P78nKv8eWjbwdbWvujMQoyGlNO1
wd+ccX1Z3tk3Nt/aO9XUM8n9e94z6RicTnlNfXbmMOp35rDHmGF/Tl1d3SFJ
NKXSYNLS0sIejy1MxeQ3wg/O8T9d+ndA/njR/ZuzrrLG0LZDrS3+qdnF+Jv5
Npp8P08GxD8619YX5QekCQHRjsyAPHz4kD0eAZFD/vrebBul2eH3F9y/OefJ
re6jUPzuvJsmiy0HXniH5yZmlrcebD1XP/TrUx3/c7VrKLLY/GoQmvxTzgCy
oI07d+5IZ4FKMMoCtzsCJZgcMtd3KbZS9jz02RknZeF359ey8PlZ558vec7W
BXfn2gYnFvvH5rccbD1bH/zkZMe+qp6RqUXq/83+Kd6/yfSXRRaUoZJKIgj7
9++nIFAcuLILJRhkm/zeMjG77AhMdwxGaUNxcna5tDbwZoH916ddvyxxROfX
TrX9n8c7/lHp3ZHTln+/X+YlaBWPJPwb6RW+5h2WnHJIM7fbh40G7LlihzQL
3ss9N7HeuYNMgjYs+ZuXCWxhqiC/ESKzy86XAZmai52tD7xVaP/k1FpAInNr
X3X51YmOv1d6d+a0HanuW5ZxLo4EApIdLCAVFRXcLQiIHPLXNxxdtA9O2wei
zsAM5eLYo4Hdee2flrr2nHZRz19cjr9TYPvq8loWTj4ZlPmayEI2UApSJguU
YHLIXN/V1cTw1GL7QJSy4A7OjE4tHb7Xu+vIWhb+fHHtoKDx6aXXj7TSvPD6
EVt545DMv44saI4dlJtygDpKMMg2xb3lkWtsd75je77n6MPB5fhawfX3Cu87
RR3b8t3XWoZj8ayXYIm0U/ckXp6Qp+/V8/xwJ+dh5+ShW/gfi2d6Yh/B773q
T+y6YOn1VwJbmCooboQn7vGfFTp3FHQWPOhnlyz/7ytd7xTZt+e7LzeFluSd
fBgBUUzsumDp9VcCAZFH8freso1uO+LYlttxpm7tKrTx1dXfnXO/VWDfmttR
3SHrdIgJZEEFseuCpddfCZRg8ihb3/jK6qXG0I7Cru05tivNI3RLdH7516ec
b+S378qz13vXv3A2gywoJnhdMMH6K4ESDLJPcW9xBmbeLOjYethW3xVhn3nl
P+jbccSxJae93jsh81MwUEzwumAtLS3pU2oCW5gqKG4EV3Dm7cKOrTntTzsn
2B6Joof9O/IcW3PsTz3jMvdRgBrp1wVjAUmpvxIIiDyK17eld2pbjm13nt3W
H02snSZx9ftbPduOOHfk2mx9U5ouIwgQvC7YvXv3BCcLlGByKFtfGvYfeya2
57neP+bwhtbei7nF2NpVIws63z3a0RVa/8LZoJLgdcEuXLggeLESlGCQbYp7
y1Bk8b2ijo9KOkKTC+yW8ueh3UWetwpsnqHZVWxgZpngdcFoDHn69Gn6g7GF
qZjiRghNLv78mOPD4x3ByI8BudI8/MbRzjfzbc7ADAKSbYLXBaOA3LlzJ/3B
CIgcitfXPzr/el77nlLn1PyPJ58vrQ1sy3P//Ji9f2xBuwUEYYLXBXv8+HFd
XV36g1GCyaFsfVdWVtv7p7cdbvuirJNdhXkptlLww8COQu+e047RqSWtFxNS
CV4XjPo8911IPpRgkG2Ke8vi8krRo8ClhhB3hdka9/gbx7p/XeoejWIkyTqx
64IJwhamYsoDEls5+jhw8dkQd8xhbefEm8Xd/3XKxe21gOwRuy6YIAREDsXr
O7MQy70/cIV3eu277WHa7PzteTfdpdHSgSjB64KJQQkmh7L1XdsvNL10uLr/
VtuPg9JyfKXi+fDOo76/V3qX5R2dDmoIXhdMDEowyDY1vWVseml6fpnbnd8x
ML2rwP3X8i451xYETdAQEQqF1n0YtjAVUxuQhRgXEMfg9BuFni8ueWcWERCd
yAzIw4cPEZB1qVnf0ejiLK/aeu6b3J7v+efVbnwarA8qvigL0Wh03UfevHkT
Jdi6FK/vWhUWXZp7OQXEVlYfOMd3FHYdvtur3dKBFLb7Oh5fZxamdwolGGSb
hr1lcGLh7QJ73v0+macaADWmp6ebm5tpiLh9+3aTpIaGhsrKSsHP2aVhJElo
2gjByOK7Rfacu73YR6GDhYUFmQGpr6+nh3FXcJDPagHRcH27hmd35drknw4R
1KDKi3Xy6upq6SzU1NTQw9xud6Z/AllQZmV1tbUvujOnraxB7ukQQY1wOMw6
OdvtJoEeQA/r7+/P9E9YLQughoa9hTYsr78YdgWmcS4OHUQikSdPnjySh6ow
Ktky/RMYSRKaNsLC8srN1hHHIAKiB+rwGQVEzgcEKawWEA3Xd2YhdqV5GOcf
0MfY2JjMILDjJRYWMj5SGllQZnU1MT6zRFnoHZ3T5AVBWiAQkJ+F1tbWWCzj
I6WtlgVQA70FxKBvJNAIIM5qfcNq6wvyWa1vWG19QT70DZAPvQXEoG8k0Agg
zmp9w2rrC/JZrW9YbX1BPvQNkA+9BcSgbyTQCCDOan3DausL8lmtb1htfUE+
9A2QD70FxKBvJNAIIM5qfcNq6wvyWa1vWG19QT70DZAPvQXEoG8k0Aggzmp9
w2rrC/JZrW9YbX1BPvQNkA+9BcSgbyTQCCDOan3DausL8lmtb1htfUE+9A2Q
D70FxKBvJNAIIM5qfcNq6wvyWa1vWG19QT70DZAPvQXEoG8k0Aggzmp9w2rr
C/JZrW9YbX1BPvQNkK8DQJzR3dN4Rr8DYGpGd09dGd3YYGpGd09dGd3YYGpG
d0/YMIzuqmBqRndP4xn9DoCpGd09dWV0Y4OpGd09dWV0Y4OpGd09AQAAAAAA
AAAAAAAAAAAM09HRMQkgBJ+nJxAQEGe1gCALIAZZAGCslgVQAyMJH1qDDyNJ
AgF5FVqDz2oBwbvPh9bgQxasDK3BZ7UsgBrIDh9agw8jSQIBeRVag89qAcG7
z4fW4EMWrAytwWe1LIAayA4fWoMPI0kCAXkVWoPPagHBu8+H1uBDFqwMrcFn
tSyAGubJjt1uf/HixejoKP9Gn8/X2NjY39+vzzIY2BpDQ0NNTU1ut3tiYsKo
ZUiBkSRhmoBEIhEKSEtLy8jICP/2np6ehoaGvr4+fRbD2IA0Nzc7nU4ExCgm
yQJ1AAoCxWF8fJx/e2dn5/Pnz4PBoD6LYWBrDAwMUOq9Xi8NC0YtQwpkwRCU
hWfPnqVvNtDiURbC4bA+i2Fga/j9/vr6+t7eXqMWIJ3VsgBqmGQkoY2ro0eP
Hjx48IcffuCqsK6urtLS0u+///7y5cuDg4M6LIZRrUFT6qVLl/bt25eTk1NX
V2eSjUyMJAnTBOTFixfHjh2jgNy/f58LSHd395kzZyggFRUV1IV0WAwDA1Je
Xk4Byc3Nffr0KQJiCJNkgUbIgoKCw4cP19bWclWYy+UqLi7+7rvvbt26RdW6
DothVGvQNufp06cp9UeOHKFS1CRVGLJgCJoO8vLyaLOBJghuVLTZbHTjt99+
y9+ayiqjWqOzs5O2G/fv319YWOh0Og1ZhnRWywKoYZKRpLGxkSaUQ4cOHThw
gMYNmla8Xi9NNDSl0vBy4cIFffbzG9IaNKVevHiR1vT7JFpf2shM2cFrCIwk
CdMEpKmpiWZVFhCadmm29fl8VH+xgJw/f16f3YBGBaSsrIwLCG17P3nyZGxs
TP8lSWG1gJgkC48ePaI+cDCJqjC6xeFwHD9+nGXhypUrm7gEY9Pivn37WBxo
0mxubjbDHglkwRC3bt2iGYFqkNzcXOoJk8m92QUFBSwLd+/e3cQlGP3R4uJi
Lgu01iZ5U6yWBVDDJJ2WKg7arKJhhGZVGjouXbpUUlLy7bff0vBC25k07+iz
GPq3RldXF/sgg0YSWnf6hYZT2tJ++PChbkcRiMFIkjBTQKgwZwGh7U+q2U+c
OMECQptkmzggVGmeO3eOC8j+JPrlwYMHCIjOTJIFqr6rq6vZ7giaLCoqKgoL
C6l70H8pF7odkqR/a7hcLqo0KQu0zUmrzyYLGg3q6+sN3yOBLBhiZGTk+vXr
rAqjevzKlSs0R1AW6L+67YuYNCILNpstPz//uySKAP1kdWhra6vheySslgVQ
wyQjyWRyI7OmpoZCRFGiQLEp9ezZs1Sk6LYMOrcGrRqtIK0pzacnT56kv04b
lgdfMrwKw0iSMFNAaGapra2leZZywQWktLR0Eweku7ub6i9WfFHJSX+dQsHS
QetOYdFnH68YqwXEPFmgiuPevXusDGFZoC5RVlam51dCdG4Nqr9ojmCTBYXC
4/HcvHmT5koKAt1ieBWGLBiFxkCqwqj/s8+D2H45ukW3+mtS9yy0tbWxvS60
1hUVFTQDlpeXs71zrAoz9iAiq2UB1DDPSDKZ3MikqSQ/Pz8nJ4fCdfHixZ6e
Hj0XQOfWYJ9r0MqeOnWqs7NzMrlpQRuZdAs1As2zPp9Pz+VJgZEkYb6ANDY2
FhQUsICcP39+cwekrq6OBYQ2PmmbczIZkMePH7OAnD17lmo0PZcnhdUCYqos
0FbWo0ePqHuwgxKvXLmiz9chOTq3BpWch5Mo9X6/n24Jh8N3796ldacs6PZt
UDHIgoFoVGQ9ge2bunPnjp7116TuWaCwUxBoTSsrK9npd0Kh0NWrV+mWvLy8
GzduDA8P67k8KayWBVDDVCPJZPLMby0tLbRxdfPmTf3PcqNza/T391+7dq2s
rIzVXwwNp0+ePDl9+nRTU5OxH6ljJEmYLyCTyVNzUHl+/fr1TR8Q2qqk1bx0
6VJKQGpqaiggVI0iIHoyWxZosnj27FlpaSltf+pzviY+nVuDyi4KAm18svqL
oSqMSjNqAZvNhizoyWxZoHf/8ePHp06devTokf4FiM6t4fV6aROxqqoqEAhw
N7JjMul2miyMPUeN1bIAaphtJJlMDiajo6OGHFahf2vQatI0mjJi0I00nhh+
Rg6MJAmzBoT6jBUCQrkIJ6VsXiIghjBhFqgPsMlC/40u/VuDZQGThRmYMAsG
9gT95wXB1FM66HZ8Fww2EBOOJAZCa3BoHMNIkkBAXoXW4FgwIHj3+dAaHGTB
4tAaHAtmAdTw+/36H8IB5jcwMICRJIGAgAgLBgRZAEHIAgBjwSyAGtFo1OFw
YDABvomJCeoVGEkSCAgIsWZAkAVIhywAMNbMAqhEg4nf7+8AeMnpdFKvMLpj
mgUCAiksGxBkAVIgCwCMZbMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADR
aNTv93cAvOR0OqlXGN0xzQ7BAT6kRg6kBviQGgCwLBr9HA7H2NiY0QsCJhKP
x6lX0Pxo9IKYF4IDKZCadSE1kAKpAQDL8vv9mBAhXTgcxrQoAcGBdEiNNKQG
0iE1AGBNGPpADPqGBDQOCELHkIDGAUHoGABgQRj6QAz6hgQ1jbO6uqrhkoCp
IDUS0DggCB0DACxI/dDXFZqZX4prsjBgKpgWJahsnL7w/NTcslYLA+aB1EhQ
2TihycWRqUWtFgbMA6kBAAtSP/SV1ATLG4dicezY11ssFltZWRG7V/1HLZgW
JahsnMvNI6efBiZmUIXpLR6Pi6VmNUnl6yM1ElQ2Tq138tijQf/onFbLAzLF
k8TSoT44SA0AWJD6oe/gnd4PSrxVbSOaLA/IRJuRLpdrdHRU8N65uTm6C9Ni
9qhsnDN1wfePe87UDeETZJ15vd5gMEjbk+l3LSwsUGpisZia10dqJKhsnAfO
8Q9Pdh68NzCKz8L0NTAw0NfXt7S0lH4X3Tg2NkbZUfP6SA0AWJD6oS+3und7
vuf9Yudj94QmiwRyUHlF793w8HBKnUX/nZ+f7+zs7O3tRQmWPSob5+Kz4BtF
njcKHVdaRhZjoh9lguYoGoODg+klGG1J+pKWl1V9NInUSFDZOE/c4+8f92w7
4ih+PDiJ43h1RPVXT09Pep0Vi8X6+/u9Xu/s7Kya10dqAMCCtCjB+nbmO7fl
Of/zhPNpJ6ownVB55XA4Ukow+n1ubo42Mtva2mjSRAmWPWpLsIaht466thd4
3inquNE6iuN4dSNYgi0uLtIWZmtra3d3Nz4Fyx6VjfPYNf4fJa4dhd7dee2n
ngaj86reKZCvt7fX7/dTTPg3Li8vU5RorvF4PCjBAAAypVUJ9tODL7YdcXxU
4mjxT8l/7k++6kr5p3JhrEOwBJuZmaHZsL293W63owTLKk1KsC2HbZSadwvb
7zvGVmS/WUiNGukl2Pz8PFVeFBmbzebz+VCCZY8WJZh7W27H1hz763m288+C
8o/jRWrUoNkkpQRbWlrq7++nN5RS4/V65+ZUfUEPqQEAC9KwBPvpgRbanvzs
rNvePy3zuZgWFUsvwaanp51OJzs6saurCwciZpVWJVgyNWufID9xT6zIe7uQ
GjVSSjD2qXF7e3swGKT6q6enBwciZo9GJZjjpweaqRB7u7D9SvPwwrKs43iR
GjVSSjD6hf5LqaEqjCaa7u5ufAoGAJApbUuw5GdhHb856/aGZA3ImBYV40ow
9t+pqSn6L72b4XB4ZWWF5kSUYFmlYQnG9l388oSj0Tcp5y1DatRgJRj7qGt6
epp9ahwKhSg1tJ1JwRE854B8SI0EDUuwtdTkdrx/tONWm6zjeJEaNdh3wVgJ
trCw4PP5bDbbwMAA5YjmIK/XOzMzo+b1kRoAsCCNS7AfqzDHlxXeHhmnDsa0
qBj/U7DJyUl6H+m/ExNr38WLx+P4FCzbtC3Bkqlx7j3rftE7te6bhtSowX0K
RhuNbrfbbrePjo6y09T7/X6UYFmlXQnWwu27+LDE8cA5FlvvI2SkRg2uBKP6
izJC9VcgEGD7MYaGhlCCAQAooH0JdqBly8HWrTn2v1d2+UZmpbcnMS0qRuWV
0+mkEmx8fJzeRJfLFYlE2F20PYkSLNs0LsGSqaFty9+e87T2TUlvTyI1atDm
IpVgFBaKDL2JXP2VSJ5zACVYVmlegm05+GJbbsevTroeOMakzyyK1KjBDkSc
mJhg35oMBoPcVyZRggEAKJONEuyn+5u3Jr8x/dg9Ln2ICKZFxdinYDQt0k+b
zca/QBhKMB1oXoKtpSbHvj3fU9Y4NCd5kgGkRg2Khs/no/qLUpNygTCUYNmm
eQlGqdlyuH17QSdNQ5FZqS/xITVqDAwMUJ3l8XjYuXb5GUEJBgCgTBZKsGT9
dait6OFAMLIgXQOkT4se4JFoOlaC0fQXCATsdjttWM7OzrKaCyWYDjQuwZL1
19bD7ftu+buGZ+MZfgpmdD81F+mWZwciUnAoPvTgaDTKxQQlWLZpXIIl6y+a
br4s977oncp0d5/R/dRcpFuefQoWCoXokU6nc2xsjPvsGCUYAIAyGpdgyc+/
duV1nK0NTMysvyWTPi0Oh8P4x/5JT4usBBsZGaHfaWakKoweT/Mg3Y4STAda
lmCs/sppz7vfF5hIvfhpOqRGcWoSyRIsEAhQNGgzkhJE25OTkz+eBQUlWLZp
WYJRag63b8mx/++NHs/Q+tv/SI2a1LASbHl5ORqNut1udgQv+wQZJRgAgDKa
lmDN2444f5bfXv48NLMg69o62DMpTaLpUs6ISL9QFeZyuWgqxBkRdaBZCba2
18KxI9d27NHAaFTWxj9SI0269fhnRGRVGIlEIhQWnBEx2zQrwZJ7Lbbl2Pbd
8vtlnPcpgdSsR7r1+GdEnJqaosfTdDMyMkJzTSgUQgkGAKCAZiXY2imCHe8e
ddxsG8HlMnWQfl2wcDhM76bT6WRfmkYJllXalGCH2ig1u/Paz9YH5XxqzCA1
aqRcF2xycpKdl4Pi4/f7cV2wrNKkBGNfNN6eY8u93y/nU2MGqVEj5bpg09PT
XV1dVIVR/UVpwnXBAAAU0KIE66USbHue++fFjmp7eFnGJVo4mBYVSy/ByPj4
OJVg7AJhKMGySpMSbEeB960Ce1ljaFrep8YMUqNGSgmWSO7VZ8dWEZ/PhxIs
e1SXYGO/OOHZUdS960h70cOBkalF+c9FatRIKcEI1VxUebHUeL1elGAAAJnS
5FMw2pL85SlXbeeEnEtk8mFaVEywBCORSISqMJvN1t/fjxIse9SXYLsL3O8V
u262js4tyv3UmEFq1EgvwRLJvfp0e1tbW09PD3e2bWWQGgnqS7B3j7l3FzhP
r33XOLNKGalRI70EI/Pz85QXSg2VYPS7mtdHagDAgtQPfd/f8n96trO+a0LB
czEtKkblFb136SVY4mUVhhIsq1Q2zqmngU9KPVW20SXJixkJQmrU8Hg86SUY
mZmZobvwKVhWqWycex3hT0rdp2uDU3MZv0dIjRr874LxUeXV3d1NJdjcnKxv
5IlBagDAgtQPfbdsIy3+yRVFW/uYFhVbWVnhn44jRTQaHRoaQgmWPSobp8Yz
XuudkP+tST6kRg3+6ThSzM7OUmrwKVj2qGyc9v7oA0dY/rcm+ZAaNQQ/BWMW
FhZoGsKnYAAAmVI/9EXnVW2xgDJUXs3MzEjssVe5JZnAtChJZePMLMRWJC/+
BVlCdRZtSYrtnaDUYMdF9qhsnLmluIJPjUE9qrCo1BKLRjwe5y4TpgxSAwAW
hKEPxKBvSEDjgCB0DAloHBCEjgEAFmSGoc/pdFYn+Xw+7saamhp2o1ZPyTZN
1oJ+YbfQE3VYZmlm6BumZXjjIDXpqTFDcAzvGGZmeOMgNdxTuFvI1NSUHsst
zvCOAQCgP8OHvmAwyGYNmgW4uaAtKZGcJhobG9U/ZUOsBfuF3UuPZ881kOF9
w8yMbRykRvApZoDUSEBqTLIWdAu3s4Kegh0XAAD6M3zo428+0dxB0wH9QtME
zREJ3pRBt3MPk/mUjbgWHEMm9xSG9w0zM7Zx5EeA63IbNzXrrgX9wv84wFhI
jQSkxjxrweEKNAMhNQBgQYYPffwZgc0UKfMaN7moeUq2abIWYvcaxfC+YWbG
Ng5Sk+ClhjsEC4dUmRxSo57mc43P58OnYAAA+jN86MO0mHh1WmT7JLExaXLY
mFRPw7VgD2Nfb9FxDQQgNRKQGvW0LcHYcw3/EBmpAQALMnzow7SYENozyQox
Y6sww/uGmWFjUj3NUyP4FJ0hNRKQGvW0TQ092PDDLRJGdwwAAEMYPvTxZwSZ
B9sreMpGWQs+bEya2Ub5Vouap2yUteBDaswMqTHPWpjk8y8GqQEACzJ86MNZ
qvhnqeIOo8IhVSaHc7uZZC1SUoNvtZgZUmOetTB8ZwUfUgMAFmSGoU/OVU74
5xKU+RSdabIW/Csc4btgZmZ448iMAL/LbdDUJNZbC35q9Fx4QYZ3DDMzvHGQ
GvYU/kXBzDDdGN4xAAD0h6EPxKBvSEDjgCB0DAloHBCEjgEAFoShD8Sgb0hA
44AgdAwJaBwQhI4BABaEoQ/EoG9IQOOAIHQMCWgcEISOAQAWhKEPxKBvSEDj
gCB0DAloHBCEjgEAFoShD8Sgb0hA44AgdAwJaBwQhI4BABaEoQ/EoG9IQOOA
IHQMCWgcEISOAQAWhKEPxKBvSEDjgCB0DAloHBBk5Y5RXl7+kySjFwQA9Gbl
oQ+koW9IQOOAIHQMCWgcEISOceDAgddee83opQAAXWHoAzHoGxLQOCAIHUMC
GgcEoWP4/X58EAZgNfKHvg7YRLTtGxYkvw1h09CwY1iT/DaEzUSrjrGJoQQD
sCAMfSAGfUMCGgcEoWNIQOOAIHQMlGAAFoShD8So7Bs0oezdu5d915jmF62W
SpDP59uzZ09RUZH0w/bt2/fll1+m365gUREcEITUSEBqQBBSgxIMwIIwJ4IY
lX3jtddeO3DgQMpcQ7PSnpdu376txWKuYdMizXrSDxObFgUXVRqCA4KQGglI
DQhCalCCAVgQ5kQQo8m0WF9fz80sRUVFNHlpsWgKSU+L/EVdF4IDgpAaCUgN
CEJqUIIBWBDmRBCzbt8oLy/P6AVpVkqfFi9cuEBTFZsxud2VbE9jyj5MdiM9
nt3ITXDsZdP3TPJfgXskPYt7fENDQ0bLz4fggCCkRgJSA4LkdIyMgrPhUiNW
glHJhtIMYLPCnAhipPsG24+3ZcsW+S9Isxs3T3FTEpvm2KH1bHKk6Y//LG5/
JjdXci/FP7wkZVoU3AnJJkT2rPRpNCMIDghCaiQgNSBo3Y6RaXA2YmoED+hl
V23O9hfcAMAQmBNBjJy+8dprr2W0PZl4Oc1xsxKbFtlUyCY7NmNyD2N8SWzP
JN1Lj5GeFrkdmPzvTfPnSraLMqMl50NwQBBSIwGpAUEyO0amwdlYqTlw4ABV
W5l+Sg4AGxfmRBCT3jd+IkLBrMEdKCI4LbIb+fNjptMik3LMSabTosRBIAgO
CEJqkBrIlGDH0Co4GyI1ieSRlrR2FB/+jSxN+BQMYFPCnAhi1u0be/fuVXyY
uuCeScG5UtmeSQ57JHtWptOixIyP4IAgpAapgUzJ6RiKg7MhUpNIBqe+vj79
RnLgwAEFKw4AJoc5EcTI+VZLRi/IP0swNz1xR3Ew3IO5W7gpUmxa3PMqbgbk
buGmv0ynRbZbEhuTIB9Sg9RApmR+F0z+C2641IidjoOlCSUYwKaEORHE6NM3
+DshzYYdnC94F4IDgpAapAYyhdSIlWAsTTgQEWBTwpwIYqw8LbIJUWK/K4ID
gpAapAYyZeXUMOkl2LppAoCNDnPiBhWNRmtqah7J09LSMjc3l+mfwLQoAcHZ
iJaWlurr62WmpqGhIRKJZPonkBoJSM0GRW+czNTU1taGQiEFr5+NxU5h5tTg
0swAFqTJ0Le4vHK5KdTaOxVfWVX/aiDH9PR0c3NzWVnZ7du3myTRlmRlZaXN
Zsv0T2B7SYL6xqGw3G0frfNOzC/FNVkkWFc8Hm9tbb18+fL169elU0OuXbtG
25OZ/gmkRoL6xqEJ5lnXRHVHODK7rMkigRz0xlFkrl692tjYKJ2aqqoqCo6C
18/GYm8gKMEALEiToa97eObdY+6Dd3upFlP/aiDTwsIClWBydjk+evSIJsdM
Xx/TogT1jROKLHx2rusfl7tHokuaLBLIsbS0dPPmTTlvH9vzn+nrIzUS1DcO
VV7/qur/7FynOzijySKBHLFY7IcffqD6a91H9vT00KyU6esjNSjBACxIk6Hv
clNoV6H3LxVdme7PLykpoc0h9QvA9PX1ff311/RT8F7amqJ7lb2ymudmyejo
aFkS/bLug1GCaU594zx0jb1X0rXnbOfg+Hymz9UwOJZKzcLCQnl5OaXG4XCs
+2B6DEowbalvnPb+6J5zvg9KPM09GR8jitQoVlVVRamRM4lQKYESTAGUYAAW
pHjoW+Edc/hFWef2/M7PzrgmZ5dj8RWaJSfnlvU/JNFS02I8HmdVGL8E83q9
LS0t6Q9GCaY5ZY2zykvFobv+7XmuD0uc3cOz9F9XYHokuriqe2wslRoSDoev
X7/OL8EGBwefPn2a/kiUYJpT3zgVz4d2HHG8fdRZ4xmn//aG5/rG5vQ/AN5q
qYlEItXV1fxJZHx8/M6dO4uLiymPRAmmTHl5ecpFmQFg01M29PnDc3nVvf7R
tTM89Ibn3ylo35Fr+/B4RzCyGBif//0l38XG0IqMaZHtlmTT2cWLF79OSt/s
oYdx99Lv3O1fv8SmQu6/gveyqY17He5FuFv4O0hzcnLYjS9evEi8Oi3SXfxl
MMrS0hKtV0oJRvXXJ5988vDhw5QHowTTnILGCU0uHn880NYXpTorPL30m7Ou
rYfb3ilsbx+YHp9e+ufNvqJHg1Nzsr7hIic4SI0gKriuXbvGL8HYNYAqKipS
HokSTHMKGicyFytrHHrgGIutrM4sxL+92bM1x/6zfNvt9tHphdjRx8FvbvUO
yPscGalRLBQKUcGVUoJ98cUX+/fvT6nCUIJlil35S/C6zACwuSkb+o496t9R
6L3XMUa/lz0PfXCs428VnW8X2jpDs809U7uKvB8UO1mBJi1lTqRb6L8076Q/
jM1K7JFsqmJzJf8p/D2TdAub5rh72dTGbqQnsqmNm+/4r5x+L/eLtkdOqhEO
h6uSxsbG+LdT/ZVehaEE05yCxrncHNqe5yytG1pZXX3oGv/VSeefLnneK7LV
dUXcwZlflvp25XU09UzKeSk5wUFq0i0sLNy+fZtS4/V6+be3tramV2EowTSn
oHFqvePvHHN9e3tgZjHWMTj92/Oez864PiqxX2oc6g3P/e1q//Z8z7UXI3Je
CqlRrLa2llKTck6n4eHh9CoMJRgAgEwZDX1LsbWPtnpG5n5R0rHzWO+ZuqG5
pfhfK7r+dKnzrn10V25ro2/yRuvoziP2bbmOLyu6jz7sL3r5r/CH/nPPgikv
yJ8T2ZREP79OOwyDmwETyfmOJqmU40DY07kb2S/c09m9/L2L3F/hT3MXk7jH
8/8ct1fTPHOihPQqDCWY5uQ3Tmxl7ejC0OTCHy95dh3vz7k/ODm3nFPd9/k5
943WkV8Ud9BPqsh+UeLaXtD52/Od+Q/6jj6ivPRRagoe9JXWBtJfU05wkJqM
pFdhKME0J79x4qurlJvI7PLBu707i3u/utY3OD5/pXl4T6nrXH3gL+UUk/7G
7snfXfDuKOr++JQ7515f8aMBLjUnnw6mvyZSo7n0KgwlGACATPKHvkZf5Eh1
L018X5R5t+e07cxt/+6W3x2ceSu//XRtsDc8tzPHVmULH77X+x/F7TnV/b87
7/n8rOs3L/99dsb5f9e7U15TcQnGHiY2LbJ7+VKmRe6R3A7MxMtpkb8wibRp
Mf0TOkM8f/78kKTPP/+cqjDue2EowTQns3E6BqePPuzPu9/31eXuN/Latxxq
+++rvvb+6GdnXIfu9vWMzH580nW6duj4k8FfnujYd6v3L2Vde8/wU+P6n6td
6S+rbGPS4qmhzUVaEonU/PGPf6TU3Lhxgz0eJZjmZDZO39h8aV0gt7r3/677
3i2ybzls+/2FzjrvxL6qnr+Ue52B6X/d6Pn6pv9S49Cnpc5/XO7657WevWfc
n5/791zzt0pv+ssiNQpQavLy8iRS89VXX1Fq6DHs8SjBAABkkj/01XROfHWl
6++VnV9WdJ1+GvhreeeeUufZuuC2Q62OwPT80srP8mwnagK/PuX4e6V3KLLQ
FZr1DM38+19olsq0lNfU51MwRv2eSfYYM+ycpHetVBKVYHv27HE6nezxKME0
J7NxWvumvrnp+2uFhzYdjz8e/N9r3ZSakieDbxe0VzvGYvEV2nQ8eKf3jxfc
f7jgdgdn+sJz/NS4h2Z6RmfTX1aH/fnMZkoNraB0atjGZFVVFXs8SjDNyWwc
38hs7v2+L8o8X5Z78+73H7jt31PqyKnu+7TUVfx4ML6yeuhu71/KvJSmz0od
TzsnQpOLlB3+XEOvkP6ySI0Co6Oj586dk0jNv/71L0rNqVOn2ONRggEAyCR/
6IvOx/zhOdog9I/OzS3Gzz8L/qzA/mFxx57TrumFGD3gVyccfynzbM+xFf3Q
H5N3iirFJVji1ePzv+YdY59yfD63D5NNbey5YsfnC97LPTex3omwdLawsDA7
OxuPp14IoKKiguqv1tZW7haUYJqT2ThzS/H+8fmeUQrO3Oxi/E776M+LHe8f
tf+yxOkbWdsj8dXlrt+ec72eZ/vmRs/EjNwLhCnbmEwgNcnz2FBq6GfK7TgQ
UQcyG2dxeSUYWaAyilIzNRdr7I58esb9ZoH9o+OOGs8EPeBkzeDHJzo+ONbx
p4udPSPrf+mYQWoUi8VilJr08x/6fL7PP/+8uLh4ZeXHS4KiBAMAkEnx0FfT
OfF6gXNHQeeJJ4Hl+FrB9T9Xut8q7NiWv/YNl1g86yVYIu08VImXZ5fqe/Wk
VdyZptgJpugW/jEemZ6lSvCEIfoTuy5Yev2VQAmWBcoax9Y/9dFJz65jvfvv
9EZm105+WPhD/zuFHdsLvSdrAjMLci+rp3hjMmHt1IhdFwyn49CHssbpDc99
UeHbXTLwZUV3b3jt5IfXXwy/d7Rje77nmyr/yFRqXSAGqVFM8Lpg6fVXAiUY
AIBsioc+99Dsm/n27TltTT2T7CMv2pjcccSx5VBbQ3dE/wu1WI3gdcGePn2a
Xn8lUIJlgbLG6R+b31Pq2Z7nqrKNLsbWtlsqmobeLHJuT+64WFxeWfcVQKX0
64LhpPS6UdY4Y9NL/7zWs7Ow6/iTH3dTPO2c+PCEe0dR99GHA9PzMa0XE1Kl
XxeM5p30+iuBEgwAQDbFQ9/w5OL7xxwfn3TS/Mhuudw8/HpR5zuF7d7Q7Coq
sCwTvC6Yx+MRfENRgmlOWeNMzcV+f8H7bqHdFZxmtzx2j//8hHfXkfbazgns
uNBB+nXB6Jb0S+klUIJlgbLGmV+KH7zbt/uI7YHzxwtw2Pujey/4tuZ2VDwP
Lcs74gLUELwuWFVVVUr9lUAJBgAgm+Khbym2cu5Z6FbbKPe1r1rP+M+Kuz8t
dXNFGWQPuy5Y+oGIglCCaU5Z46ysrt5oC1c2DUdf7rqnjcmPzvT8/LjLE5zR
dAFBALsuWHl5ecqBiIJQgmlOceM89UbO1Q8NvrwEs39k9ovL/T8rdD16WZRB
VtXW1lZWVsqZRFCCAQDIpGbom5pbnl+Kcx94OQand+W7/lbRNbck9ystoBJN
dsFg6tXW0qEE05zixpleiM0u/js1veG5j055Py31BCYWNFs4kFRVVWW329d9
GD0GJZi2FDfO/HJ8ej7GfUw8Gl362xX/+8ecL/xT2i0dSKEsNDQ0rPswn8+H
EgwAQA4Nh75gZPG9IvvRhwPsSy6QVdFotKamhia7mzdvPlpPeXm5nG3OFJgW
JWjVOJHZ5d+cdX9zowefHetgaWmpvr6+srLy6tWr66aGHlNXV5fpn0BqJGjV
OLOL8X1V/j+c93QPC5x8HjRHbxzFgYKzbmquJyl4/WwsNgCAmWk49C3HV+u8
kb7w/Aq+0pJ909PTzc3NTfJQ/bWwkPGHLJgWJWjVOPGV1eaeyc6hmSXsuMi+
eDze2toqMzX0yGg0mumfQGokaNU4q6sJV2DG1jdFtZgmLwjS6I2TmZqWlhY5
x8anv342FhsAwMww9IEY9A0JaBwQhI4hAY0DgtAxAMCCMPSBGPQNCWgcEISO
IQGNA4LQMQDAgjD0gRj0DQloHBCEjiEBjQOC0DEAwIIw9IEY9A0JaBwQhI4h
AY0DgtAxAMCCMPSBGPQNCWgcEISOIQGNA4LQMQDAgjD0gRj0DQloHBCEjiEB
jQOC0DEAwIIw9IEY9A0JaBwQhI4hAY0DgtAxAMCCMPSBGPQNCWgcEISOIQGN
A4LQMQDAgjoAxBndPc3L6HcGzMvovmleRr8zYF5G900AAL0ZPe6CqRndPc3L
6HcGzMvovmleRr8zYF5G900AAAAAAAAAAAAAAAAAAABQq6OjYxJACA4OkYDg
gCCkRgJSA4KQGgCwIMyJfGgNPkyLEtBV+NAaHKRGAvoJH1qDg9QAgAVhFuBD
a/BhWpSArsKH1uAgNRLQT/jQGhykBgAsCLMAH1qDD9OiBHQVPrQGB6mRgH7C
h9bgIDUAYEEmmQXGx8dfvHjR3NwcCoX4t3u93rq6ut7eXn0Ww8DWGBgYaGho
oAUYGxszahlSYFqUYIbgRCIRj8dTX18/ODjIv72/v59SQ3fptiRGtQYNF81J
o6OjhixAOqRGgklSQxPKkydPUqaVkZGRZ8+e2Ww23ZbEqNagKYZWk8aNoaEh
QxYgHVIDABZkhjmRPH/+PC8v77vvvrtz5w5XhblcrpKSkpycnPLyctqq1GEx
jGqNnp6eM2fOHDx48MCBAw8fPjRJFYZpUYIZgkNF1rFjx6jPUEC4Kszv91+8
ePHw4cMnTpzwer36LIkhrREIBK5cuUKrv3///uvXrw8PD+u/DOmQGglmSA11
m1OnTh06dIgmFxp42Y3BYJC6EPUlmm7sdrs+S2JIa4yOjt6/f5+m2u+///7s
2bPUGvovQzqkBgAsyAxzImlqasrPz6cahFVh4XCY6q/jx4/TxhXdWFZWtolL
MNpOpvqLJsR9+/bRT1aFUQvovyQpMC1KMENwqAQrLi6mjUlKDVVhQ0NDfX19
58+fp9RQL6ISrKurS58l0b81aECorKxkqaHVp1W+du2aGfbqIzUSzJAaKjpO
nz7N5hrKiN/vHxkZuXr16vdJm7sEozW9e/fuvpdYFZbyGbohkBoAsCAzzIlM
fX19Xl7ewSQqSQoLC9meugsXLtAsqc8y6N8abrebNgNog5nWNDc3l9adNibp
d5ooDd+rj2lRgkmCQ4tx7Ngx1m2oI508efK7JPrd6XTquRi6/S3S29t76dIl
lhraZj58+DDbfuZ/GmgUpEaCGVITiUR6enqoCmOfnxYVFZ07d44V8vn5+S0t
Lbotic6tMTQ0dPPmTVplWlMaMY4cOcJmWFaH6rkk6ZAaALAgM8yJnGfPntEk
SHMEt4/u4sWLun0RbFL3OdHj8dA2M60mrfLZs2c7Oztrampok5JtW967d29k
ZETP5UmBaVGCeYLDqjDqM99++y3bkiwpKdHzi2CT+ganr6+vrKyM7ak4evRo
e3t7W1sb+wydbqmsrDT2szCkRoJ5UkNFx6lTp7jUECpJqCPpuQx6tsbw8DDV
XxQQGh8OHz7c0NDg9XrZuEE3UlNQrHRbmHRIDQBYkHnmRKa5uZk2qw4dOkTz
wuXLlwcGBvT86zq3Rm1tLfvk69y5c+xbCZFIpK6u7kjShQsXfD6fnsuTAtOi
BFMFx+1200YU+zCotLRUt+MPOXq2ht1uz8vLo5U9fvy4w+GYTKbGZrMVFRVR
mqj81O1AMkFIjQRTpYaKDhpj2VxDxYj+y6bzjgtaR0oNZef58+eTydTQ/HLy
5Elqgfz8fHajUZAaALAgU82JDG1BlZWV3b17V/9vCuvcGsFgsKqq6urVq/zj
QGhmrK+vp22D1tZW+l3P5UmBaVGC2YLT3d19+fLla9eucWcY0JOerTEyMvL4
8eNLly65XC7uRkoKjRvnz5+vqamZmJjQbWHSITUSzJYaGoFv3LhRXl7udrv1
/+t6tsbY2Fhzc/OZM2f4R1qyKoyidOfOnfHxcd0WJh1SAwAWZLY5kYkk6f93
9W8NWs30LcbISzovTApMixJMGBwD+4zOrSG4pkiN+ZkzNUbV7Pq3huCaGtgC
HKQGACzIhHOigdAaHJqUMS1KQFfhQ2swSI009BM+tAaD1ACANfn9fsPPIQYm
NDAwgGlRAoID6ZAaaUgNpENqAMCaotGow+HAtAh8ExMT1CswLUpAcCAFUrMu
pAZSIDUAYGU0Lfr9/g6Al5xOJ/UKozum2SE4wIfUyIHUAB9SAwAb0f8HeGUM
lw==
"], {{0, 363.7045369328834}, {864.6419197600301, 0}}, {0, 255},
ColorFunction->RGBColor,
ImageResolution->{96.012, 96.012},
SmoothingQuality->"High"],
BoxForm`ImageTag["Byte", ColorSpace -> "RGB", Interleaving -> True],
Selectable->False],
DefaultBaseStyle->"ImageGraphics",
ImageSize->Automatic,
ImageSizeRaw->{864.6419197600301, 363.7045369328834},
PlotRange->{{0, 864.6419197600301}, {0, 363.7045369328834}}]\)](https://www.wolframcloud.com/obj/resourcesystem/images/d2a/d2a66024-522f-464b-bdaf-f0054d95e3fc/3a6645aa4dcbae54.png)