Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
Classify an image:
The prediction is an Entity object, which can be queried:
Get the list of available properties for the predicted Entity:
Obtain the probabilities of the 10 most likely entities predicted by the net. Note that the top 10 predictions are not mutually exclusive:
Obtain the list of names of all available classes:
Net architecture
The main idea behind this vision transformer is to divide the input image into a grid of 7x7 patches, represent each part as a feature vector and perform self-attention on such set of 49 feature vectors, or "tokens." One additional feature vector is used as the "classification token," which will contain the class information at the end of the processing.
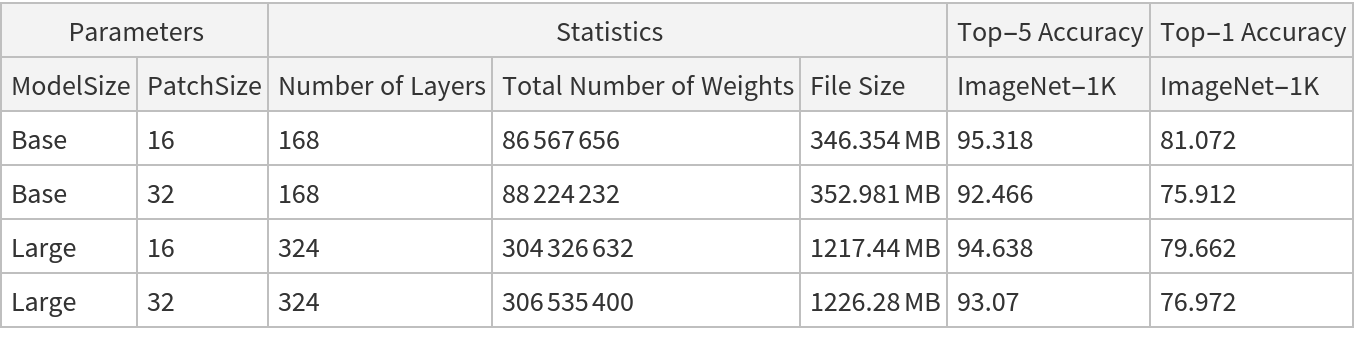
After extracting the pixel values and taking a center crop of the image, the first module of the net computes the initial values for the set of 50 "tokens":
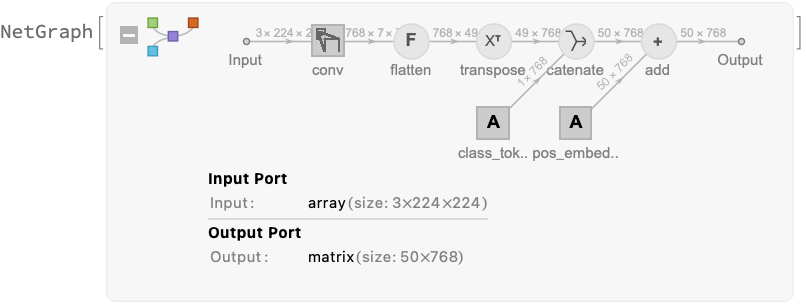
The patches are computed using the only ConvolutionLayer in the net. It takes the center crop and produces 7x7 patches with feature size 768. Each of the 49 patches represents a 32x32 area on the original image:
The patches are then reshaped and transposed to an array of shape 49x768, so that each patch is encoded into a feature vector of size 768. Then the "classification token" is prepended (bringing the vector count to 50), after which the positional embeddings are added to each vector:
Positional embeddings are added to the input image patches to add some notion of spatial awareness to the downstream attention processing. Just like most sequence-based transformers for NLP, the values of the embeddings for fixed feature dimensions often exhibit an oscillating structure, except this time they vary along two dimensions. Inspect a few positional embeddings for different features:
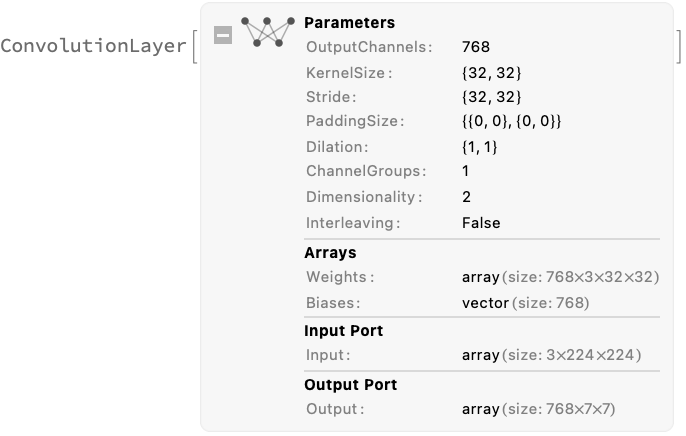
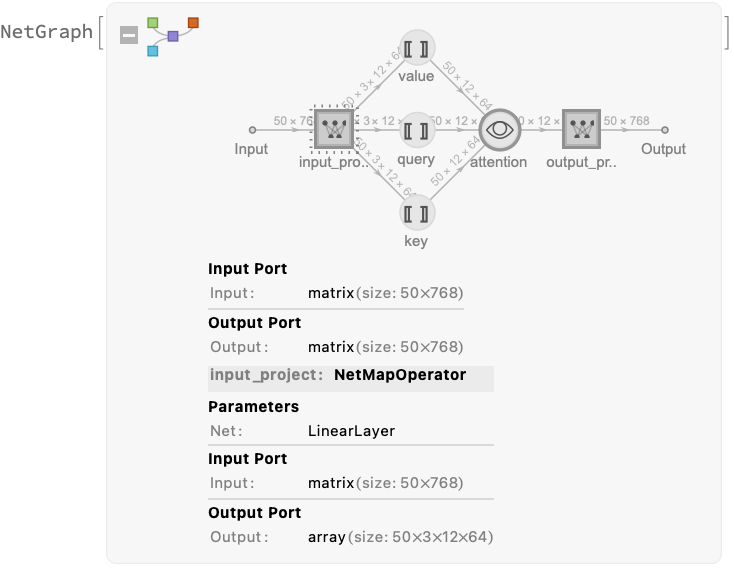
After adding the positional embeddings, the sequence of 50 vectors is fed to a stack of 12 structurally identical self-attention blocks, consisting of a self-attention part and a simple MLP part:
The self-attention part is a standard multi-head attention setup. The feature size 768 is divided into 12 heads each with size 64:
After the self-attention stack, the set of vectors is normalized one last time and the "classification token" is extracted and used to classify the image:
Attention visualization
Define a test image and classify it:
Extract the attention weights used for the last block of self-attention when classifying this image:
Extract the attention weights between the "classification token" and the input patches. These weights can be interpreted as which patches in the original image the net is "looked at" in order to perform the classification:
Reshape the weights as a 3D array of 12 7x7 matrices. Each matrix corresponds to a head, while each element of the matrices corresponds to a patch in the original image:
Visualize the attention weight matrices. Patches with higher values (red color) are what is mostly being "looked at" for each attention head:
Define a function to visualize the attention matrix on an image:
Visualize the mean attention across all the attention heads:
Visualize each attention head separately:
Positional embedding visualization
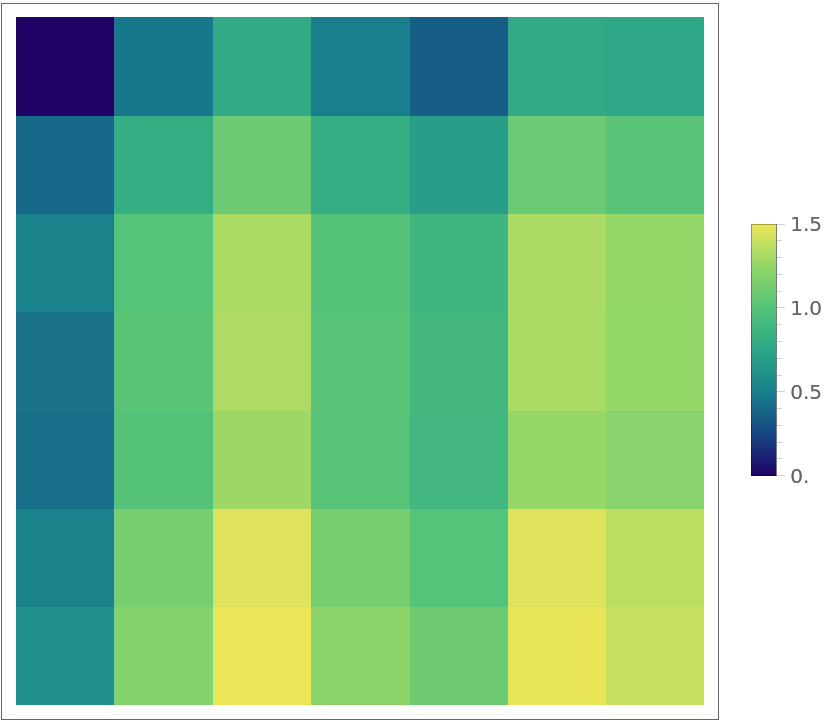
Positional embeddings for spatially distant patches tend to be apart in the feature space as well. In order to show this, calculate the distance matrix between the embeddings of the input patches:
Visualize the distance between all patches and the first (top-left) patch:
Repeat the experiment for all the patches. Note that patches in the same row or column are closer to each other:
Feature extraction
Remove the last two layers of the trained net so that the net produces a vector representation of an image:
Get a set of images:
Visualize the features of a set of images:
Transfer learning
Use the pre-trained model to build a classifier for telling apart indoor and outdoor photos. Create a test set and a training set:
Remove the last linear layer from the pre-trained net:
Create a new net composed of the pre-trained net followed by a linear layer and a softmax layer:
Train on the dataset, freezing all the weights except for those in the "linearNew" layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
Check some metadata of the ONNX model:
Import the model back into Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/03883d7c-b673-4872-9af0-2da1c2348e55"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/6e1b702994033270.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/6951615e-33de-415d-852b-c152b8d1dcb8"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/2dcac953dfef4985.png)


![positionEmbeddings = Normal@NetExtract[
NetModel[
"Vision Transformer Trained on ImageNet Competition Data"], {"patch_embeddings", "pos_embedding", "Array"}];](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/3318fd2a0aaff456.png)
![GraphicsRow[
ListPlot3D[#, ColorFunction -> "BalancedHue"] & /@ ArrayReshape[
Transpose[Rest[positionEmbeddings][[All, featureIds]]],
{Length[featureIds], 7, 7}
],
ImageSize -> Full
]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/438e9f3e0d7a68a2.png)


![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/b2f099b0-9fb4-424b-9ae7-3e6f5c9ff02c"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/561c1b0f2980022b.png)
![attentionMatrix = Transpose@
NetModel[
"Vision Transformer Trained on ImageNet Competition Data"][
testImage, NetPort[{"encoder", -1, "attention", "attention", "AttentionWeights"}]];](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/2dca9b7d386426fb.png)

![visualizeAttention[img_Image, attentionMatrix_] := Block[{heatmap, wh},
wh = ImageDimensions[img];
heatmap = ImageApply[{#, 1 - #, 1 - #} &, ImageAdjust@Image[attentionMatrix]];
heatmap = ImageResize[heatmap, wh*256/Min[wh]];
ImageCrop[ImageCompose[img, {ColorConvert[heatmap, "RGB"], 0.4}], ImageDimensions[heatmap]]
]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/3e53f487b177ed10.png)


![positionEmbeddings = Normal@NetExtract[
NetModel[
"Vision Transformer Trained on ImageNet Competition Data"], {"patch_embeddings", "pos_embedding", "Array"}];](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/3610676a44ea64c0.png)
![Labeled[
GraphicsGrid@
Table[ArrayPlot[reshapedDistanceMatrix[[r, c]], ColorFunction -> "BlueGreenYellow"], {r, 1, 7}, {c, 1, 7}],
{"Input patch column", "Input patch row"},
{Left, Bottom},
RotateLabel -> True
]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/075732ea4257b85e.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/74ad4d2b-924e-470d-90f0-77370b703ab8"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/2dcdb542e2784c64.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/25bffe82-c46f-4cf9-9661-ca65c0d2b011"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/48b14f2f74b84e5d.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/65f9bf7d-aed2-4955-b566-7b47295833d8"]](https://www.wolframcloud.com/obj/resourcesystem/images/cbd/cbd7eff9-d924-4404-a691-261ab6024823/7cca786e1997bd8f.png)


