Resource retrieval
Get the pre-trained net:
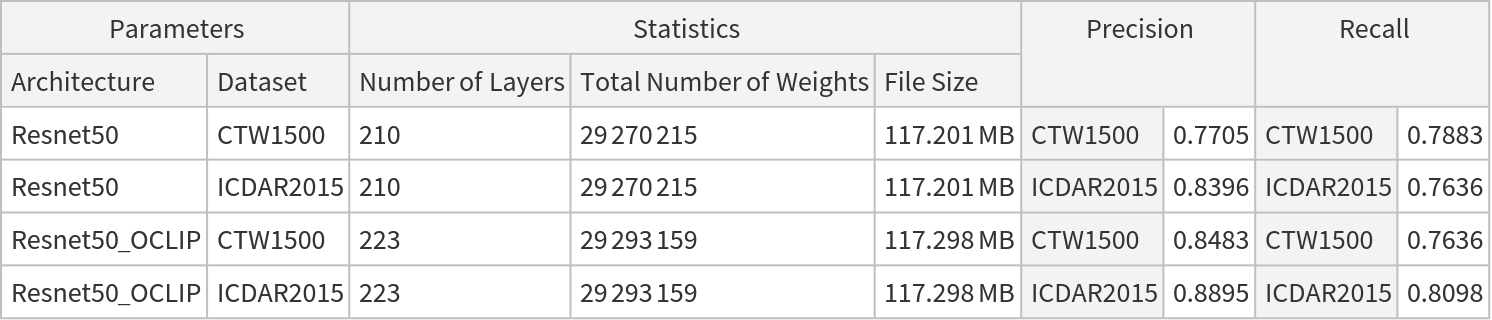
NetModel parameters
This model consists of a family of individual nets, each identified by a specific architecture. Inspect the available parameters:
Pick a non-default net by specifying the architecture:
Pick a non-default uninitialized net:
Evaluation function
Write an evaluation function to scale the result to the input image size and suppress the least probable detections:
Basic usage
Obtain the detected bounding boxes and masks with their corresponding classes and confidences for a given image:
The model returns "BoundingRegion" and "Scores":
The "BoundingRegion" is a list of Polygon expressions corresponding to the bounding regions of the detected objects:
"Scores" contains the confidence scores of the detected objects:
Visualize the bounding region for each text instance:
Get the individual masks via the option "Output"->"Masks":
Visualize the masks for each text instance with its assigned score:
Network result
Get a sample image:
The network computes seven prototyped segmentation masks for all the text instances at different scales:
Visualize the prototyped segmentation masks:
Rescale the probability map of the first segmentation mask to the original image size:
Visualize the probability map of having text:
Threshold the results to get the masks:
The first segmentation mask is used as the text mask because it has the largest scale that allows the selection of text regions. Intercept the masks with the predicted text regions:
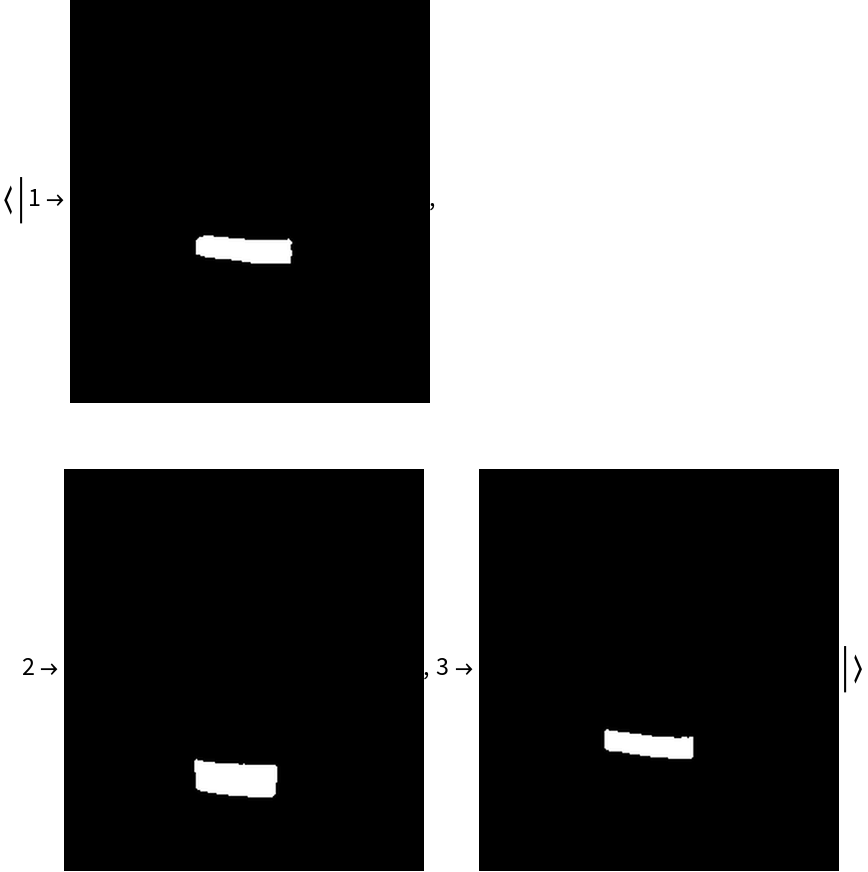
The MorphologicalComponents function can create masks for each text instance, using the final segmentation mask. This mask, which has the smallest scale, clearly separates different text instances by keeping their boundaries apart:
Use the SelectComponents function to split the components into different images:
The progressive scale expansion algorithm starts from the pixels of multiple kernels and iteratively merges the adjacent text pixels avoiding the conflict of shared pixels and preserving the distinction between instances. Define a function that removes the shared pixels between kernels:
Apply the progressive scale expansion algorithm starting from the mask with the smallest scale and adding pixels progressively using the other masks:
Rescale the final list of masks to the original image size and visualize:
It is possible to choose a bounding region type. Find the contour points of each region and select a bounding region type to enclose each piece of text:
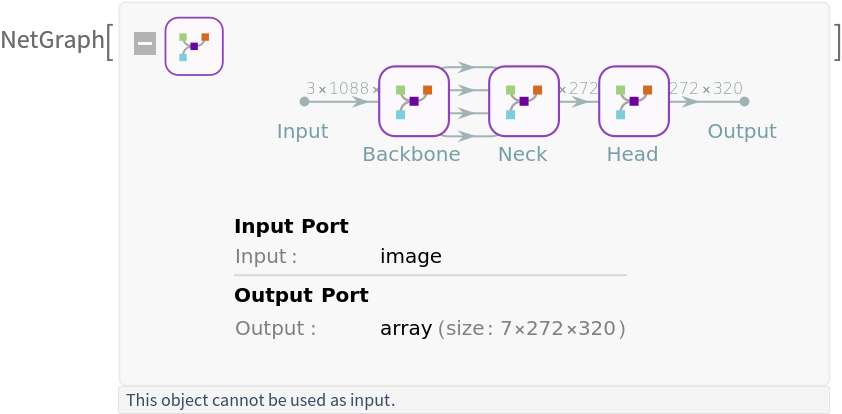
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
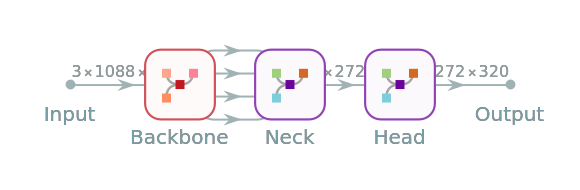
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
The size is similar to the byte count of the resource object :
Check some metadata of the ONNX model:
Import the model back into Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:
![NetModel["PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data", "ParametersInformation"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/65e04082014f0dce.png)

![NetModel[{"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data", "Dataset" -> "ICDAR2015"}]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/510d808265e8976c.png)

![NetModel[{"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data", "Dataset" -> "ICDAR2015"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/33ca6083338d1669.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/25cb88da-9189-4f4c-b6bf-c5119995f37c"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/7644e798f9f87cd5.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/680db4d5-3580-4712-b37a-7e17a6dd8695"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/1a50c75e983b268c.png)



![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/b462488a-4e49-487a-b5bb-3fd1be5a171e"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/781eef2ee49edf9f.png)

![scaleResult[img_Image, orImg_Image] := Module[{inputImageDims, w, h, ratio, tRatio},
(*scale the results to match the shape of the original image*)
inputImageDims = ImageDimensions[orImg];
{w, h} = ImageDimensions[img];
ratio = ImageAspectRatio[orImg];
tRatio = ImageAspectRatio[img];
If[
tRatio/ratio > 1,
ImageResize[ImageCrop[img, {w, w*ratio}], inputImageDims],
ImageResize[ImageCrop[img, {h /ratio, h}], inputImageDims]
]
];](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/788ade5a182631c2.png)
![ImageCompose[
Colorize[probmap, ColorFunction -> ColorData["TemperatureMap"], ColorRules -> {0 -> White}], {testImage, 0.6}]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/729411fb38c592d9.png)


![labels = Table[
Image@SelectComponents[labels, SameQ[#Label, i] &],
{i , Range[Max[labels]]}
]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/53083502850ed01a.png)

![removeIntersect[labels_, labelsPast_] := Module[{labelsNew, nLabels},
nLabels = Length[labels];
labelsNew = Table[ImageSubtract[labels[[i]], ImageMultiply[labelsPast[[i]], ImageAdd[labels[[Complement[Range[nLabels], {i}]]]]]], {i, nLabels}]; Table[
ImageMultiply[labelsNew[[i]], Sequence @@ ColorNegate@labelsNew[[Complement[Range[nLabels], {i}]]]], {i, nLabels}]
];](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/7c430fbec740be20.png)
![labels = Fold[removeIntersect[
Map[Function[x, GeodesicDilation[x, #2]], #1], #1] &, labels, Reverse[kernelMasks]];
GraphicsRow[labels]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/43ead7c6e8576d0c.png)


![contours = Map[Values[
ComponentMeasurements[#, "PerimeterPositions", CornerNeighbors -> True]][[1]] &, masks];
regionTypes = {"MinRectangle", "MinOrientedRectangle", "MinConvexPolygon" };
regions = Table[BoundingRegion[contour[[1]], regType] , {regType, regionTypes}, {contour, contours}];](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/10044983959a59f6.png)
![MapThread[
Labeled[
HighlightImage[testImage, Thread[Range[Length[#1]] -> #1], ImageLabels -> None], #2, Top] &,
{regions, regionTypes}
]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/69b68991cee01b39.png)

![Information[
NetModel[
"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/70ec0b675efe1c92.png)

![Information[
NetModel[
"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/77ab93c0bf803c4a.png)
![Information[
NetModel[
"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/33acee56480eda91.png)
![Information[
NetModel[
"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/15c0f486b502975a.png)
![onnxFile = Export[FileNameJoin[{$TemporaryDirectory, "net.onnx"}], NetModel[
"PSENet Text Detector Trained on ICDAR-2015 and CTW1500 Data"]]](https://www.wolframcloud.com/obj/resourcesystem/images/c25/c256b63b-2904-43cf-aa42-b668d74dfd12/1c18a6c4f75e6e42.png)
