RetinaNet-101 Feature Pyramid Net
Trained on
MS-COCO Data
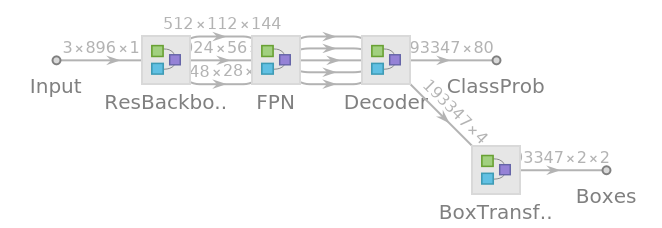
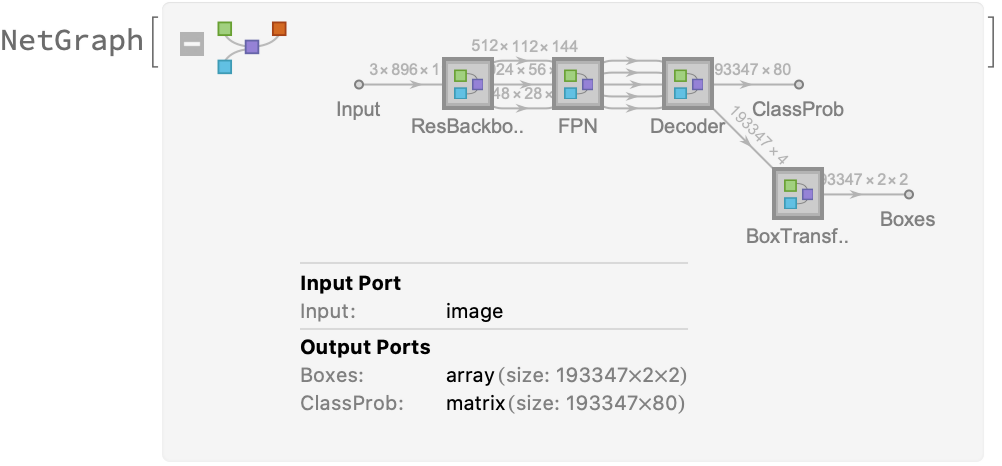
RetinaNet is a single-stage object detection model that goes straight from image pixels to bounding box coordinates and class probabilities. It is able to exceed the accuracy of the best two-stage detectors while offering comparable speed performance to that of the single-stage detectors. The model architecture is based on a Feature Pyramid Network on top of a feedforward ResNet-101 backbone. The model has been trained using a new loss function, "Focal Loss," which addresses the imbalance between foreground and background classes that arises within single-stage detectors.
Trained size: 337 MB |
Examples
Resource retrieval
Get the pre-trained net:
Label list
Define the label list for this model. Integers in the model's output correspond to elements in the label list:
Evaluation function
Write an evaluation function to scale the result to the input image size and suppress the least probable detections:
Basic usage
Obtain the detected bounding boxes with their corresponding classes and confidences for a given image:
Inspect which classes are detected:
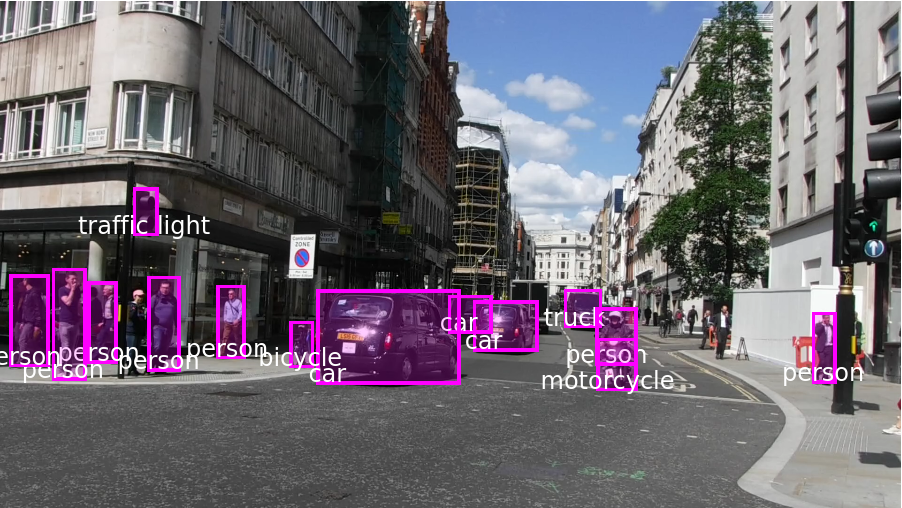
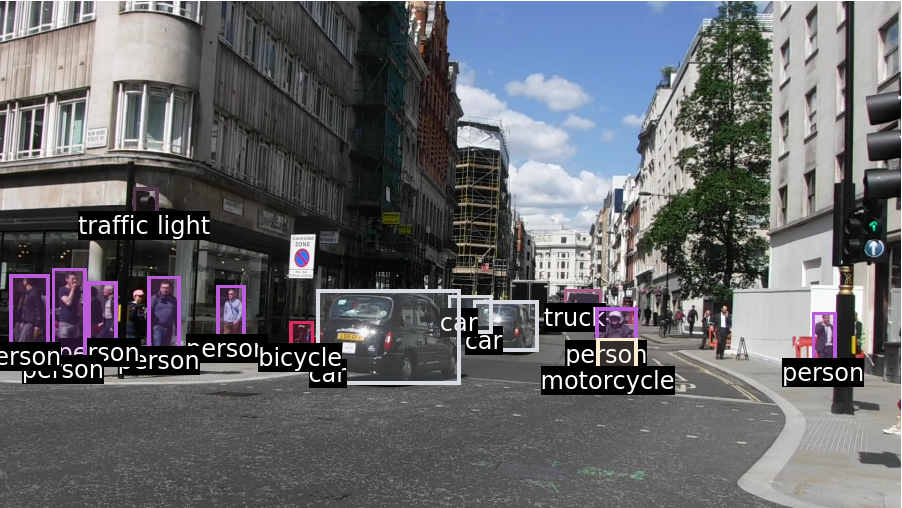
Visualize the detection:
Advanced visualization
Write a function to apply a custom styling to the result of the detection:
Net information
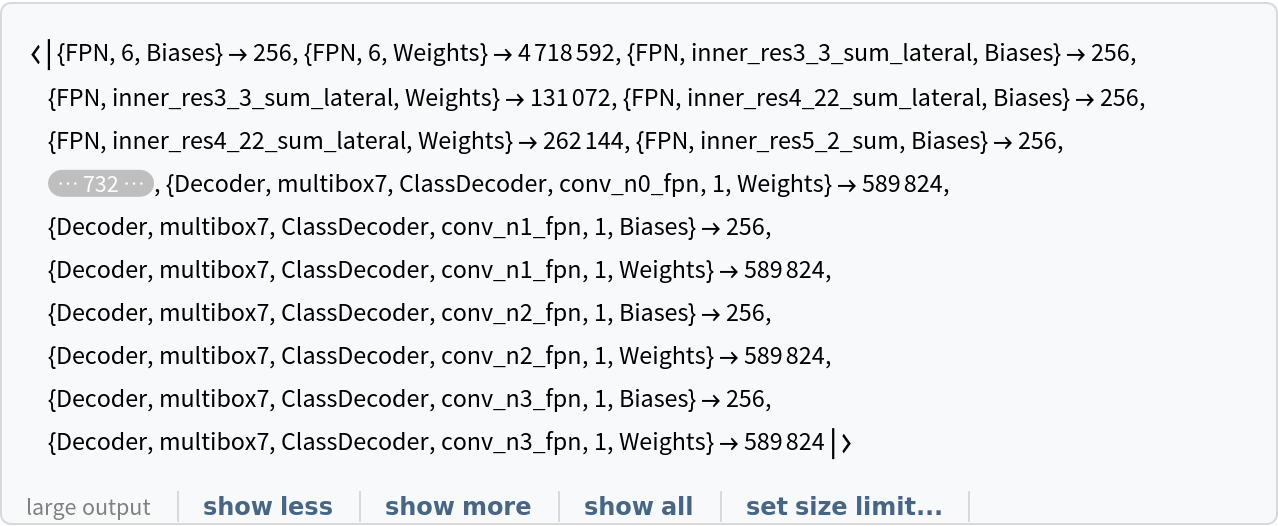
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
Requirements
Wolfram Language
12.1
(March 2020)
or above
Resource History
Reference
![nonMaxSuppression[overlapThreshold_][detection_] := Module[{boxes, confidence}, Fold[{list, new} |-> If[NoneTrue[list[[All, 1]], IoU[#, new[[1]]] > overlapThreshold &], Append[list, new], list], Sequence @@ TakeDrop[Reverse@SortBy[detection, Last], 1]]]
ClearAll[IoU]
IoU := IoU = With[{c = Compile[{{box1, _Real, 2}, {box2, _Real, 2}}, Module[{area1, area2, x1, y1, x2, y2, w, h, int}, area1 = (box1[[2, 1]] - box1[[1, 1]]) (box1[[2, 2]] - box1[[1, 2]]);
area2 = (box2[[2, 1]] - box2[[1, 1]]) (box2[[2, 2]] - box2[[1, 2]]);
x1 = Max[box1[[1, 1]], box2[[1, 1]]];
y1 = Max[box1[[1, 2]], box2[[1, 2]]];
x2 = Min[box1[[2, 1]], box2[[2, 1]]];
y2 = Min[box1[[2, 2]], box2[[2, 2]]];
w = Max[0., x2 - x1];
h = Max[0., y2 - y1];
int = w*h;
int/(area1 + area2 - int)], RuntimeAttributes -> {Listable}, Parallelization -> True, RuntimeOptions -> "Speed"]}, c @@ Replace[{##}, Rectangle -> List, Infinity, Heads -> True] &]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/0325bd2b68e56dab.png)
![netevaluate[ img_Image, detectionThreshold_ : .6, overlapThreshold_ : .45 ] := Module[{netOutputDecoder, net, imageConformer, deconformRectangles, detectionsDeconformer},
imageConformer[dims_, fitting_][image_] := First@ConformImages[{image}, dims, fitting, Padding -> 0.5];
deconformRectangles[{}, _, _, _] := {};
deconformRectangles[rboxes_List, image_Image, netDims_List, "Fit"] := With[{netAspectRatio = netDims[[2]]/netDims[[1]]}, With[{boxes = Map[{#[[1]], #[[2]]} &, rboxes], padding = If[ImageAspectRatio[image] < netAspectRatio, {0, (ImageDimensions[image][[1]]*
netAspectRatio - ImageDimensions[image][[2]])/
2}, {(ImageDimensions[image][[2]]*(1/netAspectRatio) - ImageDimensions[image][[1]])/2, 0}], scale = If[ImageAspectRatio[image] < netAspectRatio, ImageDimensions[image][[1]]/netDims[[1]], ImageDimensions[image][[2]]/netDims[[2]]]}, Map[Rectangle[Round[#[[1]]], Round[#[[2]]]] &, Transpose[
Transpose[boxes, {2, 3, 1}]*scale - padding, {3, 1, 2}]]]]; detectionsDeconformer[ image_Image, netDims_List, fitting_String ][ objects_ ] := Transpose[ { deconformRectangles[ objects[[All, 1]], image, netDims, fitting ], objects[[All, 2]] } ];
netOutputDecoder[threshold_ : .5][netOutput_] := Module[{detections = Position[netOutput["ClassProb"], x_ /; x > threshold]}, Transpose[{Rectangle @@@ Extract[netOutput["Boxes"], detections[[All, 1 ;; 1]]], Extract[labels, detections[[All, 2 ;; 2]]], Extract[netOutput["ClassProb"], detections]}]];
net = NetModel[
"RetinaNet-101 Feature Pyramid Net Trained on MS-COCO Data"]; (Flatten[
nonMaxSuppression[ overlapThreshold ] /@ GatherBy[#, #[[2]] &], 1] &)@detectionsDeconformer[img, {1152, 896}, "Fit" ]@
netOutputDecoder[ detectionThreshold ]@
net@imageConformer[{1152, 896}, "Fit"]@img
]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/1a94af569e2d58e4.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/841876e5-9610-47c2-bf85-f3d2e52332fc"]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/3dc946fb05fec1bc.png)

![HighlightImage[testImage, {#[[1]], Text[Style[#[[2]], White, 12], {20, 20} + #[[1, 1]], Background -> Transparent]} & /@ detection]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/19378eb24eb2d9fa.png)
![styleDetection[
detection_] := {RandomColor[], {#[[1]], Text[Style[#[[2]], White, 12], {20, 20} + #[[1, 1]], Background -> Black]} & /@ #} & /@ GatherBy[detection, #[[2]] &]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/2f7ae62bd888c401.png)
![Information[
NetModel[NetModel[
"RetinaNet-101 Feature Pyramid Net Trained on MS-COCO Data"] ], \
"ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/a6f/a6fd35ef-f93f-469a-a299-654b68cc6c37/057edf2865ccabcb.png)