Resource retrieval
Get the pre-trained net:
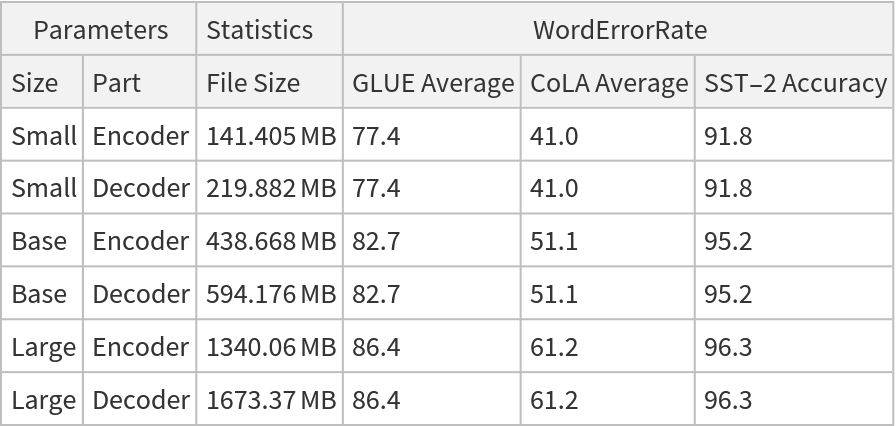
NetModel parameters
This model consists of a family of individual nets, each identified by a specific architecture. Inspect the available parameters:
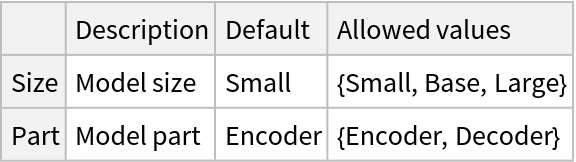
Pick a non-default net by specifying the parameters:
NetModel tokenizers
Pick the original tokenizer used to train the nets, which yields the most accurate, model-consistent token IDs. It finds a globally optimal segmentation:
Pick a faster tokenizer, which finds the longest matching token at each step. It can produce segmentations that differ from the "UnigramTokenizer":
Evaluation function
Write a function that preprocesses a list of input sentences:
Write an evaluation function to combine the encoder and decoder nets into a full generation pipeline:
Basic usage
Define a text to summarize:
Evaluate a net:
Evaluate a net using the "Greedy" tokenizer:
Feature extraction
Get the sentences:
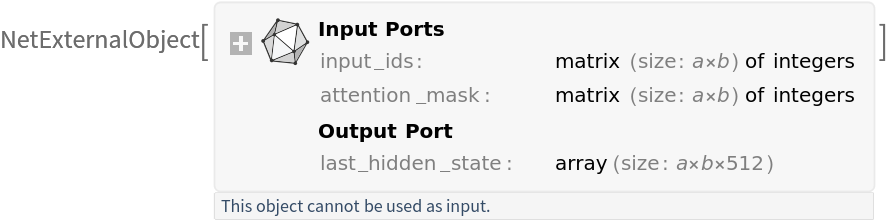
Encode the input sentences:
The function returns "input_ids", which are the numerical token representations of the text; "attention_mask", which marks real tokens versus padding; and "token_type_ids", which indicate segment identifiers but are unused for T5:
Get the features:
Visualize the normalized aggregated embeddings in a feature space:
Downstream tasks
T5 is a general-purpose language model designed to handle many NLP tasks using a single unified format. Unlike traditional task-specific architectures (e.g. separate models for sentiment analysis, question answering and translation), T5 treats every NLP task as a text-to-text problem. Define task templates for different downstream tasks:
Write an evaluation function that runs a net on an input prompt and task:
The Stanford Sentiment Treebank (SST-2) template can be used to classify the sentiment of a single sentence as either positive or negative:
The Question-Answering Natural Language Inference (QNLI) template can be used to determine whether a given sentence contains the answer to a specific question:
The Stanford Question Answering Dataset (SQuAD) template can be used to answer factual questions by extracting the most relevant span of text directly from a provided context paragraph:
The Cable News Network (CNN) template generates a short, human-like summary that captures the essential information from a longer news article:
The WMTe2g template generates a translation from English to German:
The WMTe2f template generates a translation from English to French:
The WMTe2r template generates a translation from English to Romanian:



![prepareBatch[inputStrings_?ListQ, tokenizer_] := Block[{tokens, attentionMask, tokenTypes},
tokens = tokenizer[inputStrings];
attentionMask = PadRight[ConstantArray[1, Length[#]] & /@ tokens, Automatic];
tokens = PadRight[tokens, Automatic];
tokenTypes = ConstantArray[0, Dimensions[tokens]];
<|"input_ids" -> tokens, "attention_mask" -> attentionMask, "token_type_ids" -> tokenTypes|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/20cdcee99e4380c1.png)
![Options[netevaluate] = {"Size" -> "Small", MaxIterations -> 200, "Tokenizer" -> "Unigram"};
netevaluate[input_String, OptionsPattern[]] := Module[{
encoder, decoder, tokenizer, encoderInput, initialValues, initialStates, decoderInput, encoderFeatures, logits,
n, id, ids = {}, decoderOutput, newKey, prob, tokens, tokenizerName
},
encoder = NetModel[{"Google-T5 Multitask Language Model", "Size" -> OptionValue["Size"], "Part" -> "Encoder"}];
decoder = NetModel[{"Google-T5 Multitask Language Model", "Size" -> OptionValue["Size"], "Part" -> "Decoder"}];
initialValues = NetModel[{"Google-T5 Multitask Language Model", "Size" -> OptionValue["Size"]}, "InitialValues"];
tokenizerName = Replace[OptionValue["Tokenizer"],
{
"Greedy" -> "GreedyTokenizer",
"Unigram" -> "UnigramTokenizer"
}
];
tokenizer = NetModel["Google-T5 Multitask Language Model", tokenizerName];
tokens = NetModel["Google-T5 Multitask Language Model", "Tokens"];
encoderInput = prepareBatch[{input}, tokenizer];
encoderFeatures = encoder@encoderInput;
initialStates = Association[];
Scan[
initialStates[#] = Transpose[
ArrayReshape[encoderFeatures . initialValues[#], {1, Dimensions[encoderFeatures][[2]], Dimensions[encoderFeatures][[3]]/64, 64}], 2 <-> 3
]; &,
Keys[initialValues]
];
decoderInput = Join[
Association[
"encoder_attention_mask" -> ConstantArray[1, Dimensions[encoderFeatures][[1 ;; -2]]],
"input_ids" -> {{0}},
"encoder_hidden_states" -> encoderFeatures
], Join[initialStates, Association[
Table[StringReplace[k, "encoder" -> "decoder"] -> {}, {k, Keys[initialStates]}]]]
];
n = 0; While[n < OptionValue[MaxIterations],
decoderOutput = decoder[decoderInput];
logits = Flatten@decoderOutput["logits"];
id = First@Ordering[logits, -1];
n++;
If[id == 2, Break[]];
AppendTo[ids, id];
decoderInput["input_ids"] = {{id - 1}};
decoderInput["encoder_attention_mask"] = ConstantArray[1, {1, 1}];
decoderInput["encoder_hidden_states"] = encoderFeatures;
Table[
newKey = StringReplace[k, "present" -> "past_key_values"];
decoderInput[newKey] = decoderOutput[k],
{k, DeleteCases[Keys[decoderOutput], "logits"]}
];
];
StringTrim[StringReplace[StringJoin[tokens[[ids]]], "▁" -> " "]]]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/5c345b4b557a1fa6.png)
![text = "summarize: For centuries Paris has been one of the world\[CloseCurlyQuote]s most important and attractive cities. It is appreciated for the opportunities it offers for business and commerce, for study, for culture, and for entertainment; its gastronomy, haute couture, painting, literature, and intellectual community especially enjoy an enviable reputation. Its sobriquet \[OpenCurlyDoubleQuote]the City of Light\[CloseCurlyDoubleQuote] (\[OpenCurlyDoubleQuote]la Ville Lumière\[CloseCurlyDoubleQuote]), earned during the Enlightenment, remains appropriate, for Paris has retained its importance as a centre for education and intellectual pursuits.";](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/447587cbeb825743.png)


![encodedInputs = prepareBatch[
sentences,
NetModel["Google-T5 Multitask Language Model", "UnigramTokenizer"]
];](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/20696debff0e206a.png)
![taskTemplates = <|
"QNLI" -> StringTemplate["qnli question: `` sentence: ``"],
"SST-2" -> StringTemplate["sst2 sentence: ``"],
"CNN" -> StringTemplate["summarize: ``"],
"SQuAD" -> StringTemplate["question: `` context: ``"],
"WMTe2g" -> StringTemplate["translate English to German: ``"],
"WMTe2f" -> StringTemplate["translate English to French: ``"],
"WMTe2r" -> StringTemplate["translate English to Romanian: ``"]
|>;](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/7d5f1e01b1fd29e7.png)
![Options[taskEvaluate] = {"Size" -> "Small", MaxIterations -> 200, "Tokenizer" -> "Greedy"};
taskEvaluate[task_String, sentences_List, OptionsPattern[]] := Module[
{prompt},
prompt = taskTemplates[task] @@ sentences;
netevaluate[prompt, "Size" -> OptionValue["Size"], MaxIterations -> OptionValue[MaxIterations], "Tokenizer" -> OptionValue["Tokenizer"]]
];](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/365e808f588a3d54.png)
![Dataset[<|"Input" -> #, "Predictions" -> taskEvaluate["SST-2", {#}, "Tokenizer" -> "Unigram"]|> & /@ {"tsai has a well-deserved reputation as one of the cinema world's great visual stylists , and in this film , every shot enhances the excellent performances .", "somewhere inside the mess that is world traveler , there is a mediocre movie trying to get out ."}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/4222bd50b6ced181.png)

![Dataset[<|"Input" -> #, "Predictions" -> taskEvaluate["QNLI", #, "Tokenizer" -> "Unigram"]|> & /@ { {"Where was Einstein born?", "Einstein was born in Ulm, Germany in 1879."}, {"Where was Einstein born?", "Einstein won the 1921 Nobel Prize in Physics."}}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/5058d5700022dd4a.png)

![taskEvaluate["SQuAD", {"What does increased oxygen concentrations in the patient\[CloseCurlyQuote]s lungs displace?", "Hyperbaric (high-pressure) medicine uses special oxygen chambers to increase the partial pressure of O 2 around the patient and, when needed, the medical staff. Carbon monoxide poisoning, gas gangrene, and decompression sickness (the \[CloseCurlyQuote]bends\[CloseCurlyQuote]) are sometimes treated using these devices. Increased O2 concentration in the lungs helps to displace carbon monoxide from the heme group of hemoglobin. Oxygen gas is poisonous to the anaerobic bacteria that cause gas gangrene, so increasing its partial pressure helps kill them. Decompression sickness occurs in divers who decompress too quickly after a dive, resulting in bubbles of inert gas, mostly nitrogen and helium, forming in their blood. Increasing the pressure of O 2 as soon as possible is part of the treatment."}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/5eb48a11f35fa419.png)
![taskEvaluate["CNN", {"Charles Aznavour (/ˌæznəˈvʊər/ AZ-nə-VOOR; French: [ʃaʁl aznavuʁ]; Armenian: Շահնուր Վաղինակ Ազնավուրյան; born Shahnur Vaghinak Aznavourian;[a] 22 May 1924 \[Dash] 1 October 2018) was a French singer and songwriter of Armenian descent. Aznavour was known for his distinctive vibrato tenor voice:[3] clear and ringing in its upper reaches, with gravelly and profound low notes. In a career as a singer and songwriter, spanning over 70 years, he recorded more than 1,200 songs, in various languages. Moreover, he wrote or co-wrote more than 1,000 songs for himself and others. Aznavour is regarded as one of the greatest songwriters in history and an icon of 20th-century pop culture.[4]
Aznavour sang for presidents, popes and royalty, as well as at humanitarian events. In response to the 1988 Armenian earthquake, he founded the charitable organization Aznavour for Armenia along with his long-time friend, impresario Lévon Sayan. In 2008, he was granted Armenian citizenship[5] and was appointed ambassador of Armenia to Switzerland the following year, as well as Armenia's permanent delegate to the United Nations at Geneva.[6]
One of France's most popular and enduring singers,[7][8] he was dubbed France's Frank Sinatra,[9][10] while music critic Stephen Holden described Aznavour as a \"French pop deity\".[11] Several media outlets described him as the most famous Armenian of all time.[7][12] Jean Cocteau, who cast him in his 1960 Le Testament d'Orphée, joked \"Before Aznavour despair was unpopular\".[13] Between 1974 and 2016, Aznavour received around sixty gold and platinum records around the world.[14] According to his record company, the total sales of Aznavour's recordings were over 180 million units.[15][16][17]"}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/46c806fe3fd051b5.png)
![taskEvaluate["WMTe2g", {"\"Luigi often said to me that he never wanted the brothers to end up in court,\" she wrote."}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/6eac03a031342bb0.png)
![taskEvaluate["WMTe2f", {"This image section from an infrared recording by the Spitzer telescope shows a \"family portrait\" of countless generations of stars: the oldest stars are seen as blue dots, while more difficult to identify are the pink-coloured \"new-borns\" in the star delivery room."}]](https://www.wolframcloud.com/obj/resourcesystem/images/a65/a6539710-e485-4580-98de-7cd073d3afb6/1966498842de857f.png)
