Resource retrieval
Get the pre-trained net:
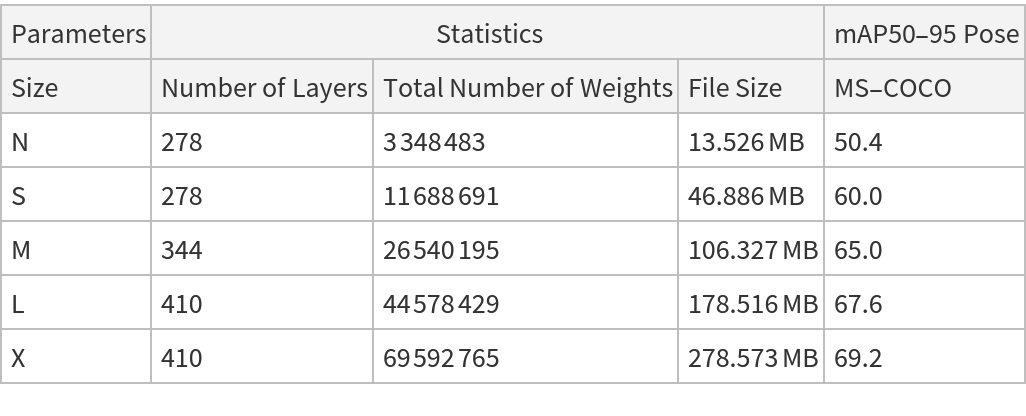
NetModel parameters
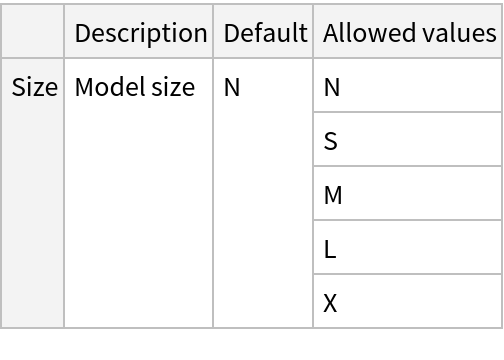
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Write an evaluation function to scale the result to the input image size and suppress the least probable detections:
Basic usage
Obtain the detected bounding boxes with their corresponding classes and confidences as well as the locations of human joints for a given image:
Inspect the prediction keys:
The "ObjectDetection" key contains the coordinates of the detected objects as well as their confidences and classes:
The "KeypointEstimation" key contains the locations of the top predicted keypoints:
The "KeypointConfidence" key contains the confidences for each person’s keypoints:
Inspect the predicted keypoint locations:
Visualize the keypoints:
Visualize the keypoints grouped by person:
Visualize the keypoints grouped by a keypoint type:
Define a function to combine the keypoints into a skeleton shape:
Visualize the pose keypoints, object detections and human skeletons:
Network result
The network computes eight thousand four hundred bounding boxes, the position of the keypoints with their probabilities and the probability of an object inside the box:
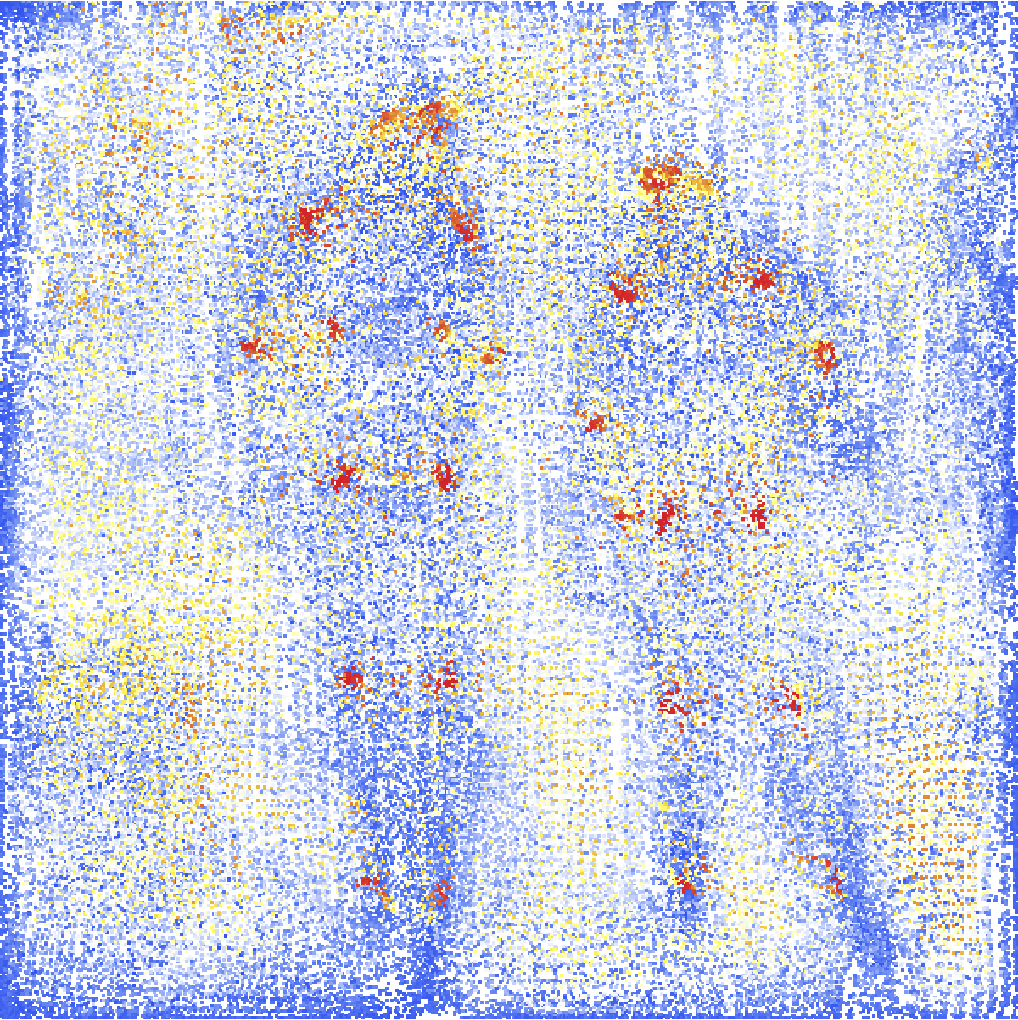
Rescale the "KeyPoints" to the coordinates of the input image and visualize them scaled and colored by their probability measures:
Overlay the heat map on the image:
Rescale the bounding boxes to the coordinates of the input image and visualize them scaled by their "Objectness" measures:
Superimpose the predictions on top of the input received by the net:
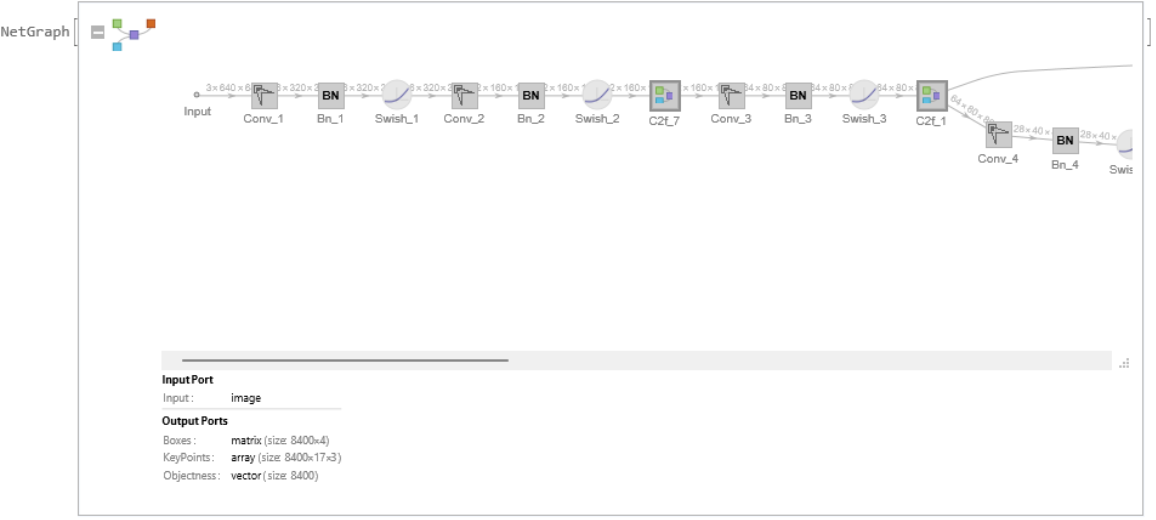
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
The size is similar to the byte count of the resource object:
Check some metadata of the ONNX model:
Import the model back into Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:

![netevaluate[net_, img_, detectionThreshold_ : .25, overlapThreshold_ : .5] := Module[
{imgSize, w, h, probableObj, probableBoxes, probableScores, probableKeypoints, max, scale, padx, pady, results, nms, x1, y1, x2, y2}, (*define image dimensions*)
imgSize = 640;
{w, h} = ImageDimensions[img]; (*get inference*)
results = net[img]; (*filter by probability*)
(*very small probability are thresholded*)
probableObj = UnitStep[
results["Objectness"] - detectionThreshold]; {probableBoxes, probableScores, probableKeypoints} = Map[Pick[#, probableObj, 1] &, {results["Boxes"], results["Objectness"], results["KeyPoints"]}];
If[Or[Length[probableBoxes] == 0, Length[probableKeypoints] == 0], Return[{}]]; max = Max[{w, h}];
scale = max/imgSize;
{padx, pady} = imgSize*(1 - {w, h}/max)/2; (*transform keypoints coordinates to fit the input image size*)
probableKeypoints = Apply[
{
{
Clip[Floor[scale*(#1 - padx)], {1, w}],
Clip[Floor[scale*(imgSize - #2 - pady)], {1, h}]
},
#3
} &,
probableKeypoints, {2}
]; (*transform coordinates into rectangular boxes*)
probableBoxes = Apply[
(
x1 = Clip[Floor[scale*(#1 - #3/2 - padx)], {1, w}];
y1 = Clip[Floor[scale*(imgSize - #2 - #4/2 - pady)], {1, h}];
x2 = Clip[Floor[scale*(#1 + #3/2 - padx)], {1, w}];
y2 = Clip[Floor[scale*(imgSize - #2 + #4/2 - pady)], {1, h}];
Rectangle[{x1, y1}, {x2, y2}]
) &, probableBoxes, 1
]; (*gather the boxes of the same class and perform non-
max suppression*)
nms = ResourceFunction["NonMaximumSuppression"][
probableBoxes -> probableScores, "Index", MaxOverlapFraction -> overlapThreshold];
results = Association[];
results["ObjectDetection"] = Part[Transpose[{probableBoxes, probableScores}], nms];
results["KeypointEstimation"] = Part[probableKeypoints, nms][[All, All, 1]];
results["KeypointConfidence"] = Part[probableKeypoints, nms][[All, All, 2]];
results
];](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/5b54f73142ef6db8.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/340b96f9-6411-4a10-8910-8e3100b9ebae"]](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/14ce3ce660e36445.png)




![HighlightImage[testImage, AssociationThread[
Range[Length[Transpose@keypoints]] -> Transpose@keypoints], ImageLabels -> None, ImageLegends -> labels]](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/5a4a3c61780509ca.png)

![HighlightImage[testImage,
AssociationThread[Range[Length[#]] -> #] & /@ {keypoints, Map[getSkeleton, keypoints], predictions["ObjectDetection"][[;; , 1]]},
ImageLabels -> None
]](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/6b756c289b5a3cbc.png)

![imgSize = 640;
{w, h} = ImageDimensions[testImage];
max = Max[{w, h}];
scale = max/imgSize;
{padx, pady} = imgSize*(1 - {w, h}/max)/2;
heatpoints = Flatten[Apply[
{
{Clip[Floor[scale*(#1 - padx)], {1, w}],
Clip[Floor[scale*(imgSize - #2 - pady)], {1, h}]
} ->
ColorData["TemperatureMap"][#3]
} &,
res["KeyPoints"], {2}
]];](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/7153eae9738f8523.png)

![boxes = Apply[
(
x1 = Clip[Floor[scale*(#1 - #3/2 - padx)], {1, w}];
y1 = Clip[Floor[scale*(imgSize - #2 - #4/2 - pady)], {1, h}];
x2 = Clip[Floor[scale*(#1 + #3/2 - padx)], {1, w}];
y2 = Clip[Floor[scale*(imgSize - #2 + #4/2 - pady)], {1, h}];
Rectangle[{x1, y1}, {x2, y2}]
) &, res["Boxes"], 1
];](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/25570c24cff325dd.png)
![HighlightImage[testImage, Graphics[
MapThread[{EdgeForm[Opacity[Total[#1] + .01]], #2} &, {res[
"Objectness"], boxes}], BaseStyle -> {FaceForm[], EdgeForm[{Thin, Black}]}], BaseStyle -> {FaceForm[], EdgeForm[{Thin, Red}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/1e8e5bb79d57c8dc.png)




![onnxFile = Export[FileNameJoin[{$TemporaryDirectory, "net.onnx"}], NetModel["YOLO V8 Pose Trained on MS-COCO Data"]]](https://www.wolframcloud.com/obj/resourcesystem/images/a1c/a1ce6e1a-604f-4ed0-af08-8c99ea60f7c5/3db4c4b3ecd528e7.png)
