YOLOR
Trained on
MS-COCO Data
YOLO (You Only Learn One Representation) Version R is a family of object detection models published in May 2021. It is characterized by a unified network that can accomplish various tasks, integrating implicit and explicit knowledge by leveraging techniques such as kernel space alignment, prediction refinement and a convolutional neural network with multitask learning. These models achieve comparable object detection accuracy as the Scaled-YOLO Version 4 models while having an inference speed faster by 88%.
Examples
Resource retrieval
Get the pre-trained net:
NetModel parameters
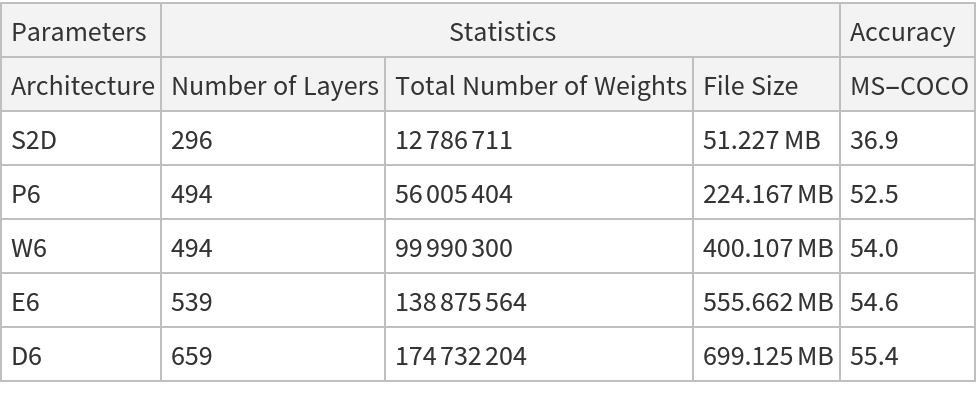
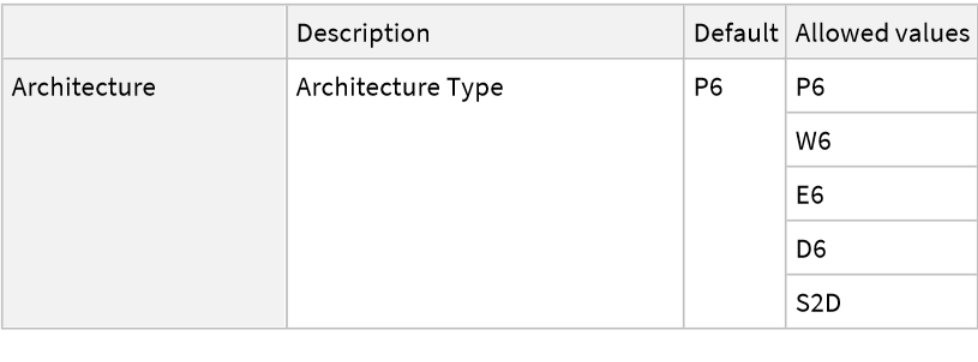
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Write an evaluation function to scale the result to the input image size and suppress the least probable detections:
Basic usage
Obtain the detected bounding boxes with their corresponding classes and confidences for a given image:
Inspect which classes are detected:
Visualize the detection:
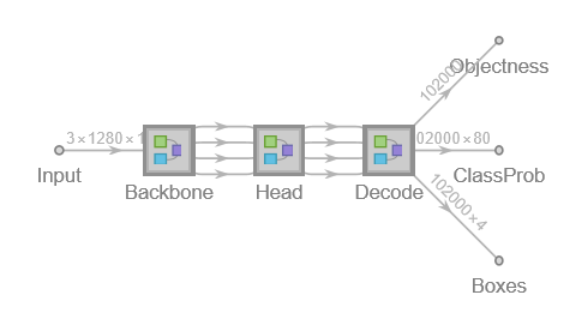
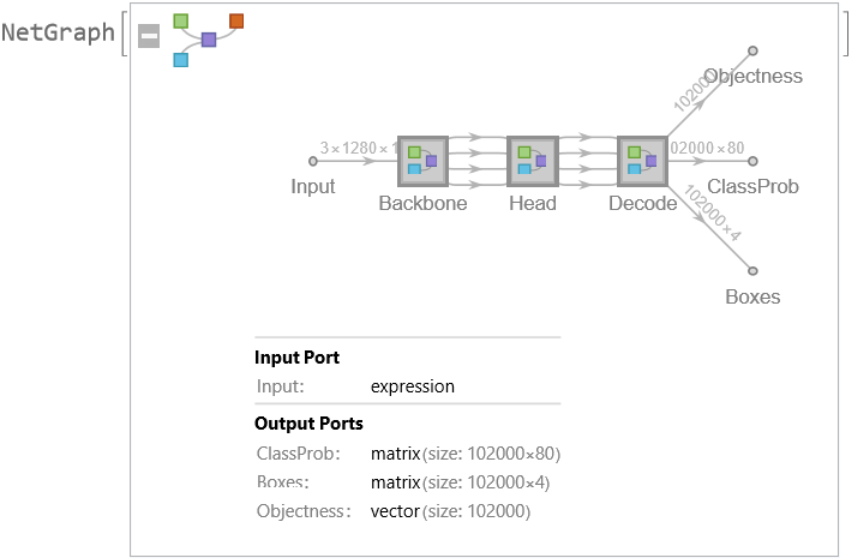
Network result
The network computes 102,200 bounding boxes and the probability that the objects in each box are of any given class:
Rescale the bounding boxes to the coordinates of the input image and visualize them scaled by their "objectness" measures:
Visualize all the boxes scaled by the probability that they contain a cat:
Superimpose the cat prediction on top of the input received by the net:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Resource History
Reference
-
C.-Y. Wang, I.-H. Yeh, H.-Y. M. Liao,"You Only Learn One Representation: Unified Network for Multiple Tasks," arXiv:2105.04206v1 (2021)
- Available from:
-
Rights:
GNU General Public License

![netevaluate[model_, img_, detectionThreshold_ : .5, overlapThreshold_ : .5] := Module[{imgSize, classes, coords, obj, scores, bestClass, probable, probableClasses, probableScores, probableBoxes, h, w, max, scale, padding, nms, finals},
imgSize = Last@NetExtract[model, {"Input", "Output"}];
{classes, coords, obj} = Values@model[img];
(*each class probability is rescaled with the box objectness*) scores = classes*obj;
bestClass = Last@*Ordering /@ scores;
(*filter by probability*)
(*very small probability are thresholded*) probable = UnitStep[obj - detectionThreshold]; {probableClasses, probableBoxes, probableScores} = Map[Pick[#, probable, 1] &, {labels[[bestClass]], coords, obj}];
If[Length[probableBoxes] == 0, Return[{}]];
(*transform coordinates into rectangular boxes*)
{w, h} = ImageDimensions[img];
max = Max[{w, h}];
scale = max/imgSize ;
padding = imgSize*(1 - {w, h}/max)/2;
probableBoxes = Apply[
Rectangle[
scale*({#1 - #3/2, imgSize - #2 - #4/2} - padding),
scale*({#1 + #3/2, imgSize - #2 + #4/2} - padding)
] &, probableBoxes, 1];
(*gather the boxes of the same class and perform non-
max suppression*) nms = nonMaximumSuppression[probableBoxes -> probableScores, "Index"];
finals = Transpose[{probableBoxes, probableClasses, probableScores}];
Part[finals, nms]
];](https://www.wolframcloud.com/obj/resourcesystem/images/821/82167eed-0f5e-4b97-8025-c25def63ff60/584773bd625d1787.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/0309ff3f-1bfe-4013-9df4-e1654085540e"]](https://www.wolframcloud.com/obj/resourcesystem/images/821/82167eed-0f5e-4b97-8025-c25def63ff60/54e61de3e2646647.png)

![rectangles = Block[
{w, h, max, imgSize, scale, padding},
{w, h} = ImageDimensions[testImage];
max = Max[{w, h}];
imgSize = 1280;
scale = max/imgSize ;
padding = imgSize*(1 - {w, h}/max)/2;
Apply[
Rectangle[
scale*({#1 - #3/2, imgSize - #2 - #4/2} - padding),
scale*({#1 + #3/2, imgSize - #2 + #4/2} - padding)
] &,
res["Boxes"],
1
]
];](https://www.wolframcloud.com/obj/resourcesystem/images/821/82167eed-0f5e-4b97-8025-c25def63ff60/27030a4832802ce8.png)

![Graphics[
MapThread[{EdgeForm[Opacity[#1 + .01]], #2} &, {res["Objectness"]*
Extract[res["ClassProb"], {All, idx}], rectangles}],
BaseStyle -> {FaceForm[], EdgeForm[{Thin, Black}]}
]](https://www.wolframcloud.com/obj/resourcesystem/images/821/82167eed-0f5e-4b97-8025-c25def63ff60/0e2180be0e6972af.png)

![HighlightImage[testImage, Graphics[MapThread[{EdgeForm[{Thickness[#1/100], Opacity[(#1 + .01)/3]}], #2} &, {res["Objectness"]*
Extract[res["ClassProb"], {All, idx}], rectangles}]], BaseStyle -> {FaceForm[], EdgeForm[{Thin, Red}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/821/82167eed-0f5e-4b97-8025-c25def63ff60/7ef44cb7c3f67625.png)