Language identification
Whisper can transcribe and translate audio from 99 languages, with Whisper Large adding support for Cantonese. Retrieve the list of available languages from the label set:
Obtain a collection of audio samples featuring speakers of different languages:
Define a function to detect the language of the audio sample. Whisper determines the language by selecting the most likely language token after the initial pass of the decoder (the following code needs definitions from the "Evaluation function" section):
Detect the languages:
Transcribe and translate the audio samples:
Transcription and Translation generation
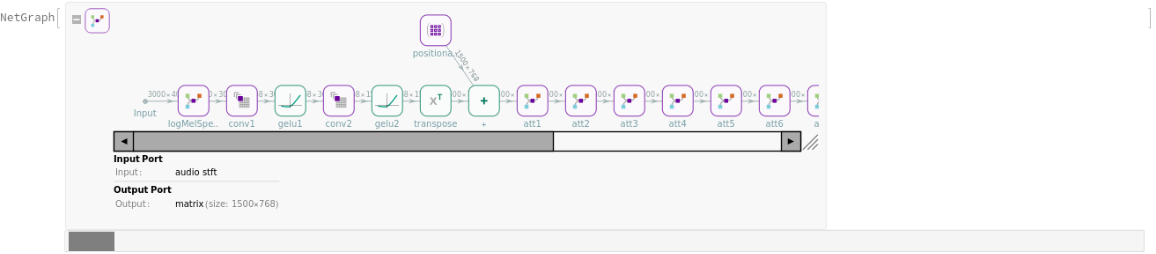
The translation pipeline makes use of two separate transformer nets, encoder and decoder:
The encoder preprocesses the input audio into a log-Mel spectrogram, capturing the signal's frequency content over time:
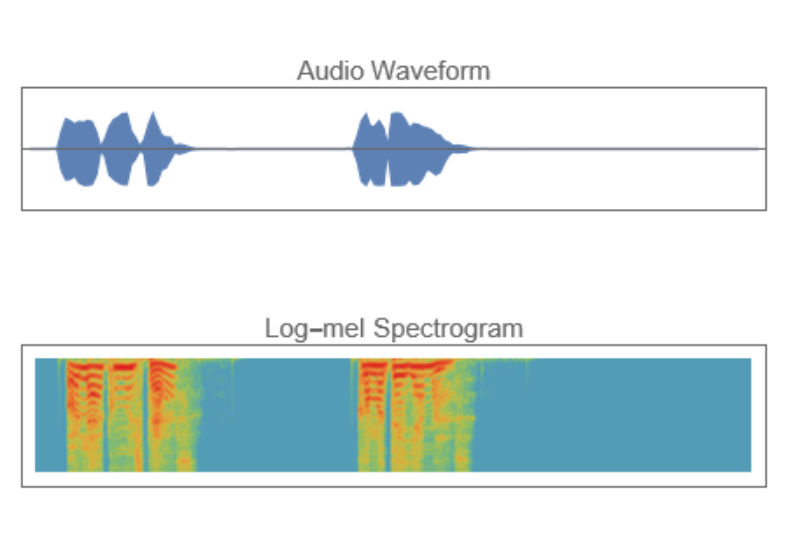
Get an input audio sample and compute its log-Mel spectrogram:
Visualize the log-Mel spectrogram and the audio waveform:
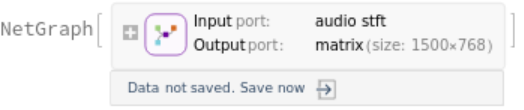
The encoder processes the input once, producing a feature matrix of size 1500x768:
The decoding step involves running the decoder multiple times recursively, with each iteration producing a subword token of the translated or transcribed audio. The decoder receives several inputs:
• The port "Input1" takes the subword token generated by the previous evaluation of the decoder.
• The port "Index" takes an integer keeping count of how many times the decoder was evaluated (positional encoding).
• The port "Input2" takes the encoded features produced by the encoder. The data fed to this input is the same for every evaluation of the decoder.
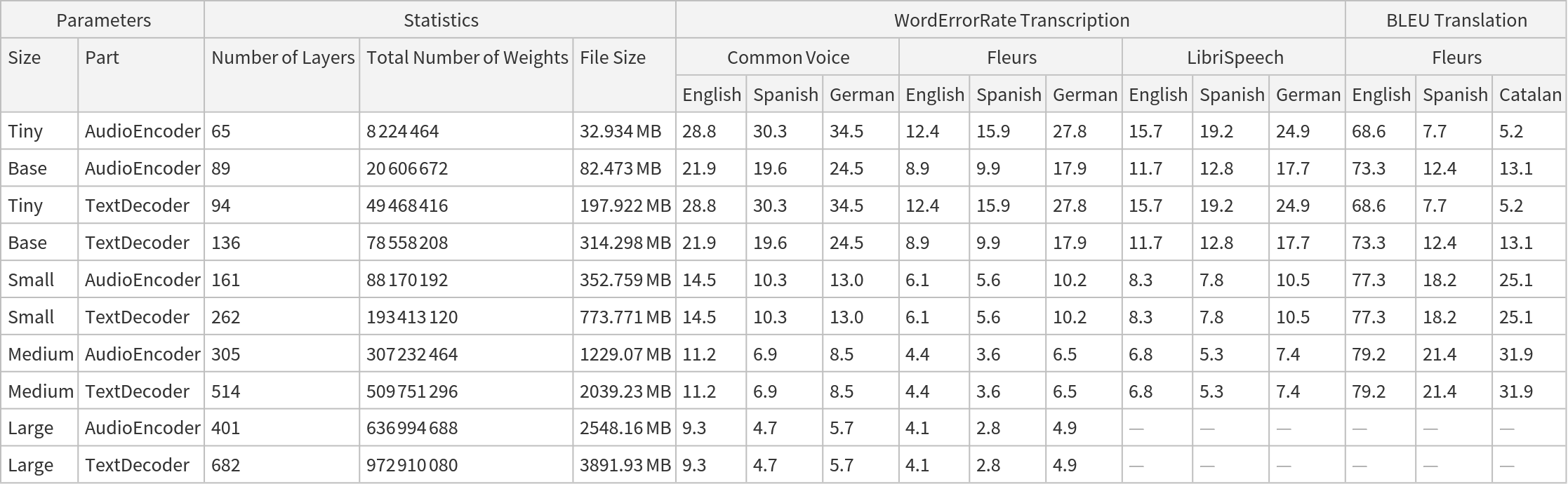
• The ports "State1", "State2"... take the self-attention key and value arrays for all the past tokens. Their size grows by one at each evaluation. The default ("Size" -> "Small") decoder has 12 attention blocks, which makes for 24 states: 12 key arrays and 12 value arrays.
The initial prompt for the decoder is a sequence of context tokens that guides Whisper's decoding process by specifying the task to perform and the audio's language. These tokens can be hard-coded to explicitly control the output or left flexible, allowing the model to automatically detect the language and task. Define the initial prompt for transcribing audio in Spanish:
Retrieve the integer codes of the prompt tokens:
Before starting the decoding process, initialize the decoder's inputs:
Use the decoder iteratively to transcribe the audio. The recursion keeps going until the EndOfString token is generated or the maximum number of iterations is reached:
Display the generated tokens:
Obtain a readable representation of the tokens by converting the text into UTF8:
Change the task type to translate by assigning the third element in the prompt list to "|Translate|":
Generate again based on the new prompt:
Display the generated tokens:
Obtain a readable representation of the tokens:

![NetModel[{"Whisper-V1 Multilingual Nets", "Size" -> "Large", "Part" -> "TextDecoder"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/1b474e98301157ff.png)

![suppress[logits_, tokenIds_ : {}] := ReplacePart[logits, Thread[tokenIds -> -Infinity]];
rescore[logits_, temp_ : 1] := Block[{expRescaledLog, total}, expRescaledLog = Quiet[Exp[logits/temp]] /. Indeterminate -> 0.;
total = Total[expRescaledLog, {-1}] /. 0. -> 1.;
expRescaledLog/total]
sample[probs_, temp_, tokenIds_ : {}] := Block[{weights, suppressLogits}, suppressLogits = suppress[Log[probs], tokenIds];
weights = Quiet@rescore[suppressLogits, temp];
First@
If[Max[weights] > 0, RandomSample[weights -> Range@Length@weights, 1], FirstPosition[#, Max[#]] &@
Exp[suppressLogits](*low temperature cases*)]];
sample[probs_, 0., tokenIds_ : {}] := First@FirstPosition[#, Max[#]] &@suppress[probs, tokenIds];
sample[probs_, 0, tokenIds_ : {}] := sample[probs, 0., tokenIds];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/4304696e903514ad.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/f70f3051-9798-4d62-a234-17aa726167d1"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/75d8f8110daa90e3.png)
![(*Define needsFallbackQ function*)
fallbackQ[noSpeech_, compressionRatio_, compressionRatioThresh_, avgLogProb_, logProbThresh_] := Which[
And[noSpeech, avgLogProb < logProbThresh], False,(*Silent*)
avgLogProb < logProbThresh, True,(*average log probability is too low*)
compressionRatio > compressionRatioThresh, True (*too repetitive*),
True, False
];
(*Define compressionRatioF function*)
compressionRatio[tokens_, labels_] := With[
{textBytes = StringToByteArray[
StringJoin@
FromCharacterCode[
Flatten@ToCharacterCode[labels[[tokens]], "Unicode"], "UTF8"],
"UTF-8"]},
N@Length[textBytes]/StringLength[Compress[textBytes]]
];
(*Define decodeWithFallback function*)
Options[decodeWithFallback] = {"Language" -> Automatic, "Task" -> "Transcribe", "IncludeTimestamps" -> False, "SuppressSpecialTokens" -> False, "LogProbabilityThreshold" -> -1, "CompressionRatioThreshold" -> 7.2, "Temperature" -> 0, MaxIterations -> 224, TargetDevice -> "CPU"};
decodeWithFallback[features_, textDecoder_, initStates_, outPorts_, labels_, prev_, opts : OptionsPattern[]] := Module[{tokens, noSpeech, avgLogProb, compressRatio, outPortst, needsFallback = True, temperatures, i = 1},
temperatures = Range[OptionValue["Temperature"], 1, 0.2];
(*if needsFallback is True iterate over different temperatures*)
While[i <= Length[temperatures],
{tokens, noSpeech, avgLogProb} = generate[features, prev, textDecoder, initStates, outPorts, labels, "Language" -> OptionValue["Language"], "Task" -> OptionValue["Task" ], "IncludeTimestamps" -> OptionValue["IncludeTimestamps"], "SuppressSpecialTokens" -> OptionValue["SuppressSpecialTokens"],
"Temperature" -> temperatures[[i]], MaxIterations -> OptionValue[MaxIterations], TargetDevice -> OptionValue[TargetDevice]];
(*update iterator*)
i++;
(*update needsFallback*)
compressRatio = compressionRatio[tokens, labels];
needsFallback = fallbackQ[noSpeech, compressRatio, OptionValue["CompressionRatioThreshold"], avgLogProb, OptionValue["LogProbabilityThreshold"]];
If[! needsFallback, Break[]];
];
tokens (*return the generated tokens for this chunk*)
];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/12371e18d72ce937.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/3279e9cf-1b03-43fd-abb4-15e751478d80"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/387e17038add73b3.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/8ff87dad-3263-41f7-9075-17a0ae621476"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/3ef790f9cfd5a875.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/991fcdba-e4ed-4013-b64b-8c807bb8a077"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/678c3c23105f7be5.png)


![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/7e188d99-83ee-4b31-bb03-c8494dabe2b2"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/6d07d006a5b427f7.png)
![getLanguage[audio_] := Module[{encoded, labels, languages, eosCode, textDecoder, initStates, init, probs, language, aud},
aud = AudioPad[audio, 30 - Min[30, QuantityMagnitude[Duration[audio]]]];
encoded = NetModel["Whisper-V1 Multilingual Nets"][aud];
labels = DeleteCases[NetModel["Whisper-V1 Multilingual Nets", "Labels"], "|Cantonese|"];
languages = <|50260 -> "|English|", 50261 -> "|Chinese|", 50262 -> "|German|", 50263 -> "|Spanish|", 50264 -> "|Russian|", 50265 -> "|Korean|", 50266 -> "|French|", 50267 -> "|Japanese|", 50268 -> "|Portuguese|", 50269 -> "|Turkish|", 50270 -> "|Polish|", 50271 -> "|Catalan|", 50272 -> "|Dutch|", 50273 -> "|Arabic|", 50274 -> "|Swedish|", 50275 -> "|Italian|", 50276 -> "|Indonesian|", 50277 -> "|Hindi|", 50278 -> "|Finnish|", 50279 -> "|Vietnamese|", 50280 -> "|Hebrew|", 50281 -> "|Ukrainian|", 50282 -> "|Greek|", 50283 -> "|Malay|", 50284 -> "|Czech|", 50285 -> "|Romanian|", 50286 -> "|Danish|", 50287 -> "|Hungarian|", 50288 -> "|Tamil|", 50289 -> "|Norwegian|", 50290 -> "|Thai|", 50291 -> "|Urdu|", 50292 -> "|Croatian|", 50293 -> "|Bulgarian|", 50294 -> "|Lithuanian|", 50295 -> "|Latin|", 50296 -> "|Maori|", 50297 -> "|Malayalam|", 50298 -> "|Welsh|", 50299 -> "|Slovak|", 50300 -> "|Telugu|", 50301 -> "|Persian|", 50302 -> "|Latvian|", 50303 -> "|Bengali|", 50304 -> "|Serbian|", 50305 -> "|Azerbaijani|", 50306 -> "|Slovenian|", 50307 -> "|Kannada|", 50308 -> "|Estonian|", 50309 -> "|Macedonian|", 50310 -> "|Breton|", 50311 -> "|Basque|", 50312 -> "|Icelandic|", 50313 -> "|Armenian|", 50314 -> "|Nepali|", 50315 -> "|Mongolian|", 50316 -> "|Bosnian|", 50317 -> "|Kazakh|", 50318 -> "|Albanian|", 50319 -> "|Swahili|",
50320 -> "|Galician|", 50321 -> "|Marathi|", 50322 -> "|Punjabi|", 50323 -> "|Sinhala|", 50324 -> "|Khmer|", 50325 -> "|Shona|", 50326 -> "|Yoruba|", 50327 -> "|Somali|", 50328 -> "|Afrikaans|", 50329 -> "|Occitan|", 50330 -> "|Georgian|", 50331 -> "|Belarusian|", 50332 -> "|Tajik|", 50333 -> "|Sindhi|", 50334 -> "|Gujarati|", 50335 -> "|Amharic|", 50336 -> "|Yiddish|", 50337 -> "|Lao|", 50338 -> "|Uzbek|", 50339 -> "|Faroese|", 50340 -> "|Haitian creole|", 50341 -> "|Pashto|", 50342 -> "|Turkmen|", 50343 -> "|Nynorsk|", 50344 -> "|Maltese|",
50345 -> "|Sanskrit|", 50346 -> "|Luxembourgish|", 50347 -> "|Myanmar|", 50348 -> "|Tibetan|", 50349 -> "|Tagalog|",
50350 -> "|Malagasy|", 50351 -> "|Assamese|", 50352 -> "|Tatar|", 50353 -> "|Hawaiian|", 50354 -> "|Lingala|", 50355 -> "|Hausa|", 50356 -> "|Bashkir|", 50357 -> "|Javanese|", 50358 -> "|Sundanese|"|>;
eosCode = 50259;
textDecoder = NetModel[{"Whisper-V1 Multilingual Nets", "Part" -> "TextDecoder"}];
initStates = AssociationMap[Function[x, {}], Select[Information[textDecoder, "InputPortNames"], StringStartsQ["State"]]];
init = Join[
<|
"Index" -> 1,
"Input1" -> eosCode,
"Input2" -> encoded
|>,
initStates
];
probs = textDecoder[init, NetPort[{"softmax", "Output"}]];
language = sample[probs, 0, Complement[Range[Length[labels]], Keys[languages]]];
labels[[language]]
];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/3f3d872b2e816ce0.png)
![Dataset@KeyValueMap[<|<|"Language" -> #1|> -> <|
"Transcription" -> netevaluate[#2, "Language" -> #1], "Translation" -> netevaluate[#2, "Task" -> "Translate", "Language" -> #1]|>|> &,
audios]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/23fd8e0a5603ee42.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/8523b8e1-a77b-4cd3-b074-651bcee2dd3e"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/68a5d4ffcd8f5428.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/09a484cb-5584-486d-8d2b-cb11ce2d4227"]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/69a10de5e317963e.png)
![GraphicsColumn[{
AudioPlot[audio, PlotRange -> {0, 5}, PlotLabel -> "Audio Waveform",
FrameTicks -> None, ImageSize -> {300, 100}],
MatrixPlot[logMelSpectrogram, PlotLabel -> "Log-mel Spectrogram", ColorFunction -> "Rainbow", FrameTicks -> None, ImageSize -> {300, 100}, PlotRange -> {{0, 80}, {0, 500}}]}, ImageSize -> Medium]](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/729dd2e9de029b23.png)

![index = 1;
sosCode = 50259;
init = Join[
<|"Index" -> index,
"Input1" -> sosCode,
"Input2" -> audioFeatures
|>,
initStates
];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/60f22432caa5f388.png)
![eosCode = 50258;
isGenerating = False;
tokens = {};
NestWhile[
Function[
If[SameQ[index, Length[prompt]], isGenerating = True];
netOut = textDecoder[#];
If[isGenerating, AppendTo[tokens, netOut["Output"]]];
Join[
KeyMap[StringReplace["OutState" -> "State"], netOut] (*include last states*),
<|"Index" -> ++index, (*update index*)
"Input1" -> If[isGenerating, netOut["Output"], promptCodes[[index]]], (*input last generated token*)
"Input2" -> audioFeatures (*audio features for transcription*)
|>
]
],
init,
#Input1 =!= eosCode &,(*stops when EndOfString token is generated*)
1,
100 (*Max iterations*)
];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/3267976684f45565.png)
![index = 1;
isGenerating = False;
tokens = {};
NestWhile[
Function[
If[SameQ[index, Length[prompt]], isGenerating = True];
netOut = textDecoder[#];
If[isGenerating, AppendTo[tokens, netOut["Output"]]];
Join[
KeyMap[StringReplace["OutState" -> "State"], netOut] (*include last states*),
<|"Index" -> ++index, (*update index*)
"Input1" -> If[isGenerating, netOut["Output"], promptCodes[[index]]], (*input last generated token*)
"Input2" -> audioFeatures (*audio features for transcription*)
|>
]
],
init,
#Input1 =!= eosCode &,(*stops when EndOfString token is generated*)
1,
100 (*Max iterations*)
];](https://www.wolframcloud.com/obj/resourcesystem/images/058/058a6c6a-1c7b-4fd1-a439-144cb89197a3/4895a742d432e355.png)