Resource retrieval
Get the pre-trained net:
Basic usage
Classify an image:
The prediction is an Entity object, which can be queried:
Get a list of available properties of the predicted Entity:
Obtain the probabilities of the ten most likely entities predicted by the net:
An object outside the list of the ImageNet classes will be misidentified:
Obtain the list of names of all available classes:
Feature extraction
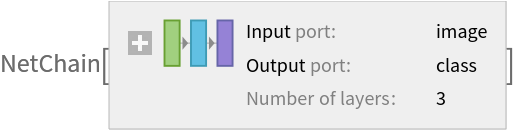
Remove the last three layers of the trained net so that the net produces a vector representation of an image:
Get a set of images:
Visualize the features of a set of images:
Visualize convolutional weights
Extract the weights of the first convolutional layer in the trained net:
Visualize the weights as a list of 64 images of size 3x3:
Transfer learning
Use the pre-trained model to build a classifier for telling apart images of dogs and cats. Create a test set and a training set:
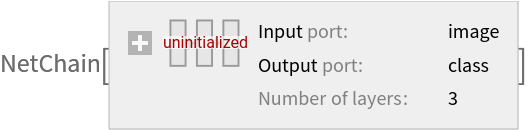
Remove the linear layer from the pre-trained net:
Create a new net composed of the pre-trained net followed by a linear layer and a softmax layer:
Train on the dataset, freezing all the weights except for those in the "linearNew" layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
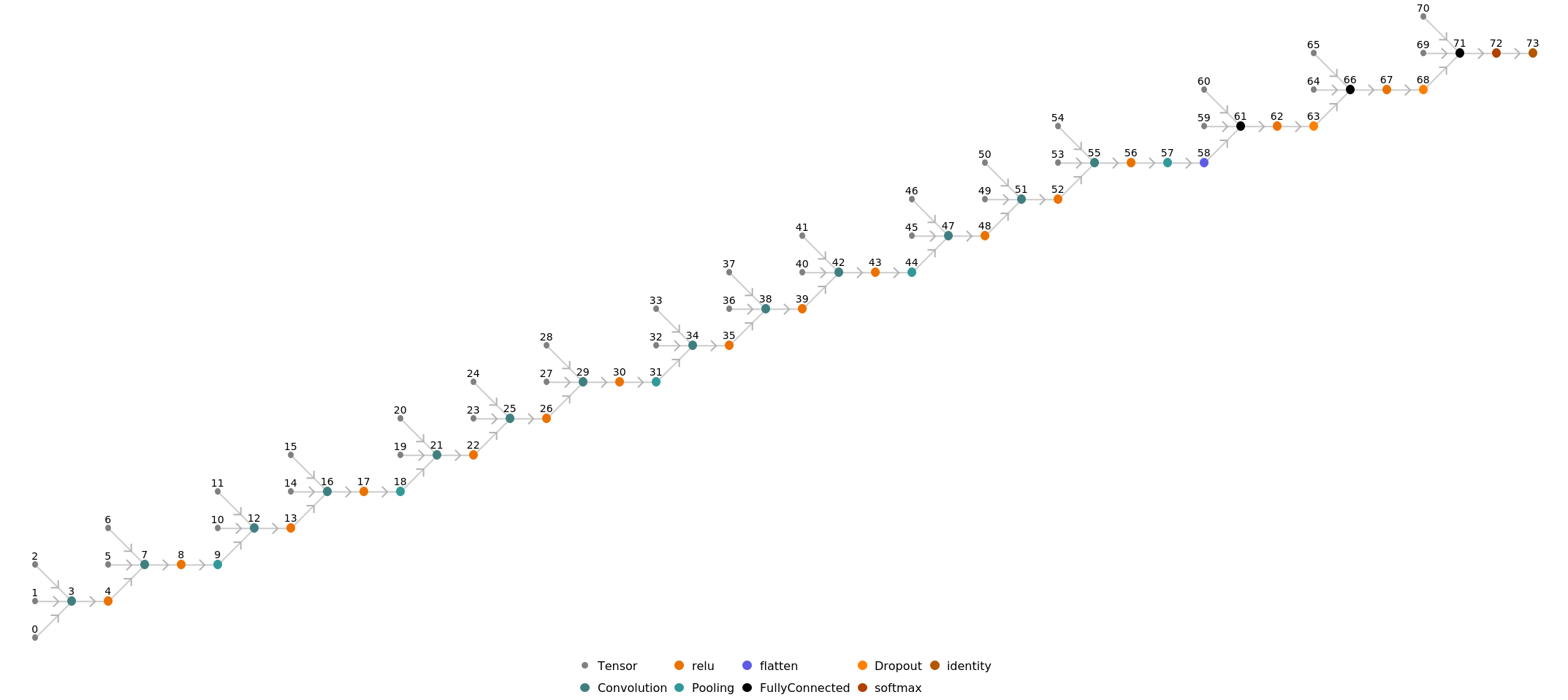
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
Represent the MXNet net as a graph:
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/5a427e29-99f5-45ff-801d-4e21d41fbb19"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/1e02398fdb5ddef1.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/9a759d9d-cd6f-4cbe-b9ac-30c6d269908b"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/076007e5a97c03b7.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/9048681b-f5f9-4801-b4f7-973a73e0692c"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/238366d6384f2ccc.png)
![EntityValue[
NetExtract[NetModel["VGG-16 Trained on ImageNet Competition Data"], "Output"][["Labels"]], "Name"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/2451270222fccfcb.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/6d2cbf46-519b-4b8a-93be-03174b3ad0f4"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/0e837e0db841c501.png)

![weights = NetExtract[
NetModel[
"VGG-16 Trained on ImageNet Competition Data"], {"conv1_1", "Weights"}];](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/108afa7c147c79bb.png)
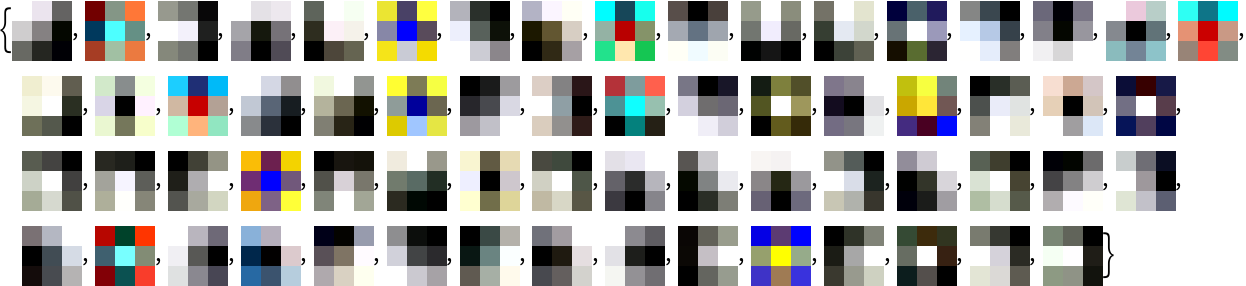
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/f88e65df-64d4-4daf-84b8-b893aec055f7"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/07000e5fc450811f.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/8d56159d-ca89-4ad7-bca4-1775589dee18"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/52c3e2096c021514.png)
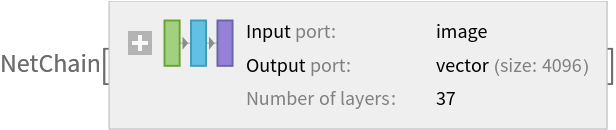
![newNet = NetChain[<|"pretrainedNet" -> tempNet, "linearNew" -> LinearLayer[], "softmax" -> SoftmaxLayer[]|>, "Output" -> NetDecoder[{"Class", {"cat", "dog"}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/79d1e3692ad0a935.png)
![NetInformation[
NetModel[
"VGG-16 Trained on ImageNet Competition Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/028037646e13fe2d.png)

![NetInformation[
NetModel[
"VGG-16 Trained on ImageNet Competition Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/7ff7bda5a1ce5e65.png)
![jsonPath = Export[FileNameJoin[{$TemporaryDirectory, "net.json"}], NetModel["VGG-16 Trained on ImageNet Competition Data"], "MXNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/08f/08fd9fd6-8bfb-4f9f-88b2-c4334919bcfd/57c28bfa912e26fe.png)