Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
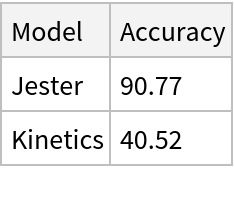
Identify the main action in a video:
Obtain the probabilities of the 10 most likely entities predicted by the net:
Obtain the list of names of all available classes:
NetModel architecture
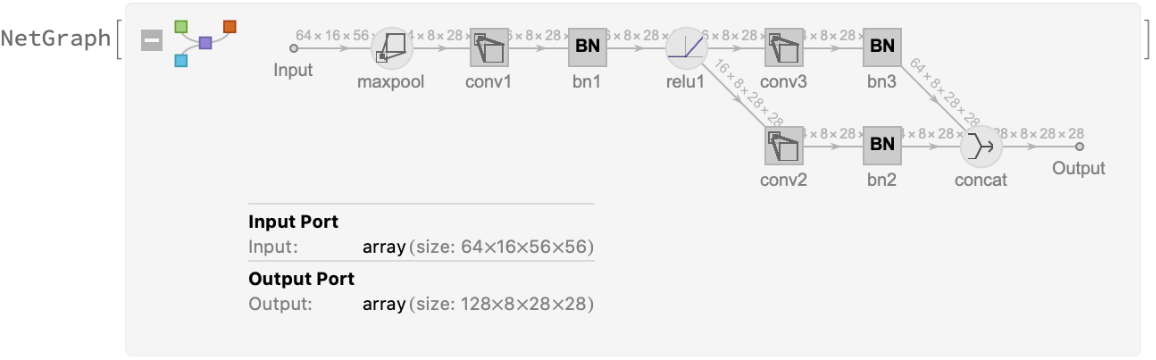
The SqueezeNet architecture uses the "fire module," which features a 1⨯1 "squeeze" convolution followed by 1⨯1 and 3⨯3 "expand" convolutions performed in parallel:
All modules follow this structure:
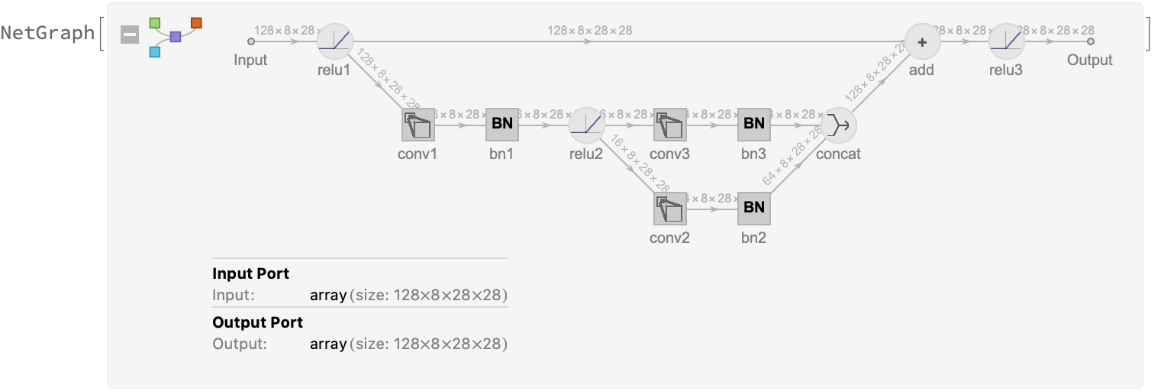
Alternate modules also feature a residual skip connection:
Feature extraction
Remove the last two layers of the trained net so that the net produces a vector representation of an image:
Get a set of videos:
Visualize the features of a set of videos:
Transfer learning
Use the pre-trained model to build a classifier for telling apart images from two action classes not present in the dataset. Create a test set and a training set:
Remove the last layers from the pre-trained net:
Create a new net composed of the pre-trained net followed by a linear layer and a softmax layer:
Train on the dataset, freezing all the weights except for those in the "Linear" new layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
Check some metadata of the ONNX model:
Import the model back into the Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:



![AssociationMap[
NetExtract[
NetModel["SqueezeNet-3D Trained on Video Datasets"], {"block1", #, "KernelSize"}
] &,
Table["conv" <> ToString[j], {j, 3}]
]](https://www.wolframcloud.com/obj/resourcesystem/images/00e/00e35201-c9ef-4dd0-b57c-0b7ca7bba1c6/751a71899c2472d4.png)
![Dataset@AssociationMap[
Function[block,
AssociationMap[
NetExtract[
NetModel["SqueezeNet-3D Trained on Video Datasets"], {block, #, "KernelSize"}] &,
Table["conv" <> ToString[j], {j, 3}]
]
],
Table["block" <> ToString[i], {i, 8}]
]](https://www.wolframcloud.com/obj/resourcesystem/images/00e/00e35201-c9ef-4dd0-b57c-0b7ca7bba1c6/64d3082de750fcae.png)

![FeatureSpacePlot[videos, FeatureExtractor -> extractor, LabelingFunction -> (Callout[
Thumbnail[VideoExtractFrames[#1, Quantity[1, "Frames"]], 20]] &),
LabelingSize -> 50, ImageSize -> 600]](https://www.wolframcloud.com/obj/resourcesystem/images/00e/00e35201-c9ef-4dd0-b57c-0b7ca7bba1c6/372872341a6f1436.png)

![dataset = Join @@ KeyValueMap[
Thread[
VideoSplit[#1, Most@Table[
Quantity[i, "Frames"], {i, 16, Information[#1, "FrameCount"][[1]], 16}]] -> #2] &,
videos
];](https://www.wolframcloud.com/obj/resourcesystem/images/00e/00e35201-c9ef-4dd0-b57c-0b7ca7bba1c6/3504647de0856586.png)

