Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
Get a video:
Show some of the video frames:
Identify the main action in a video:
Obtain the probabilities of the 10 most likely entities predicted by the net:
An activity outside the list of the Kinetics-400 classes will be misidentified:
Obtain the list of names of all available classes:
Identify the main action of the video over the moving frames:
Visualize convolutional weights
Extract the weights of the first convolutional layer in the trained net:
Show the dimensions of the weights:
Extract the kernels corresponding to the receptive fields:
Visualize the weights as a list of 45 images of size 7⨯7:
Network architecture
3D convolutional neural networks (3DCNNs) preserve temporal information, with filters over both time and space. "3D" architecture has all the convolutional blocks as 3DCNN. 3D kernels have a kernel size of L×H×W, where L denotes the temporal extent of the filter and H×W are the height and width of the filter. Extract the kernel size of the first convolutional layer from each of the convolutional blocks:
"Mixed" 3D convolutional neural networks (3DCNNs) use 3D convolutions for early layers and 2D convolutions for later layers. In the later blocks, L=1, which implies that different frames are processed independently:
Another way to approach this problem would be to replace 3D kernels of size L×H×W with a "(2+1)D" block consisting of spatial 2D convolutional filters of size 1×H×W and temporal convolutional filters of size L×1×1. Extract the first two convolution kernels from each block to explore the alternate spatial and temporal convolutions:
The summary graphs for spatiotemporal ResNet-18 architectures of "(2+1)D", "3D" and "Mixed" models are presented below:
Advanced usage
Recommended evaluation of the network is time consuming:
Evaluation speed scales almost linearly with "TargetLength". The encoder can be tuned appropriately for speed vs. performance:
Replace the encoder in the original NetModel:
Evaluate on the original video. The time of evaluation is reduced to a third, while the evaluation remains correct:
Feature extraction
Remove the last two layers of the trained net so that the net produces a vector representation of an image:
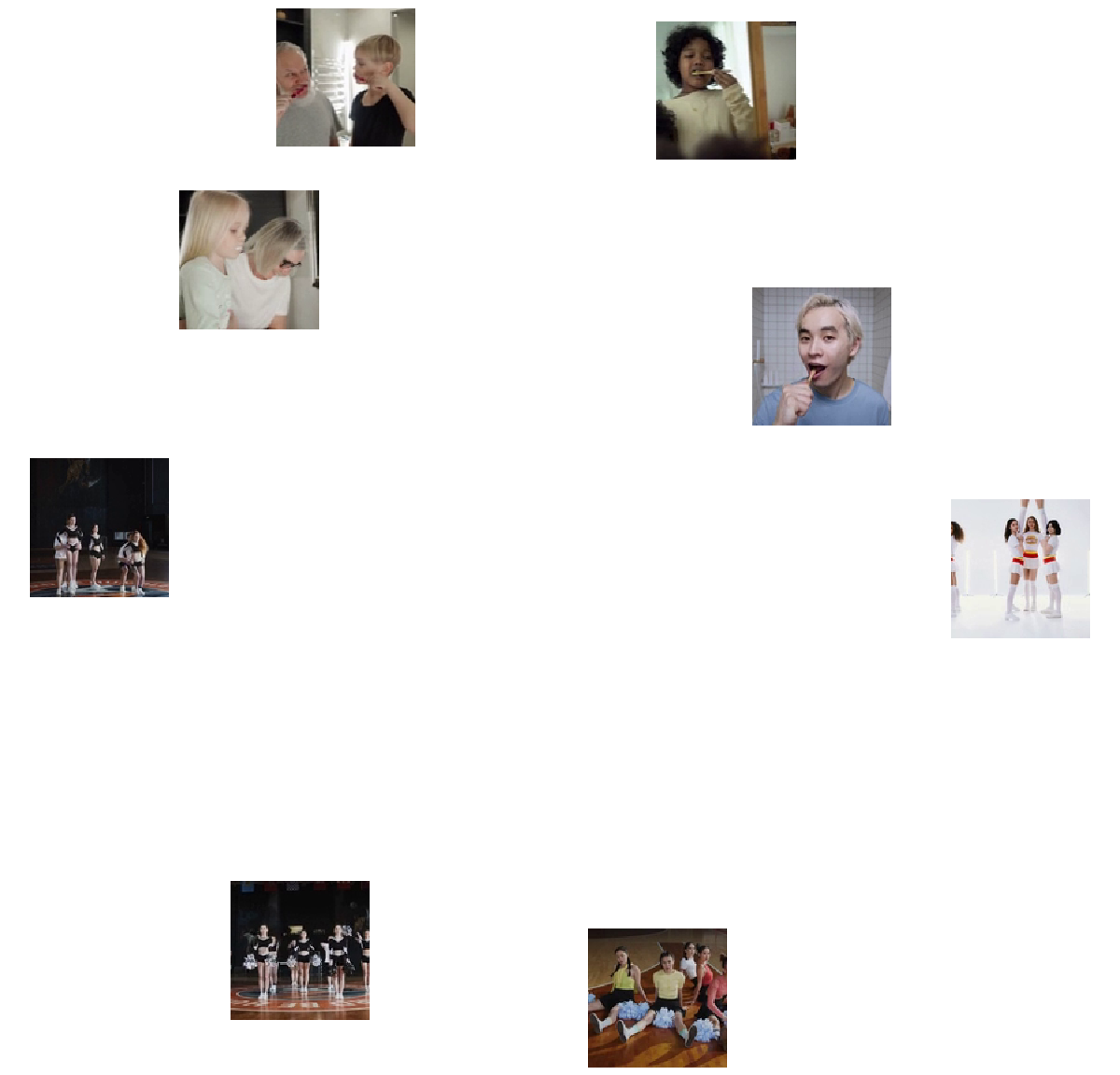
Get a set of videos:
Visualize the features of a set of videos:
Net information
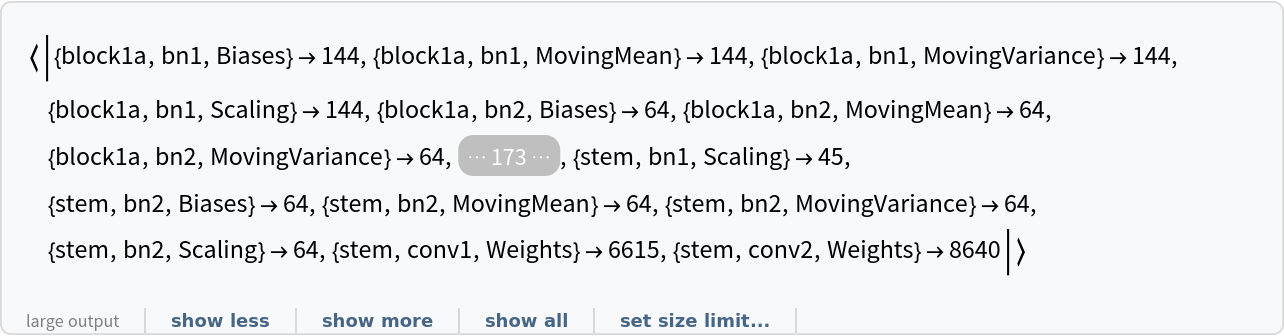
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
The size is similar to the byte count of the resource object:
Check some metadata of the ONNX model:
Import the model back into the Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:

![NetModel["Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data", "ParametersInformation"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/4ae2a241f7100d29.png)

![NetModel[{"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data", "Convolution" -> "3D"}]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/79a3a2fc70256615.png)
![NetModel[{"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data", "Convolution" -> "3D"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/10f91f38dc39a1aa.png)


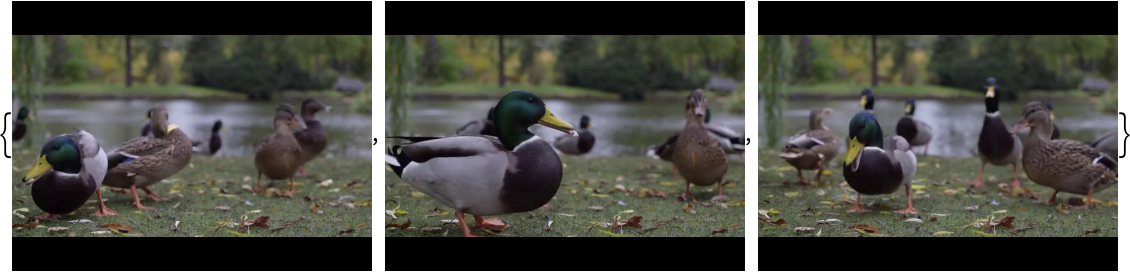
![NetExtract[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], {"Output", "Labels"}]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/443095846ae02ef0.png)

![VideoMapList[
RandomChoice[#Image] -> NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"][#Image] &, video, Quantity[16, "Frames"], Quantity[16, "Frames"]]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/76b9a73c2bbc7642.png)

![weights = NetExtract[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], {"stem", "conv1", "Weights"}];](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/2d156ceff7d67e7a.png)

![Table[blockName = StringJoin["block", ToString[Ceiling[i/2]], If[OddQ[i], "a", "b"]];
blockName -> NetExtract[
NetModel[{"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data", "Convolution" -> "3D"}], {blockName, "conv1", "KernelSize"}],
{i, 1, 8}
]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/0e133e7d1d521b44.png)
![Table[blockName = StringJoin["block", ToString[Ceiling[i/2]], If[OddQ[i], "a", "b"]];
blockName -> NetExtract[
NetModel[{"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data", "Convolution" -> "Mixed"}], {blockName, "conv1", "KernelSize"}],
{i, 1, 8}
]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/3981223c94018a92.png)
![Table[blockName = StringJoin["block", ToString[Ceiling[i/2]], If[OddQ[i], "a", "b"]];
blockName -> NetExtract[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], {{blockName, "conv1", "KernelSize"}, {blockName, "conv1", "KernelSize"}}],
{i, 8}
]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/32203f4dce5efcfe.png)


![AbsoluteTiming@
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"][video]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/0b780d29a05efbe0.png)
![enc[nframes_] := NetEncoder[{"VideoFrames", {112, 112}, "MeanImage" -> {0.43216, 0.394666, 0.37645}, "VarianceImage" -> {0.22803, 0.22145, 0.216989}, "ColorSpace" -> "RGB", "TargetLength" -> nframes, FrameRate -> Inherited}];
newEncoder = enc[5]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/090c63952338d2dd.png)
![newNet = NetReplacePart[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], "Input" -> newEncoder]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/543b22babb3245a7.png)
![extractor = NetTake[NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], {1, -2}]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/2de54b29758960c4.png)

![videos = Join[ResourceData["Cheerleading Video Samples"], ResourceData["Tooth Brushing Video Samples"]];](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/3a65a72bf3e90a26.png)
![FeatureSpacePlot[videos, FeatureExtractor -> extractor, LabelingFunction -> (Placed[Thumbnail@VideoFrameList[#1, 1][[1]], Center] &), LabelingSize -> 100, ImageSize -> 600]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/14050adddbed22e3.png)
![Information[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/15019cdb1d105d2d.png)
![Information[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/7020b61079a47e7e.png)
![Information[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/68996f9e905855cc.png)
![Information[
NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/1e99d45d7111044d.png)
![onnxFile = Export[FileNameJoin[{$TemporaryDirectory, "net.onnx"}], NetModel[
"Spatiotemporal ResNet-18 for Action Recognition Trained on Kinetics-400 Data"]]](https://www.wolframcloud.com/obj/resourcesystem/images/2ca/2ca899cc-76c7-4c8b-ab96-fd84f32312af/1677c104050f51b8.png)
