Resource retrieval
Get the pre-trained net:
Basic usage
Predict the next character in a piece of text:
The output values correspond to bytes in the UTF-8 encoding (modulo a subtraction by 1). Decode the prediction:
Note that since UTF-8 is a variable-length encoding, decoding single byte values may not always make sense:
Multiplicative LSTM and UTF-8 encoding
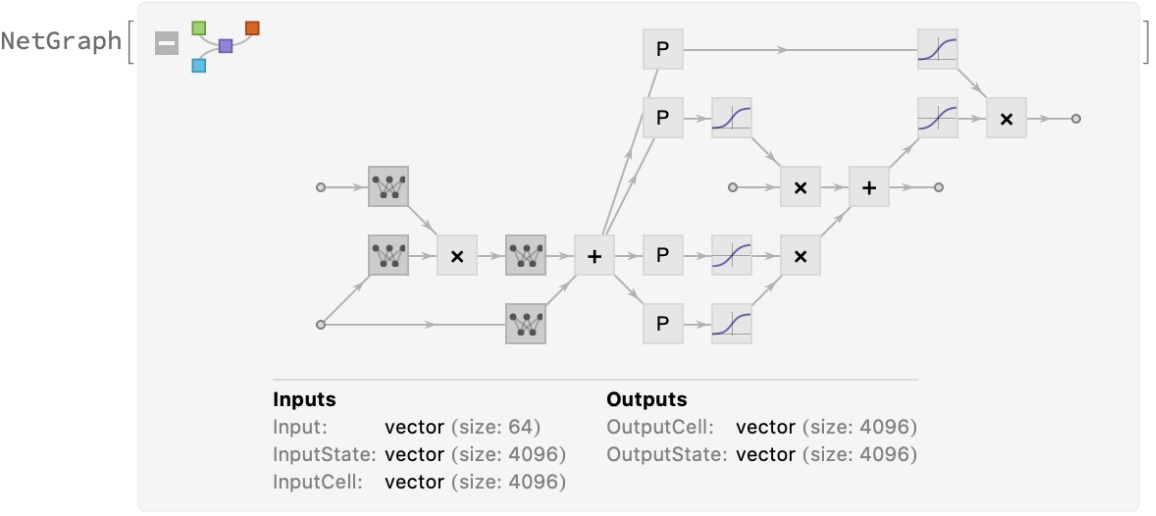
This model features a non-standard multiplicative LSTM (mLSTM), which can be implemented using NetFoldOperator:
Inspect the inner structure of the multiplicative LSTM:
This net encodes its input string into a sequence of byte values corresponding to its UTF-8 encoding. Inspect the input encoder:
The net predicts the next byte of the sequence. UTF-8 allows single byte values in the range 0-247; hence, there are 248 possible outputs. Inspect the input decoder:
Generation
Write a function to generate text efficiently using NetStateObject. Note that FromCharacterCode[…,"UTF-8"] is used at the end, but output byte values are not guaranteed to produce a valid UTF-8 sequence. In this case, FromCharacterCode will issue messages:
Generate for 100 steps using “This produc” as an initial string:
The third optional argument is a “temperature” parameter that scales the input to the final softmax. A high temperature flattens the distribution from which characters are sampled, increasing the probability of extracting less likely characters:
Decreasing the temperature sharpens the peaks of the sampling distribution, further decreasing the probability of extracting less likely characters:
Very low temperature settings are equivalent to always picking the character with maximum probability. It is typical for sampling to “get stuck in a loop”:
Very high temperature settings are equivalent to random sampling. Since the output classes are byte values to be decoded using UTF-8, a very high temperature will almost certainly generate invalid sequences:
Sentiment analysis
In this model, a single unit of the output state (unit #2389) turns out to directly reflect the sentiment of the text. The final value of this unit can be used as a feature for sentiment analysis. Define a function to extract it:
Obtain sentiment scores:
Get a subset of the movie review dataset:
Obtain the review scores. If available, GPU evaluation (TargetDevice -> “GPU”) is recommended:
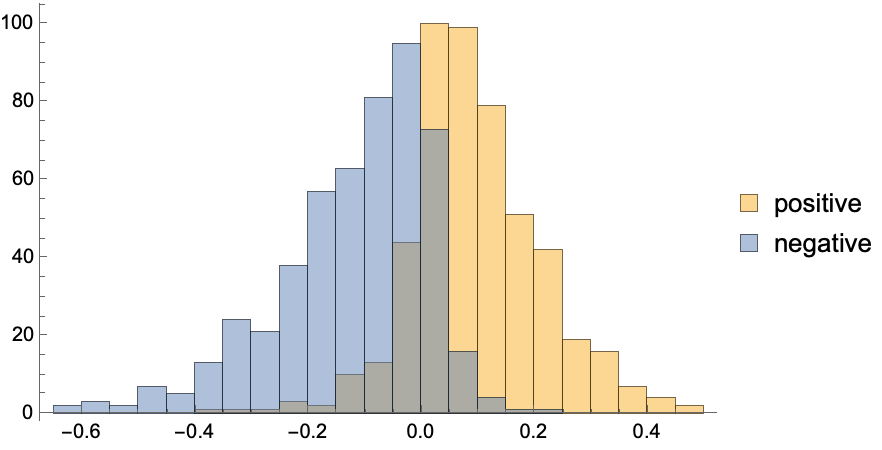
Positive and negative reviews are mostly separated by this single score value:
Classify the reviews using the score:
Keeping in mind that the training used scalar features from a model not explicitly trained for sentiment analysis, the obtained accuracy is remarkable:
Sentiment visualization
Display the evolution of the sentiment cell as the input is read, with red background corresponding to negative sentiment and green to positive:
As the net reads a positive review, the sentiment cell evolves toward values in the positive score range:
As the net reads a negative review, the sentiment cell evolves toward values in the negative score range:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:


![generateSample[start_, len_, temp_ : 1, device_ : "CPU"] := Block[{enc, obj, generated, bytes},
enc = NetExtract[
NetModel[
"Sentiment Language Model Trained on Amazon Product Review Data"], "Input"];
obj = NetStateObject@
NetReplacePart[
NetModel[
"Sentiment Language Model Trained on Amazon Product Review Data"], "Input" -> {"Varying", "Integer"}];
generated = NestList[{obj[#, {"RandomSample", "Temperature" -> temp}]} &, enc[start], len];
bytes = Flatten[generated] - 1;
FromCharacterCode[bytes, "UTF-8"]
]](https://www.wolframcloud.com/obj/resourcesystem/images/3f4/3f47f507-6e4d-47e7-90bb-ab56069c9c11/386b7ffe6e459153.png)





![sentimentScore[text_, device_ : "CPU"] := With[
{output = NetModel[
"Sentiment Language Model Trained on Amazon Product Review Data"][text, NetPort[{"LastState", "Output"}], TargetDevice -> device]},
Switch[Depth[output], 2, output[[2389]], 3, output[[All, 2389]]]
]](https://www.wolframcloud.com/obj/resourcesystem/images/3f4/3f47f507-6e4d-47e7-90bb-ab56069c9c11/6713e6c4149bdfae.png)
![trainData = RandomSample[
ResourceData["Sample Data: Movie Review Sentence Polarity", "TrainingData"], 1000];
testData = RandomSample[
ResourceData["Sample Data: Movie Review Sentence Polarity", "TestData"], 100];](https://www.wolframcloud.com/obj/resourcesystem/images/3f4/3f47f507-6e4d-47e7-90bb-ab56069c9c11/41506ba96cf10de4.png)

![With[{gathered = GatherBy[scoresTrainData, Last]},
Histogram@
MapThread[Legended, {gathered[[All, All, 1]], gathered[[All, 1, 2]]}]
]](https://www.wolframcloud.com/obj/resourcesystem/images/3f4/3f47f507-6e4d-47e7-90bb-ab56069c9c11/294a5474653e1325.png)
![visualizeSentiment[text_String, device_ : "CPU"] := With[
{sentiment = NetModel[
"Sentiment Language Model Trained on Amazon Product Review Data"][text, NetPort[{"mLSTM", "OutputState"}]][[All, 2389]]},
Grid[
{MapThread[
Item[Style[#1, Bold], Background -> Opacity[0.75, #2]] &, {Characters[text], RGBColor[1 - #, #, 0] & /@ Rescale[sentiment, {-0.1, 0.1}, {0, 1}]}]},
ItemSize -> Small
]
]](https://www.wolframcloud.com/obj/resourcesystem/images/3f4/3f47f507-6e4d-47e7-90bb-ab56069c9c11/6cd405a46e1a2348.png)
