Wolfram Neural Net Repository
Immediate Computable Access to Neural Net Models
Represent text as a sequence of vectors
Released in 2024, NuNER v2.0 is a RoBERTa-based transformer encoder designed for entity-centric feature extraction. It addresses the data inefficiency of traditional named entity recognition models by leveraging large-scale LLM-annotated data instead of fully supervised corpora. Trained on a GPT-3.5–annotated subset of the C4 corpus using a contrastive-learning objective, the model outputs contextual token representations (last hidden states) and a pooled sequence embedding, making it suitable for downstream NER and embedding-based retrieval tasks.
Get the pre-trained net:
| In[1]:= |
| Out[1]= | 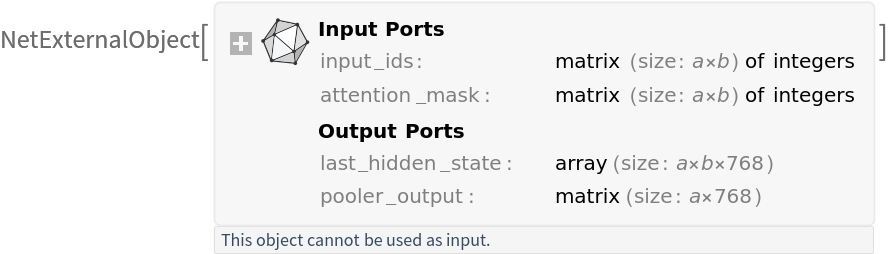 |
Get the tokenizer to process text inputs into tokens:
| In[2]:= |
| Out[2]= |  |
Write a function that preprocesses a list of input sentences:
| In[3]:= | ![prepareBatch[inputStrings_?ListQ] := Block[
{tokens, attentionMask},
tokens = tokenizer[inputStrings] - 1;
attentionMask = PadRight[ConstantArray[1, Length[#]] & /@ tokens, Automatic];
tokens = PadRight[tokens, Automatic, 1];
<|
"input_ids" -> tokens, "attention_mask" -> attentionMask
|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/01d56f2e2ef4187d.png) |
Write a function that applies mean pooling to the hidden states:
| In[4]:= |
Write a function that returns one of the requested outputs from the NuNER-V2 encoder (full output, last hidden state, CLS pooling or mean pooling) and optionally trims padding tokens using attention_mask when the optional parameter "ApplyMask" is set True:
| In[5]:= | ![Options[netevaluate] = {"ApplyMask" -> False}; netevaluate[input_?StringQ, output_String : "MeanPooling", opts : OptionsPattern[]] := If[output === All, netevaluate[{input}, output, opts], First@netevaluate[{input}, output, opts]];
netevaluate[inputStrings_?ListQ, output_String : "MeanPooling" , opts : OptionsPattern[]] := Module[
{assoc, out, h, mask, pooled},
assoc = prepareBatch[inputStrings];
mask = assoc["attention_mask"];
out = NetModel["NuNER-V2 Text Feature Extractor"][assoc];
Switch[output,
All,
out, "LastHiddenState",
h = out["last_hidden_state"];
If[TrueQ@OptionValue["ApplyMask"], MapThread[Take, {h, Total /@ mask}], h], "ClassPooling",
out["pooler_output"], "MeanPooling",
h = out["last_hidden_state"];
pooled = meanPooler[h, mask];
Normalize /@ pooled,
_,
out
]
];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/229b28b49c3b7584.png) |
Get the sentence embedding:
| In[6]:= |
Get the dimensions of the output:
| In[7]:= |
| Out[7]= |
Get the sentences:
| In[8]:= |  |
Get the sentence embeddings using "ClassPooling":
| In[9]:= |
Get the dimensions of the output:
| In[10]:= |
| Out[10]= |
Preprocess a batch of sentences into inputs expected by the model. The result is an association:
• "input_ids": integer token indices
• "attention_mask": a binary mask indicating valid tokens vs. padding tokens
| In[11]:= |
Get the dimensions of the preprocessed sentences:
| In[12]:= |
| Out[12]= |
Visualize the preprocessed sentences:
| In[13]:= |
| Out[13]= |
Get the sentence embeddings:
| In[14]:= |
Get the dimensions of the outputs:
| In[15]:= |
| Out[15]= |
Visualize the first sentence embedding:
| In[16]:= |
| Out[16]= | 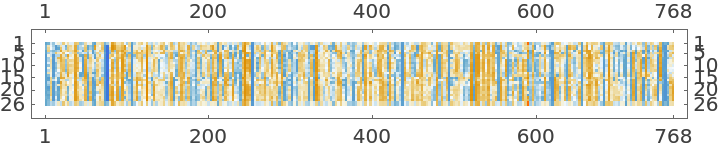 |
The sentence embedding is the normalized average of all non-padded token representations:
| In[17]:= |
| Out[17]= |
Get the sentences:
| In[18]:= |  |
Get the embeddings of the sentences by taking the mean of the features of the tokens for each sentence:
| In[19]:= |
Visualize the embeddings:
| In[20]:= | ![FeatureSpacePlot[AssociationThread[sentences -> embeddings], LabelingFunction -> Callout, ImageSize -> Large]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/30273cf002cfbc8b.png) |
| Out[20]= | 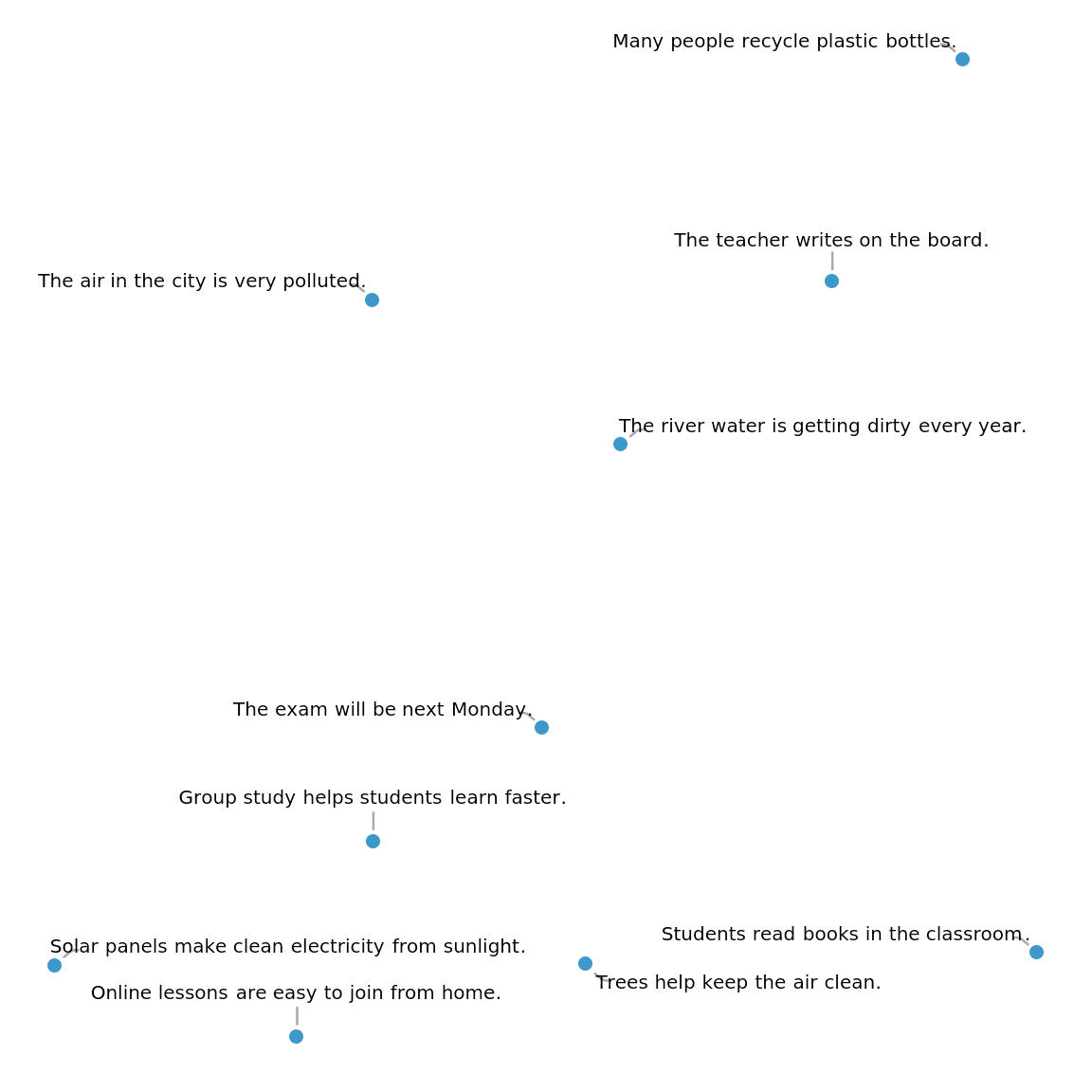 |
Get a list of classes with one example sentence for each:
| In[21]:= |  |
Get a set of sentences to classify and their correct labels:
| In[22]:= |  |
Get the embeddings of the labels and test sentences:
| In[23]:= |
Get the predictions. Since all of the embeddings are normalized, SquaredEuclideanDistance, which is equivalent (up to a constant factor) to cosine distance, is used here:
| In[24]:= | ![results = Flatten@Nearest[Thread[labelEmb -> Values@labelSentences], DistanceFunction -> SquaredEuclideanDistance][inputEmb];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/4900efee401e07cc.png) |
Create a table to visualize the correct and predicted label for each sentence:
| In[25]:= | ![Grid[Prepend[
Transpose[{Keys@testSentences, Values@testSentences, results}], {"Text", "True Label", "Predicted Label"}], Frame -> All, Background -> {None, {LightGray}}, Alignment -> Left]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/2a9f40c3052668a6.png) |
| Out[25]= |  |
Get a sample of sentences:
| In[26]:= | ![movieData = {"The movie received great reviews from critics and audiences.", "The actor delivered an outstanding performance in the film.", "The director created a powerful story with deep emotions.", "The soundtrack perfectly matched the tone of the movie.", "Critics praised the movie for its realistic characters.", "The new film attracted millions of viewers worldwide.", "The main character faced many challenges in the plot.", "The audience applauded at the end of the movie.", "The film\[CloseCurlyQuote]s trailer got millions of views in one day.", "The team celebrated their victory in the final match.", "A new smartphone model was released with advanced features.", "The weather forecast predicts heavy rain for the weekend.", "Students are preparing for their final exams this month." };](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/61720d4909c5e8d9.png) |
Get the embeddings:
| In[27]:= |
Calculate the distance of each sentence embedding from the median embedding to measure how far each one is semantically:
| In[28]:= | ![distance = DistanceMatrix[movieEmb, {Median[movieEmb]}, DistanceFunction -> SquaredEuclideanDistance][[All, 1]]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/7ac7d3ab5232ec0c.png) |
| Out[28]= |
Compute a threshold based on the median and interquartile range to detect sentences that are semantic outliers:
| In[29]:= |
| Out[29]= |
Find the indices for which the distance is greater than the threshold:
| In[30]:= |
| Out[31]= |
Get the outliers:
| In[32]:= |
| Out[32]= |  |
Perform binary sentiment analysis on the SST-2 dataset, where each input sentence is classified as expressing either negative or positive sentiment. The original dataset labels are 0 for negative sentiment and 1 for positive sentiment. Texts are encoded using NuNER-V2 text feature extractor sentence embeddings, and a simple classifier is trained on top of these embeddings.
Get the dataset:
| In[33]:= |
| Out[33]= |  |
Preprocess the dataset:
| In[34]:= | ![i = 0; Monitor[
encodeddata = TransformColumns[data, "Input" -> Function[i++; netevaluate[#Sentence, "ClassPooling"]]], ProgressIndicator[i/Length[data]]]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/5194047c8c6e223d.png) |
| Out[34]= |  |
Define the classifier model for sentiment analysis, which accepts the embeddings as an input and outputs the probabilities for each class (positive, negative):
| In[35]:= |
| Out[36]= |
Extract the training datasets from the initial data:
| In[37]:= |
Train the classifier:
| In[38]:= |
| Out[38]= |
Run the classifier on the embeddings obtained by the NuNER model using test sentences and categorize the results into true positive (TP), true negative (TN), false positive (FP) and false negative (FN):
| In[39]:= | ![resultsData = TransformColumns[testData, "Prediction" -> Function[trainedClassifier[#Input]]] // TransformColumns[{
"TP" -> (Boole[#Output == 1 && #Prediction == #Output] &),
"TN" -> (Boole[#Output == 0 && #Prediction == #Output] &),
"FP" -> (Boole[#Output == 0 && #Prediction != #Output] &),
"FN" -> (Boole[#Output == 1 && #Prediction != #Output] &)
}]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/7d64a14b7bc7cdb7.png) |
| Out[39]= | 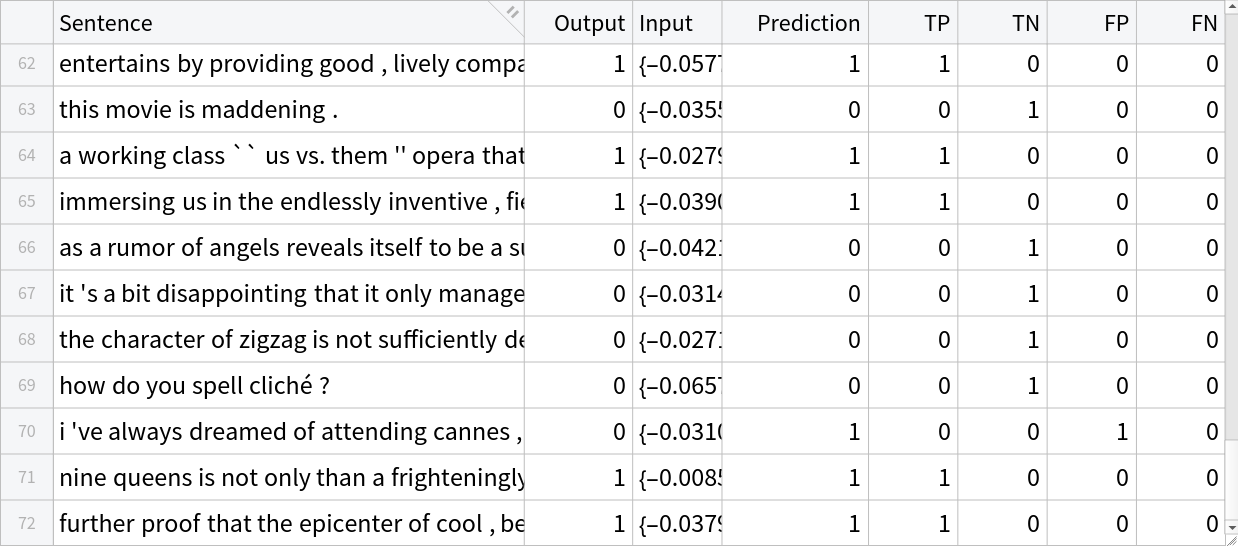 |
Compute the precision, recall and "F1Score":
| In[40]:= | ![AggregateRows[resultsData, {
"Precision" -> Function[N@Total[#TP]/(Total[#TP] + Total[#FP])],
"Recall" -> Function[N@Total[#TP]/(Total[#TP] + Total[#FN])]}] // TransformColumns[
"F1Score" -> Function[2 #Precision*#Recall/(#Precision + #Recall)]]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/109b83d8ddae1a1f.png) |
| Out[40]= |
Create a unified pipeline by merging the classifier and NuNER-V2:
| In[41]:= | ![sentimentModel = NetReplacePart[
trainedClassifier, {"Input" -> NetEncoder[{"Function", netevaluate[#, "ClassPooling"] &, 768, SaveDefinitions -> False}], "Output" -> NetDecoder[{"Class", {"Negative", "Positive"}}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/0344c8c98e0e747d.png) |
| Out[41]= |
Show the results:
| In[42]:= |  |
| Out[42]= |
Perform named entity recognition (NER), where each token in a sentence is assigned a label indicating whether it belongs to an entity such as a person, organization or location. The dataset provides tokenized text along with token-level NER tags, which are expanded to align with the sub-word tokenization used by the model. Sentences are encoded using NuNER, and the last hidden states are used to predict an entity label for each sub-token. This allows the model to identify and classify named entities at the token level.
Get the dataset:
| In[43]:= |
| Out[43]= | 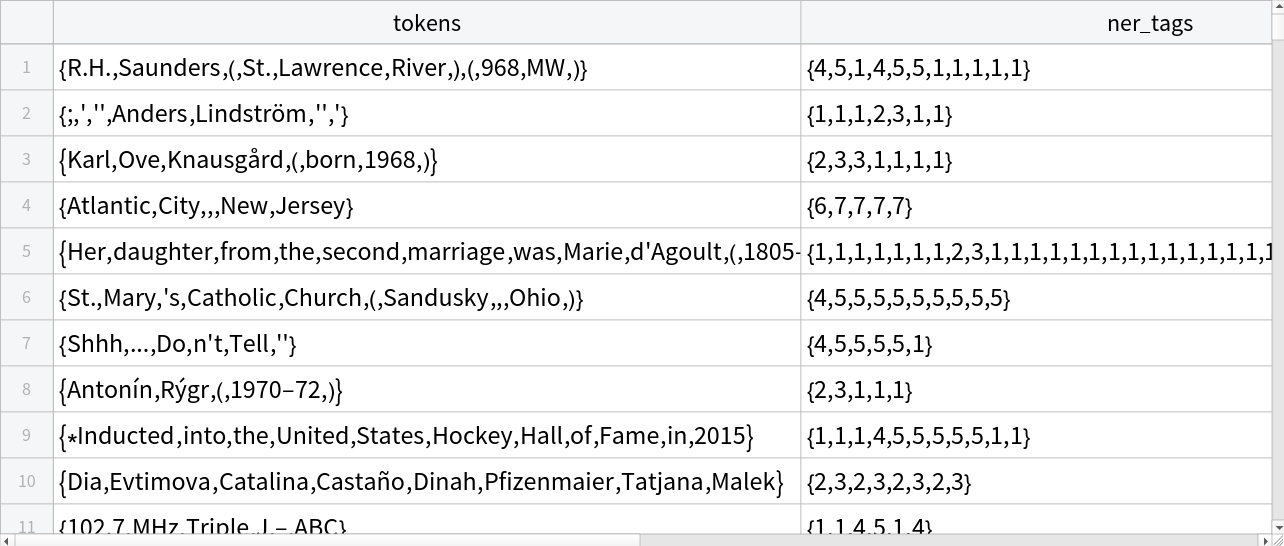 |
Write a function to make the label tags compatible with our sub-words tokenized setup by expanding each word’s tag to its sub-words:
| In[44]:= | ![wrdTokCount[word_, isFirst_, bos_, eos_] := Module[{s, ids},
s = If[isFirst, word, " " <> word];
ids = First@prepareBatch[{s}]["input_ids"];
If[Length[ids] > 0 && First[ids] === bos, ids = Rest[ids]];
If[Length[ids] > 0 && Last[ids] === eos, ids = Most[ids]];
Length@ids
];
expandTags[words_, tags_] := Module[{counts, expanded, bos, eos},
bos = 0;
eos = 2;
counts = MapIndexed[wrdTokCount[#1, First[#2] == 1, bos, eos] &, words];
expanded = Flatten@MapThread[ConstantArray, {tags, counts}];
Join[{1}, expanded, {1}] ];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/670b4fa0fb83385b.png) |
Preprocess the dataset by making tokens a whole sentence, getting the last hidden states and expand the tokens to sub-tokens:
| In[45]:= | ![rowToText[row_] := StringRiffle[row["tokens"], " "];
i = 0;
nerData = Monitor[TransformColumns[
data, {"text" -> rowToText, "Input" -> Function[i++;
netevaluate[rowToText[#], "LastHiddenState", "ApplyMask" -> True]], "Output" -> Function[expandTags[#["tokens"], #["ner_tags"]]]}], ProgressIndicator[i/Length[data]]]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/290b6ccde820352e.png) |
| Out[10]= |  |
Extract the training datasets from preprocessed data:
| In[46]:= |
Define the token classification model:
| In[47]:= |
| Out[48]= |
Train the model:
| In[49]:= | ![headTrained = NetTrain[head, trainData, ValidationSet -> Dataset@validationData, LossFunction -> CrossEntropyLossLayer["Index"], BatchSize -> 128, MaxTrainingRounds -> 1024];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/0a574e616cb15691.png) |
Write a function that will compute the confusion matrix components (TP, FP and FN) according to the NuNER-paper microF1 metric. NER is evaluated at the entity-span level. Labels use the 1-to-7 index range. Each label sequence is first converted into spans (type, start and end) using BIO rules, starting at B (begin) and extending through consecutive I (inside) of the same type. TP counts exact span matches (same type and boundaries), FP counts predicted spans not present in gold and FN counts gold spans not predicted:
| In[50]:= | ![tagType[id_] := Which[id == 2 || id == 3, "PER", id == 4 || id == 5, "ORG", id == 6 || id == 7, "LOC", True, "O"];
tagBIO[id_] := Which[id == 2 || id == 4 || id == 6, "B", id == 3 || id == 5 || id == 7, "I", True, "O"];
extractSpans[tags_List] := Module[{spans = {}, i = 1, L = Length[tags], t, bio, start, typ},
While[i <= L, bio = tagBIO[tags[[i]]];
If[bio == "B",
typ = tagType[tags[[i]]];
start = i;
i++;
While[
i <= L && tagBIO[tags[[i]]] == "I" && tagType[tags[[i]]] == typ,
i++];
AppendTo[spans, {typ, start, i - 1}], i++]];
spans
];
microConfusion[preds_List, golds_List] := Module[{pSp, gSp, tp = 0, fp = 0, fn = 0, inter}, Do[pSp = extractSpans[preds[[k]]];
gSp = extractSpans[golds[[k]]];
inter = Intersection[pSp, gSp];
tp += Length@inter;
fp += Length@Complement[pSp, gSp];
fn += Length@Complement[gSp, pSp];, {k, Length@preds}];
<|"TP" -> tp, "FP" -> fp, "FN" -> fn|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/0854209708083b17.png) |
Write a function that will compute the confusion matrix components (TP, FP and FN) per token. Labels are first mapped to entity types, PER (person), ORG (organization), LOC (location) and O (outside any named entity), ignoring the B/I distinction, then TP counts matching entity-type tokens, FP counts entity-type predictions not matching gold and FN counts gold entity-type tokens missed by the prediction, summed across all sentences:
| In[51]:= | ![tokenType[predTags_List, goldTags_List] := Module[{p, g, classes = {"PER", "ORG", "LOC"}, tp, fp, fn, prec, rec, f1},
p = tagType /@ predTags;
g = tagType /@ goldTags;
tp = Count[Transpose[{p, g}], {x_, x_} /; MemberQ[classes, x]];
fp = Count[
Transpose[{p, g}], {x_, y_} /; MemberQ[classes, x] && x =!= y];
fn = Count[
Transpose[{p, g}], {x_, y_} /; MemberQ[classes, y] && x =!= y];
<|"TP" -> tp, "FP" -> fp, "FN" -> fn|>
];
tokenConfusion[predTagsAll_List, goldTagsAll_List] := Module[{tp = 0, fp = 0, fn = 0, r},
Do[
r = tokenType[predTagsAll[[i]], goldTagsAll[[i]]];
tp += r["TP"];
fp += r["FP"];
fn += r["FN"];, {i, Length[predTagsAll]}
];
<|"TP" -> tp, "FP" -> fp, "FN" -> fn|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/7678fb58a6eeafdc.png) |
Get the trained model's scores for the test data:
| In[52]:= | ![predTagsFromProbs[p_] := Map[First@Ordering[#, -1] &, p, {1}];
resultsData = TransformColumns[testData, {
"Prediction" -> Function[predTagsFromProbs[headTrained[{#Input}][[1]]]]}] // TransformColumns[{"TP-micro" -> Function[microConfusion[{#Prediction}, {#Output}][["TP"]]], "FP-micro" -> Function[microConfusion[{#Prediction}, {#Output}][["FP"]]], "FN-micro" -> Function[microConfusion[{#Prediction}, {#Output}][["FN"]]],
"TP" -> Function[tokenConfusion[{#Prediction }, {#Output}][["TP"]]],
"FP" -> Function[tokenConfusion[{#Prediction}, {#Output}][["FP"]]],
"FN" -> Function[tokenConfusion[{#Prediction}, {#Output}][["FN"]]]}]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/46bad0312e184252.png) |
| Out[53]= | 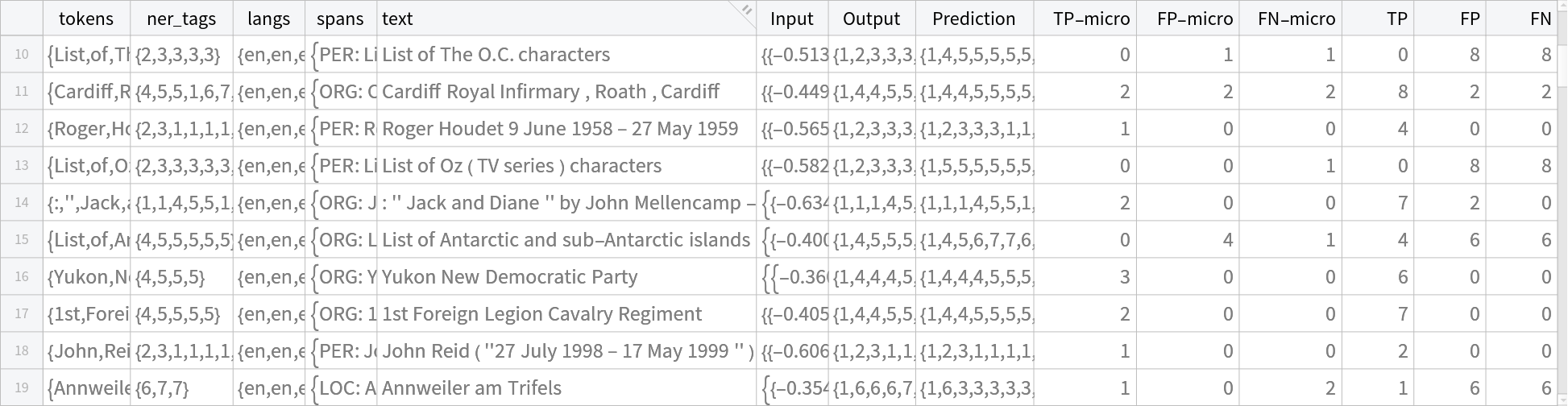 |
Compute precision, recall and "F1Score" using NuNER-defined span-level micro and token-level metrics based on TP, TN, FP and FN:
| In[54]:= | ![AggregateRows[
resultsData, {"Precision-micro" -> Function[
N@Total[#["TP-micro"]]/(Total[#["TP-micro"]] + Total[#["FP-micro"]])],
"Recall-micro" -> Function[
N@Total[#["TP-micro"]]/(Total[#["TP-micro"]] + Total[#["FN-micro"]])],
"Precision" -> Function[N@Total[#["TP"]]/(Total[#["TP"]] + Total[#["FP"]])], "Recall" -> Function[N@Total[#["TP"]]/(Total[#["TP"]] + Total[#["FN"]])]}] // TransformColumns[{"F1Score-micro" -> Function[
2 #["Precision-micro"]*#[
"Recall-micro"]/(#["Precision-micro"] + #["Recall-micro"])], "F1Score" -> Function[2 #["Precision"]*#["Recall"]/(#["Precision"] + #["Recall"])]}]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/126323600761dd33.png) |
| Out[54]= |
Get the whole model, merging the head and NuNER-V2:
| In[55]:= | ![nerModel = NetReplacePart[
headTrained, {"Input" -> NetEncoder[{"Function", netevaluate[#, "LastHiddenState", "ApplyMask" -> True] &, {"Varying", 768}, SaveDefinitions -> False}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/1e8b7e9e7fcc0a46.png) |
| Out[55]= |
Write a wrapper function to convert the nerModel output to human-readable entities:
| In[56]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/310bf339-9835-49cc-ab49-ec6f48862c43"]](https://www.wolframcloud.com/obj/resourcesystem/images/ed9/ed93a2de-7f3d-4273-8543-58c933c621f2/2b9de19d81002062.png) |
Show the results without the wrapper function:
| In[57]:= |
| Out[57]= |  |
Show the results with the wrapper function:
| In[58]:= |
| Out[58]= |