Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
Identify the main action in a video:
Obtain the probabilities of the 10 most likely entities predicted by the net:
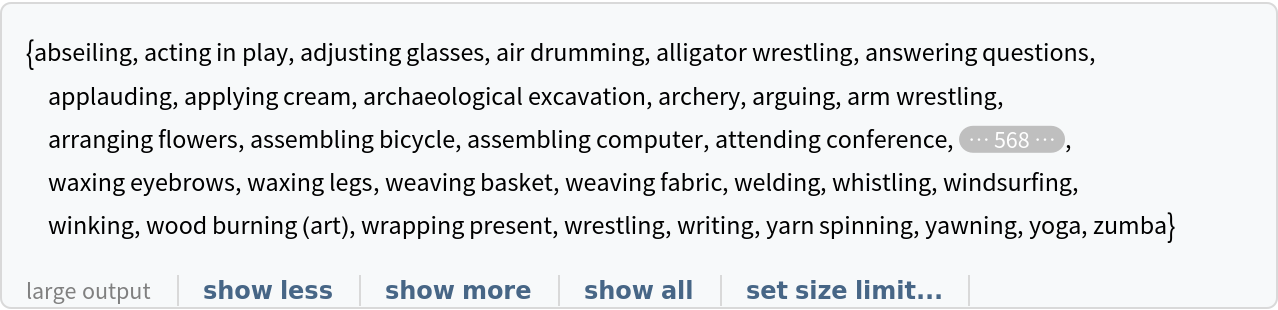
Obtain the list of names of all available classes:
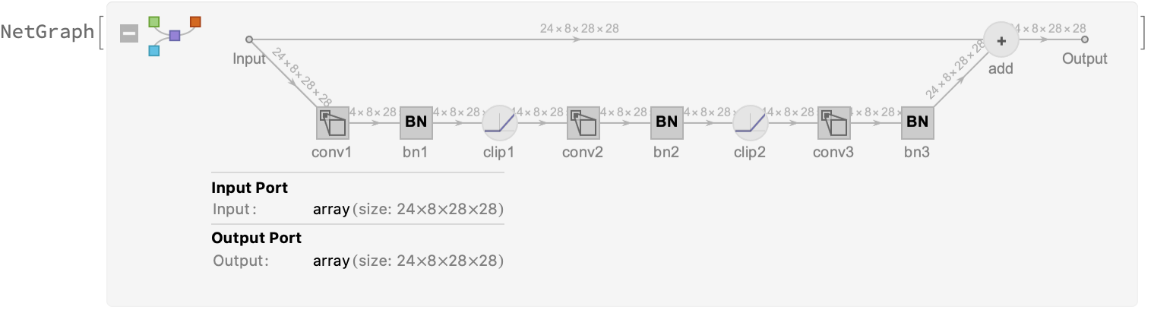
Network architecture
In addition to the depthwise separable convolutions introduced in MobileNet-3D V1, MobileNet-3D V2 models are characterized by inverted residual blocks. In classical residual blocks, the number of channels is decreased and later increased in the convolutional chain (bottleneck), and the residual connection connects feature maps with a large number of channels. On the other hand, inverted residual blocks first increase and then decrease the number of channels (inverted bottleneck), and the residual connection connects feature maps with a small number of channels:
The first convolution layer in this inverted residual block increases the number of channels from 24 to 144:
The last convolution layer decreases the number of channels from 144 back to 24:
Feature extraction
Remove the last layers of the trained net so that the net produces a vector representation of an image:
Get a set of videos:
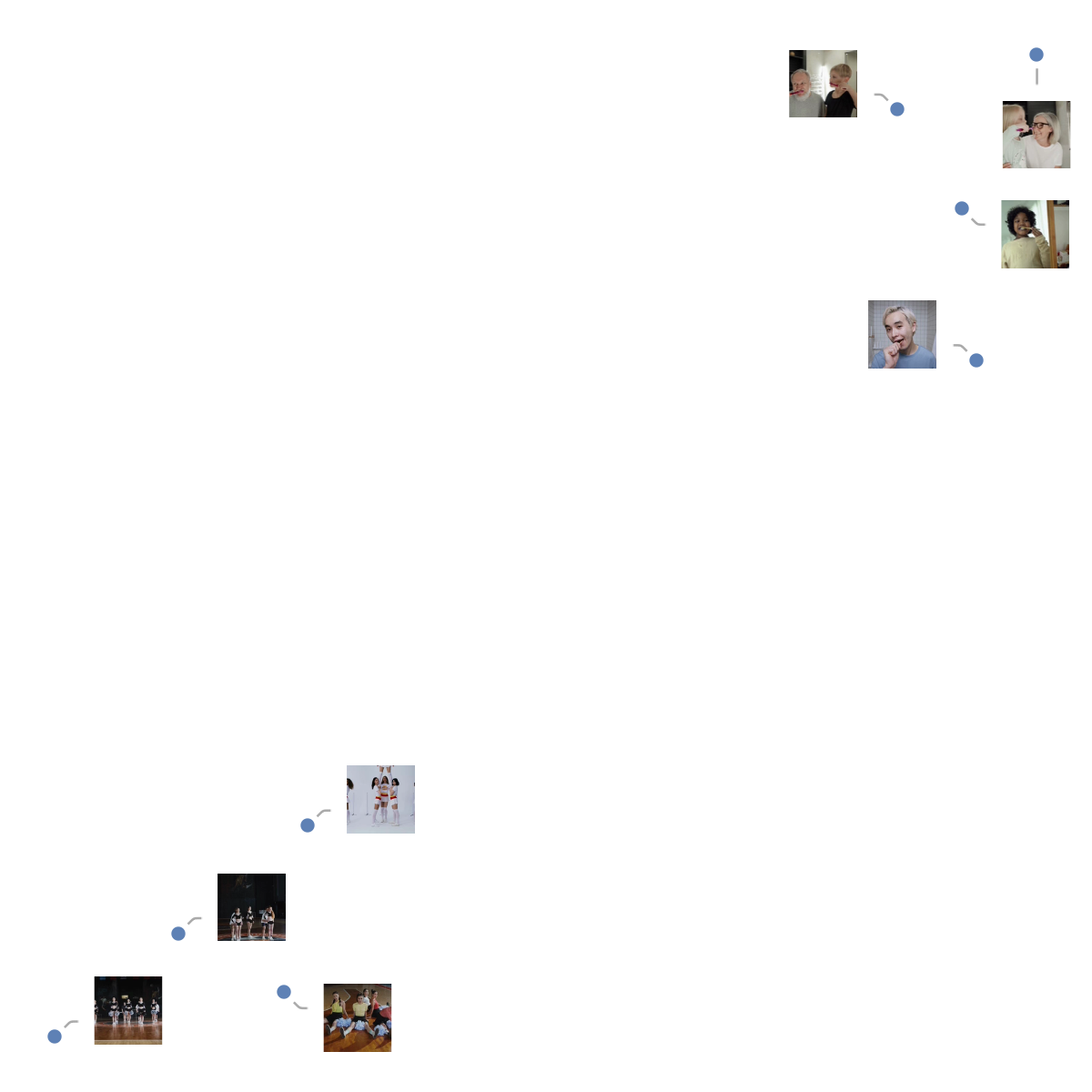
Visualize the features of a set of videos:
Transfer learning
Use the pre-trained model to build a classifier for telling apart images from two action classes not present in the dataset. Create a test set and a training set:
Remove the linear layer from the pre-trained net:
Create a new net composed of the pre-trained net followed by a linear layer and a softmax layer:
Train on the dataset, freezing all the weights except for those in the "Linear" layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
Check some metadata of the ONNX model:
Import the model back into the Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:






![FeatureSpacePlot[videos, FeatureExtractor -> extractor, LabelingFunction -> (Callout[
Thumbnail@VideoExtractFrames[#1, Quantity[1, "Frames"]]] &), LabelingSize -> 50, ImageSize -> 600]](https://www.wolframcloud.com/obj/resourcesystem/images/863/863a0e27-b76c-4f16-8305-c34eca0d8af7/663e406f7e083f6a.png)
![dataset = Join @@ KeyValueMap[
Thread[
VideoSplit[#1, Most@Table[
Quantity[i, "Frames"], {i, 16, Information[#1, "FrameCount"][[1]], 16}]] -> #2] &,
videos
];](https://www.wolframcloud.com/obj/resourcesystem/images/863/863a0e27-b76c-4f16-8305-c34eca0d8af7/77a481c3ae9581fd.png)

