Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Basic usage
Given a piece of text, the GPT net produces a sequence of feature vectors of size 768, which correspond to the sequence of input words or subwords:
Obtain dimensions of the embeddings:
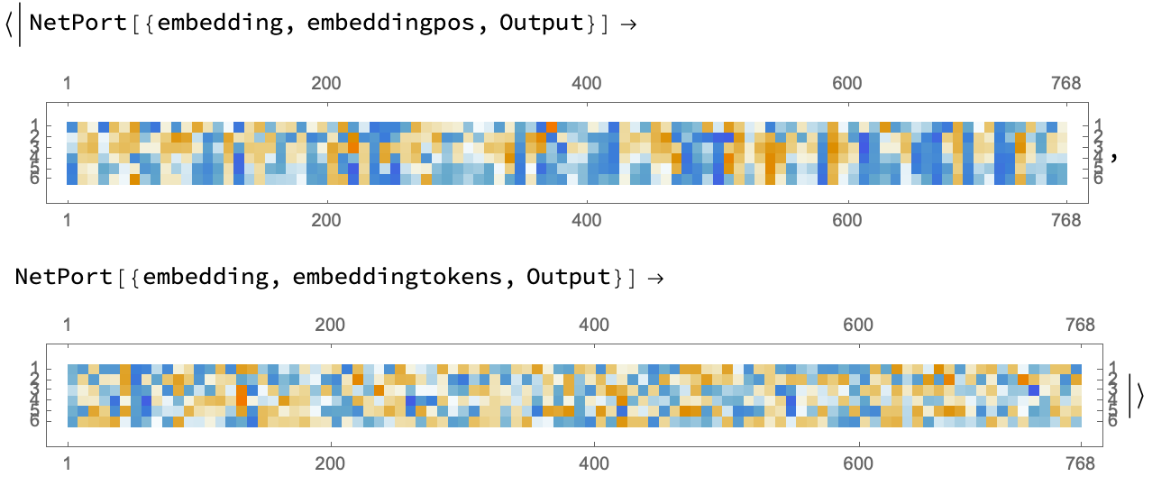
Visualize the embeddings:
Transformer architecture
The input string is first normalized and then tokenized, or split into words or subwords. This two-step process is accomplished using the NetEncoder "Function":
The tokenization step is performed using the NetEncoder "BPESubwordTokens" and can be extracted using the following steps:
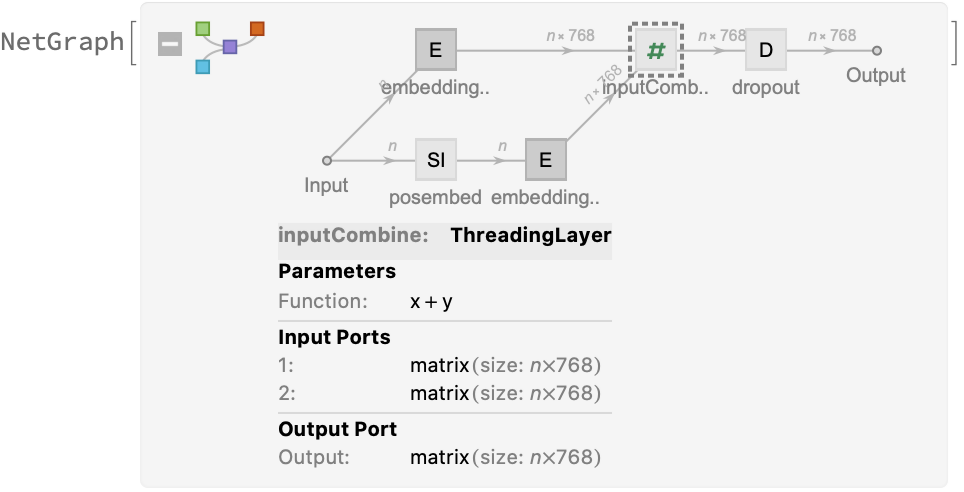
The encoder produces an integer index for each subword token that corresponds to the position in the vocabulary:
Each subword token is also assigned a positional index:
A lookup is done to map these indices to numeric vectors of size 768:
For each subword token, these two embeddings are combined by summing elements with ThreadingLayer:
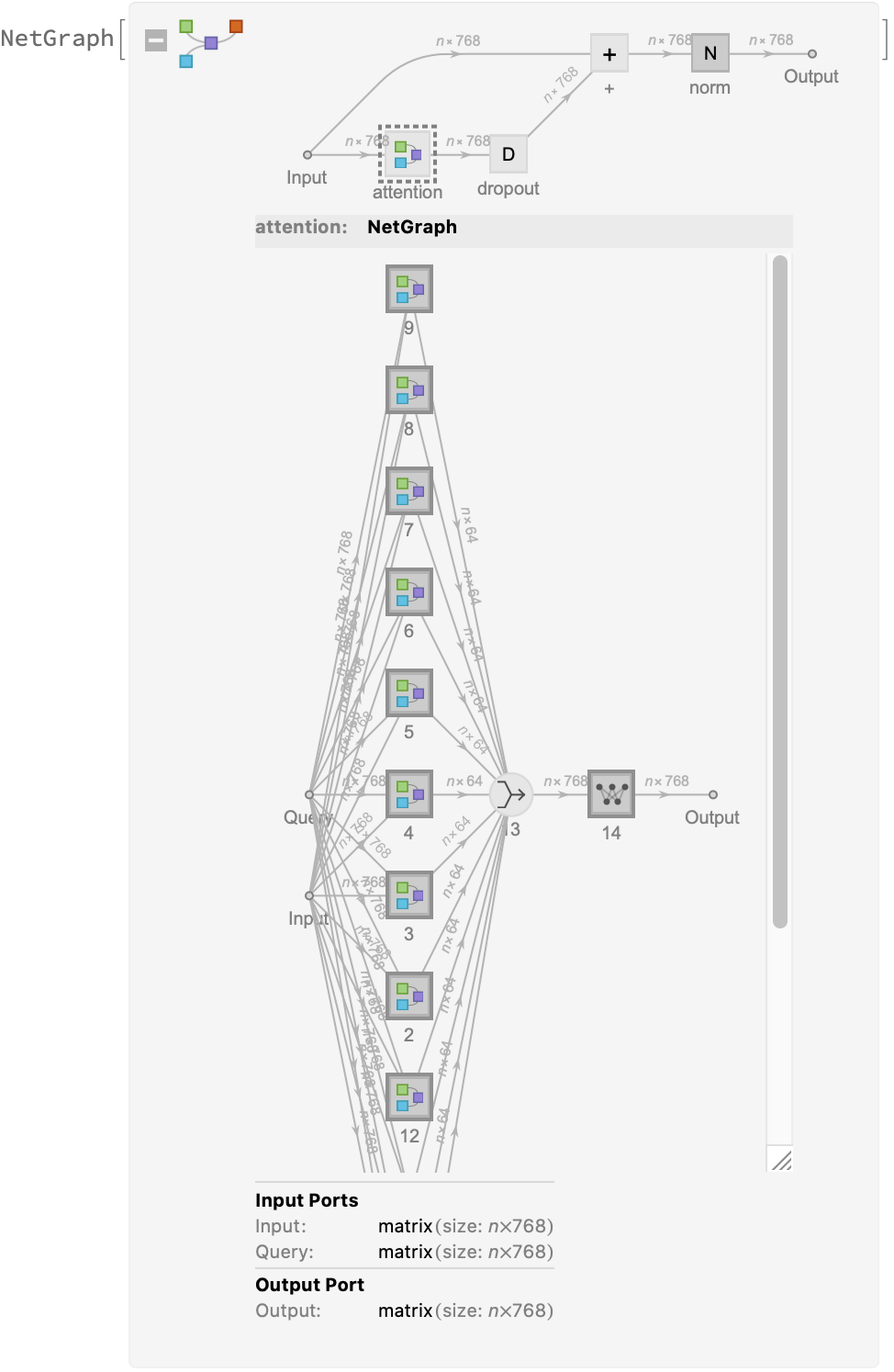
The transformer architecture then processes the vectors using 12 structurally identical self-attention blocks stacked in a chain:
The key part of these blocks is the attention module consisting of 12 parallel self-attention transformations, also called “attention heads”:
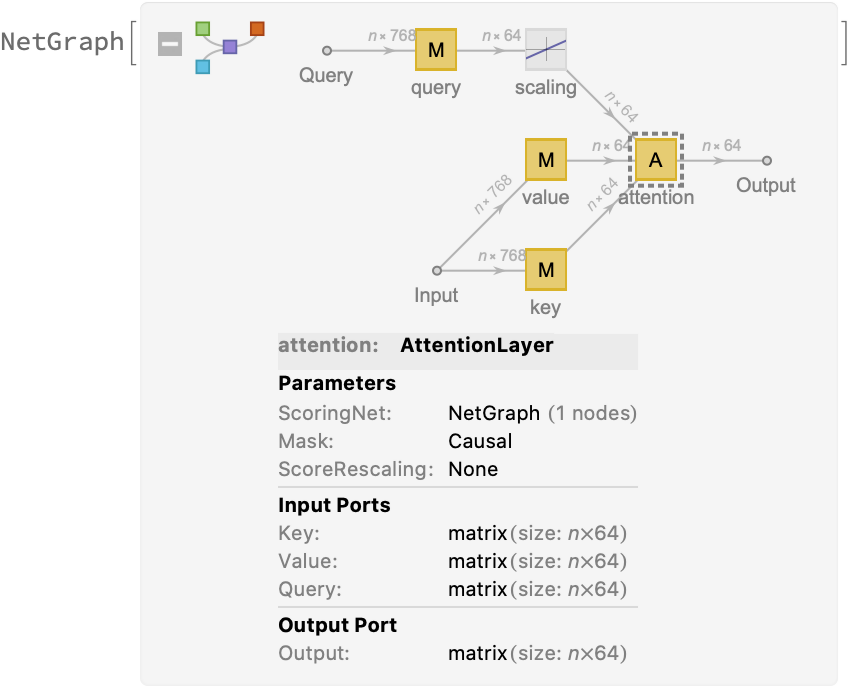
Each head uses an AttentionLayer at its core:
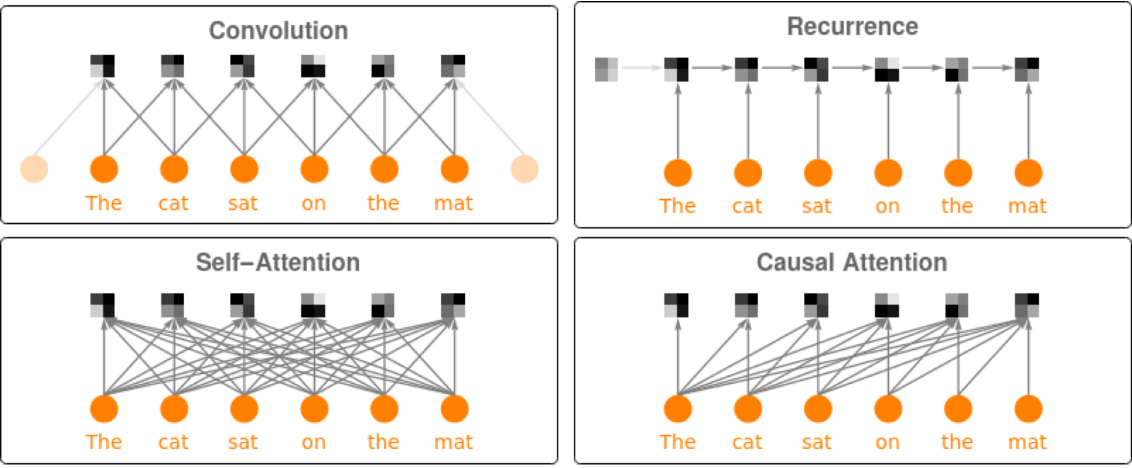
Attention is done with causal masking, which means that the embedding of a given subword token depends on the previous subword tokens and not on the subsequent ones.
This is a prerequisite to be able to generate text with the language model. The following figures compare causal attention to other forms of connectivity between input tokens:
Language modeling: Basic usage
Retrieve the language model by specifying the "Task" parameter:
Predict the next word in a given sequence:
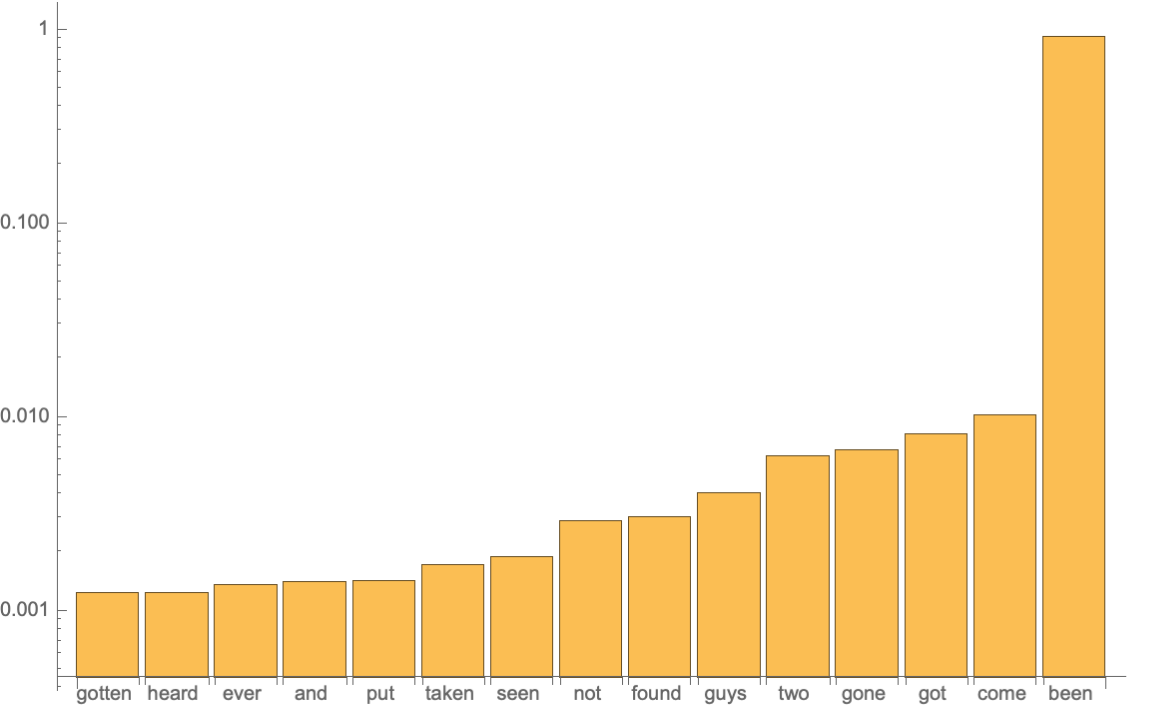
Obtain the top 15 probabilities:
Plot the top 15 probabilities:
Text generation
Modify the language model so that it accepts the encoded token indices as input and creates the token indices as output:
Create a new decoder that performs a lookup to find the corresponding string, followed by some text cleaning:
Define a function to predict the next token using the modified language model:
Get an input:
Generate the next 20 tokens by using it on the input:
The third optional argument is a “temperature” parameter that scales the input to the final softmax. A high temperature flattens the distribution from which tokens are sampled, increasing the probability of extracting less likely tokens:
Decreasing the temperature sharpens the peaks of the sampling distribution, further decreasing the probability of extracting less likely tokens:
Very high temperature settings are equivalent to random sampling:
Very low temperature settings are equivalent to always picking the character with maximum probability. It is typical for sampling to “get stuck in a loop”:
Sentence analogies
Define a sentence embedding that consists of the last subword embedding of GPT (this choice is justified by the fact that GPT is a forward causal model):
Define some sentences in two broad categories for comparison:
Precompute the embeddings for a list of sentences:
Visualize the similarity between the sentences using the net as a feature extractor:
Train a classifier with the subword embeddings
Get a text-processing dataset:
View a random sample of the dataset:
Define a sentence embedding that consists of the last subword embedding of GPT (this choice is justified by the fact that GPT is a forward causal model):
Precompute the GPT vectors for the training and the validation datasets (if available, GPU is highly recommended):
Define a simple network for classification:
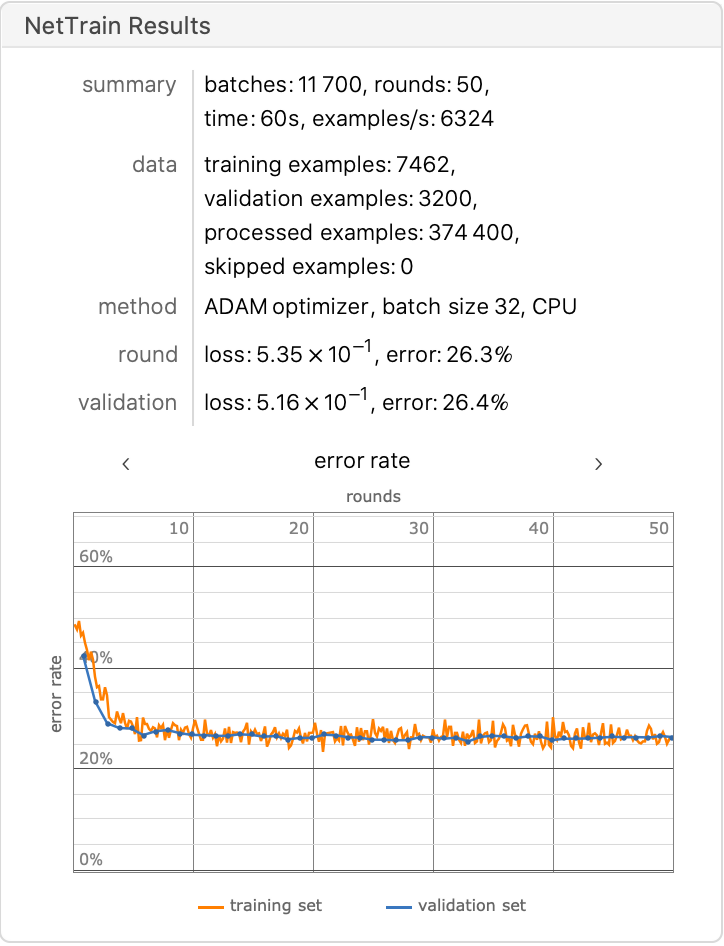
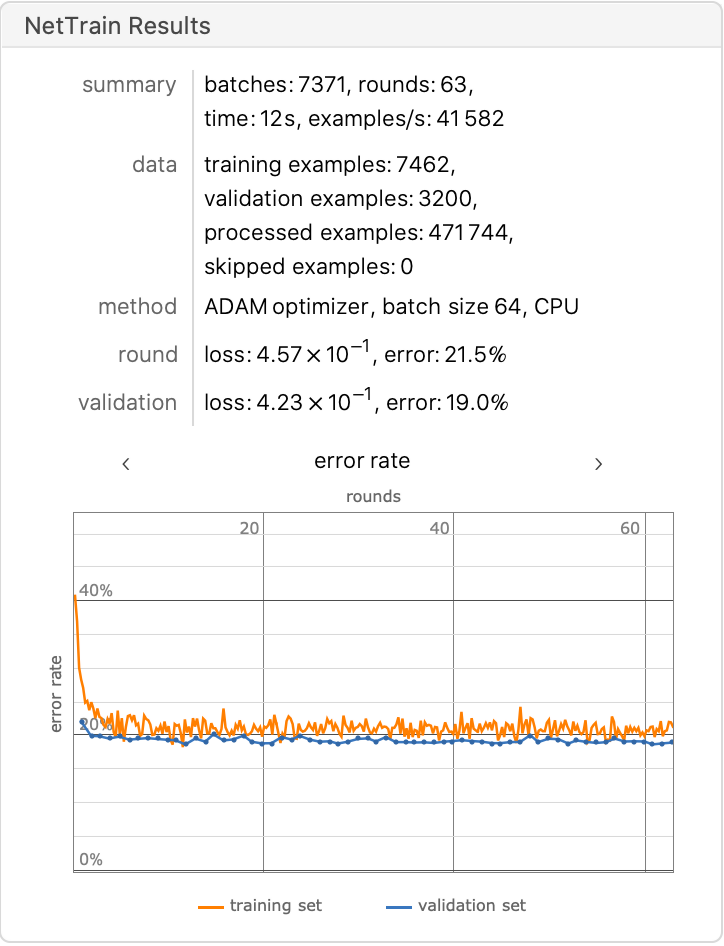
Train the network on the precomputed GPT vectors:
Check the classification error rate on the validation data:
Compare the results with the performance of a classifier trained on context-independent word embeddings. Precompute the GloVe vectors for the training and the validation datasets (if available, GPU is recommended):
Define a simple network for classification, using a max-pooling strategy:
Train the classifier on the precomputed GloVe vectors:
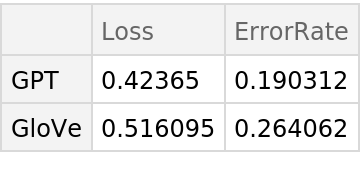
Compare the results obtained with GPT and with GloVe:
Net information
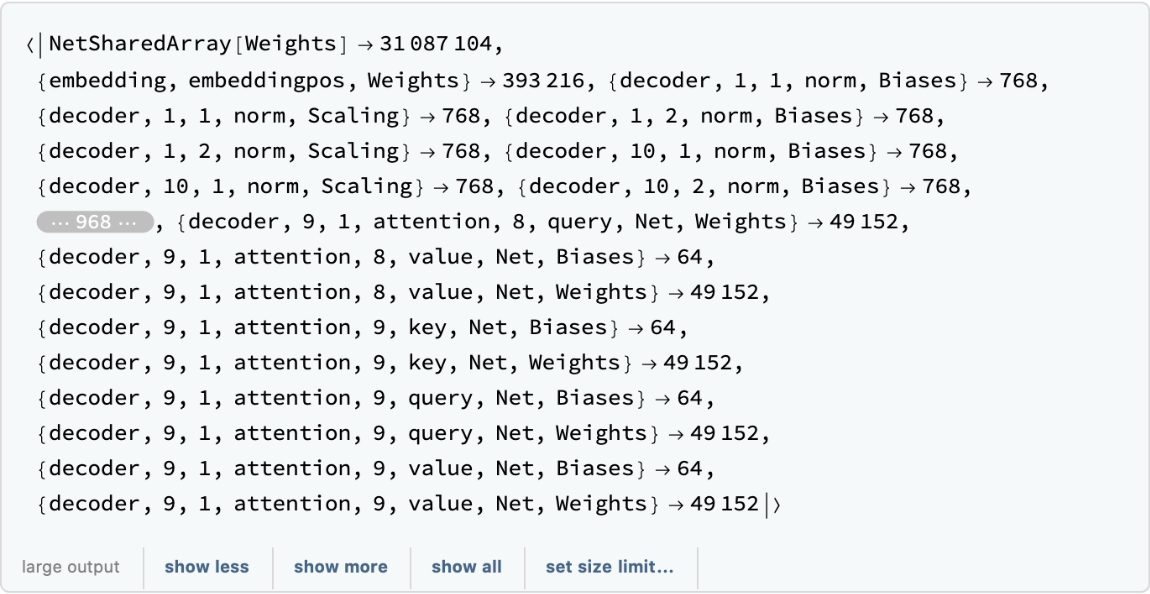
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:







![embeddings = net["Hello world! I am here", {NetPort[{"embedding", "embeddingpos",
"Output"}], NetPort[{"embedding", "embeddingtokens", "Output"}]}];
Map[MatrixPlot, embeddings]](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/23910d5b8f2435e8.png)



![lm = NetModel[{"GPT Transformer Trained on BookCorpus Data", "Task" -> "LanguageModeling"}];
encoder = NetExtract[lm, "Input"];
netdecoder = NetExtract[lm, "Output"];
numwords = NetExtract[netdecoder, "Dimensions"];
languagemodel = NetReplacePart[lm,
{"Input" -> None,
"Output" -> NetDecoder[{"Class", Range@numwords}]}];](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/1457d59a057274c9.png)
![assoc = AssociationThread[
Range@numwords -> NetExtract[netdecoder, "Labels"]];
decoder = Function[array,
StringReplace[
StringJoin@Lookup[assoc, array], {"\n " -> "\n", " " ~~ x : PunctuationCharacter :> x}]];](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/4d04f001a9259067.png)
![generateSample[{lmmodified_, encoder_, decoder_}][input_String, numTokens_ : 10, temperature_ : 1] := Module[{numwords, inputcodes, outputcodes, matrix},
inputcodes = encoder[input];
outputcodes = Nest[Function[
Join[#, {lmmodified[#, {"RandomSample", "Temperature" -> temperature}]}]], inputcodes, numTokens];
decoder[outputcodes]]](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/11f8da3e744f8ab1.png)










![gptresults = NetTrain[classifierhead, trainembeddings, All,
ValidationSet -> validembeddings,
TrainingStoppingCriterion -> <|"Criterion" -> "ErrorRate", "Patience" -> 50|>,
TargetDevice -> "CPU",
MaxTrainingRounds -> 500]](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/58b093ea6a708313.png)
![gloveclassifierhead = NetChain[
{DropoutLayer[],
NetMapOperator[2],
AggregationLayer[Max, 1],
SoftmaxLayer[]},
"Output" -> NetDecoder[{"Class", {"negative", "positive"}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/22a5aa488747e943.png)

![gloveresults = NetTrain[gloveclassifierhead, trainembeddingsglove, All,
ValidationSet -> validembeddingsglove,
TrainingStoppingCriterion -> <|"Criterion" -> "ErrorRate", "Patience" -> 50|>,
TargetDevice -> "CPU",
MaxTrainingRounds -> 50]](https://www.wolframcloud.com/obj/resourcesystem/images/b2a/b2a2f75d-c60c-463a-91b1-bfa5b7f5a8d9/467d5f8688170072.png)