Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Evaluation function
Write an evaluation function:
Basic usage
Define a test image:
Obtain a segmentation mask for the desired object using a textual prompt, a bounding box and a single point:
All the obtained masks are binary and have the dimensions of the input image:
Visualize the mask obtained via the text prompt:
Visualize the box hint and mask obtained from it:
Visualize the point hint and mask obtained from it:
If no hint is specified, binary masks for all the identified objects will be returned:
Visualize the masks:
Prompt-guided selection
When hints are used, the process is split in two phases: all-instance segmentation (where the entire image is segmented into its components) followed by prompt-guided selection (where a final mask is obtained using the prompt). Define an image:
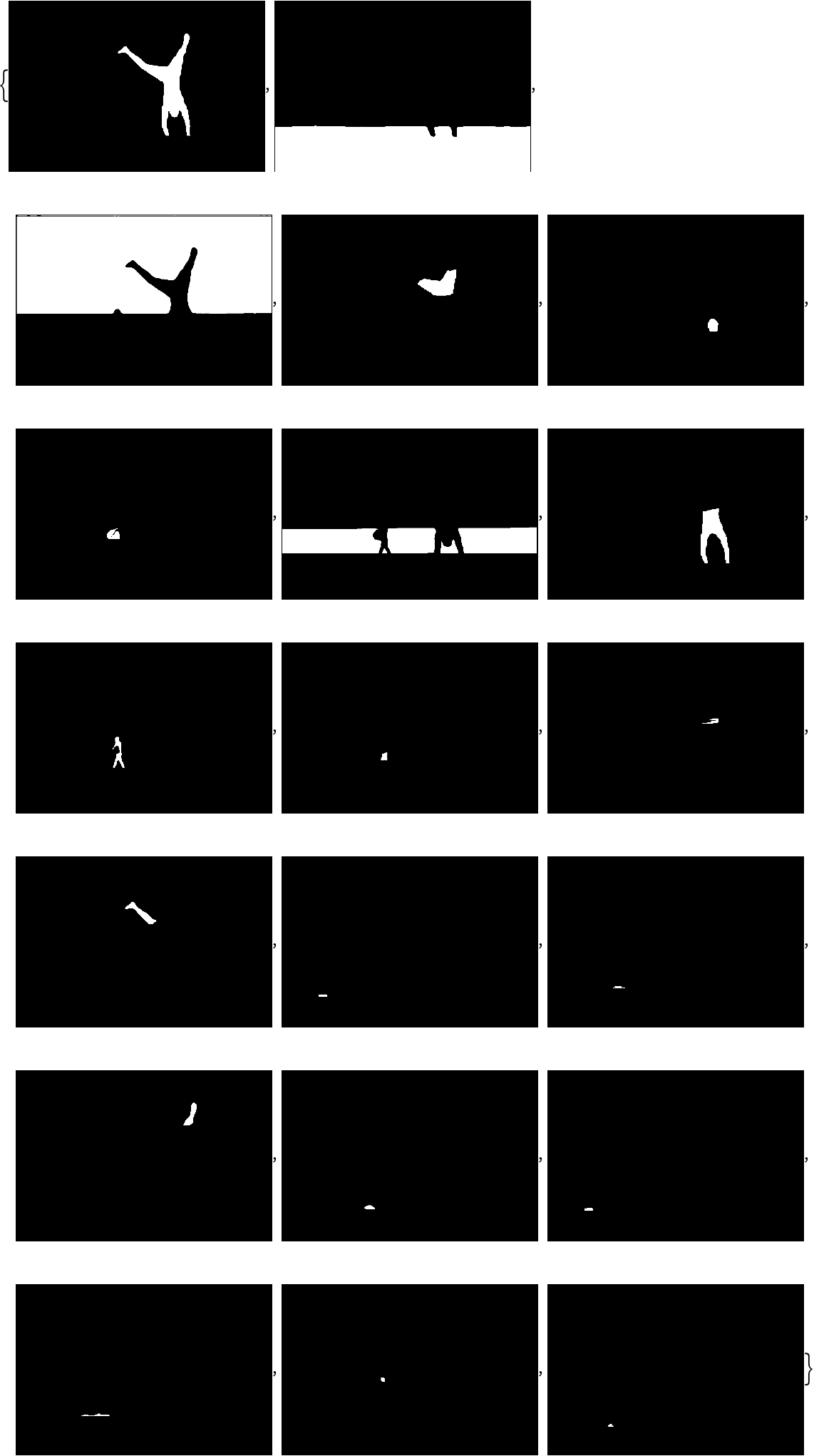
The initial all-instance segmentation follows the pipeline of the model "YOLO V8 Segment Trained on MS-COCO Data." Obtain all the segmentation masks:
Show all the obtained masks on top of the image:
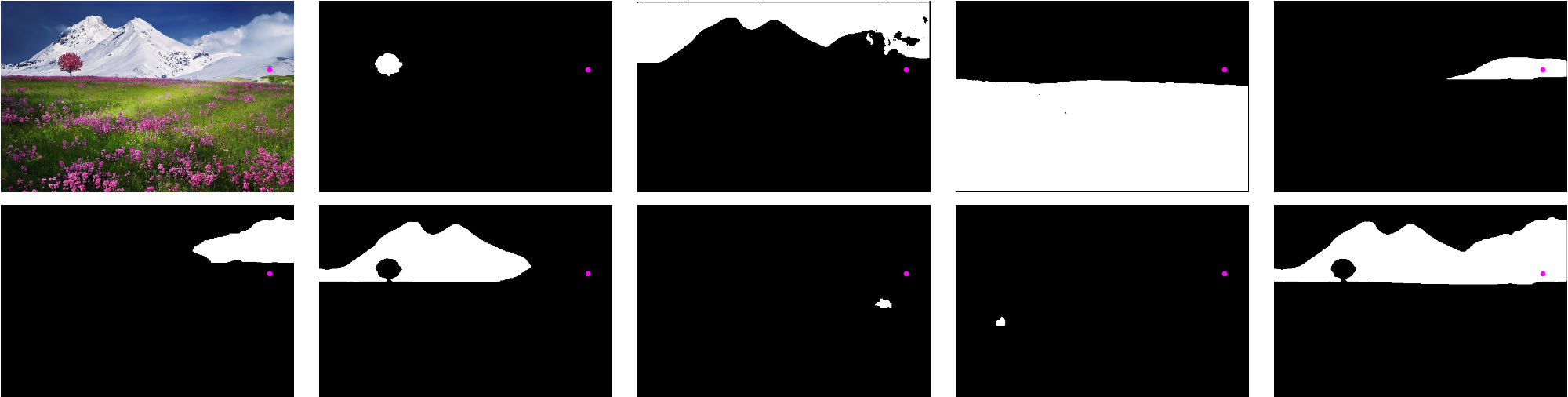
For the case of a point guidance, the final mask is the union of all the masks that contain the point. Show a point hint relative to the image and all of the masks:
Check which masks contain the point:
Take the union of the masks and show the final result:
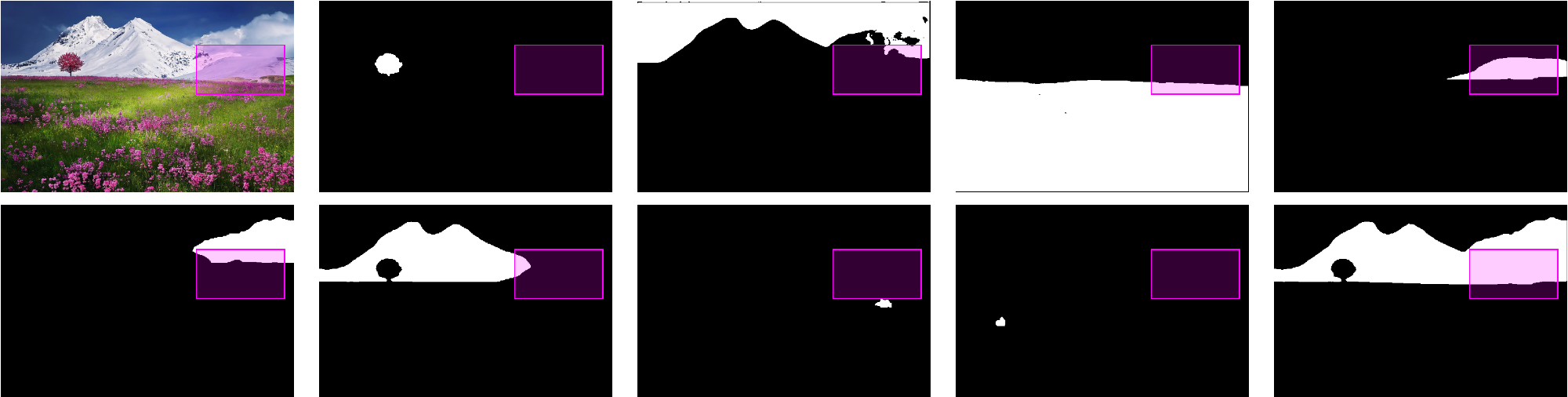
For the case of a box guidance, the final mask is the one with maximal intersection over union (IOU) with the box. Show a box hint relative to the image and all masks:
Obtain the measure of the intersections between the masks and the box:
Obtain the measure of the unions between the masks and the box:
Compute the IOU and select the mask with maximal value:
Show the final result:
For the case of a text guidance, the segmented parts of the image and the text are fed to multi-domain CLIP models, obtaining feature vectors that can be compared. The selected mask is the one closest to the text in feature space. Define a text hint and segment the image in its parts:
Obtain the multi-domain features:
Compute the cosine distances between the features and select the mask with maximal value:
Show the final result:
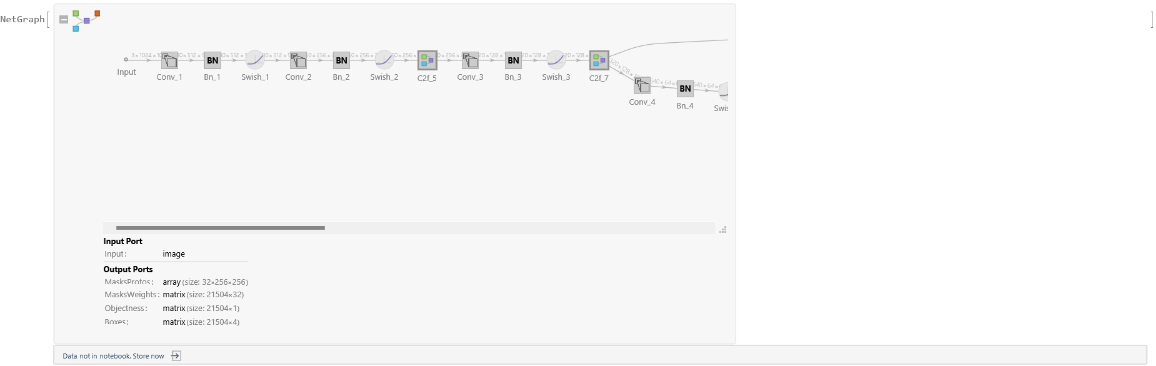
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
The size is similar to the byte count of the resource object:
Check some metadata of the ONNX model:
Import the model back into Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:


![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/1bf64db7-7cba-468f-8429-aedcac281e74"]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/4241566d63c0828d.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/01a72e89-665e-4f78-a61a-fa85d2c4806c"]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/62f014005e7f4e11.png)
![maskText = netevaluate[NetModel["FastSAM Trained on MS-COCO Data"], testImage, "man handstanding"];](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/13925fd1afa8d7b5.png)
![maskBox = netevaluate[NetModel["FastSAM Trained on MS-COCO Data"], testImage, Rectangle[{400, 200}, {480, 360}]];](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/04eedcb898dc4a92.png)
![maskPoint = netevaluate[NetModel["FastSAM Trained on MS-COCO Data"], testImage, Point[{200, 250}]];](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/5a6c27720d88bd40.png)
![{Dimensions[maskText], DeleteDuplicates@Flatten[maskText]}
{Dimensions[maskBox], DeleteDuplicates@Flatten[maskBox]}
{Dimensions[maskPoint], DeleteDuplicates@Flatten[maskPoint]}](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/2a04cf68f1afaa18.png)




![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/7d03fe1a-cc0d-4c0f-bbbf-2fcea1972f68"]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/1125ed1edef7fa22.png)
![HighlightImage[img, Thread[Range[Length[allMasks]] -> Map[{Opacity[0.6], #} &, Image /@ allMasks]], ImageLabels -> None]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/45fed3be4594f5a8.png)

![pointHint = Point[{550, 250}];
GraphicsGrid[
Partition[
HighlightImage[#, pointHint] & /@ Prepend[Image /@ allMasks, img], 5, 5, {1, 1}, ConstantImage[1, ImageDimensions[img]]],
ImageSize -> 1000
]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/4dcbdedb0c0228ba.png)


![boxHint = Rectangle[{400, 200}, {580, 300}];
GraphicsGrid[
Partition[
HighlightImage[#, boxHint] & /@ Prepend[Image /@ allMasks, img], 5],
ImageSize -> 1000
]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/7e6902a884546ad1.png)
![boxArea = Area[boxHint];
masksArea = Total[allMasks, {2, 3}];
union = masksArea + boxArea - intersection](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/715be9a1edad0ee7.png)



![textFeaures = NetModel[{"CLIP Multi-domain Feature Extractor", "InputDomain" -> "Text", "Architecture" -> "ViT-B/32"}][textHint];
Dimensions[textFeaures]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/2d06cbb94a4f8f09.png)
![imgFeatures = NetModel[{"CLIP Multi-domain Feature Extractor", "InputDomain" -> "Image", "Architecture" -> "ViT-B/32"}][
segmentedImgs];
Dimensions[imgFeatures]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/3ea7f3df625d0cf3.png)




![onnxFile = Export[FileNameJoin[{$TemporaryDirectory, "net.onnx"}], NetModel["FastSAM Trained on MS-COCO Data"]]](https://www.wolframcloud.com/obj/resourcesystem/images/447/4474839f-b00a-4f87-8210-b5a6e7a40e87/59247e55dd005449.png)
