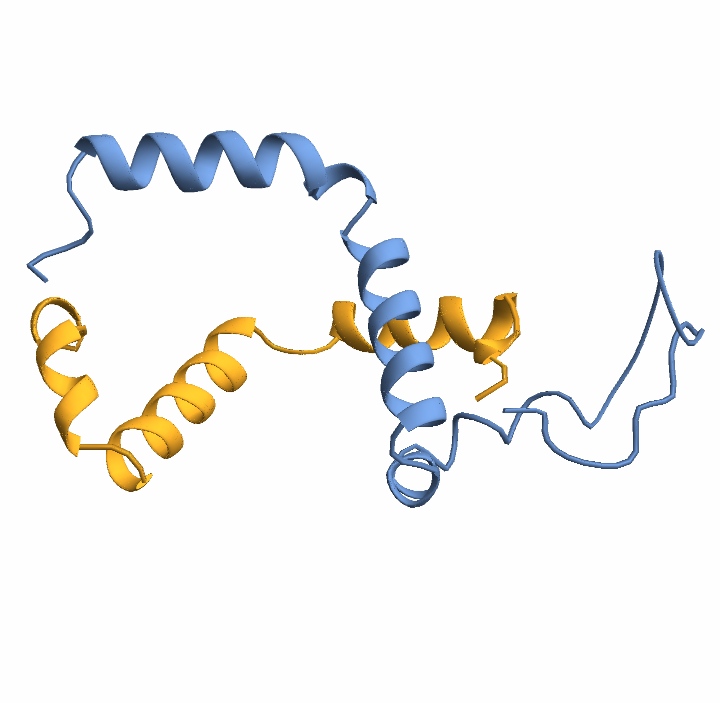
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Feature extraction
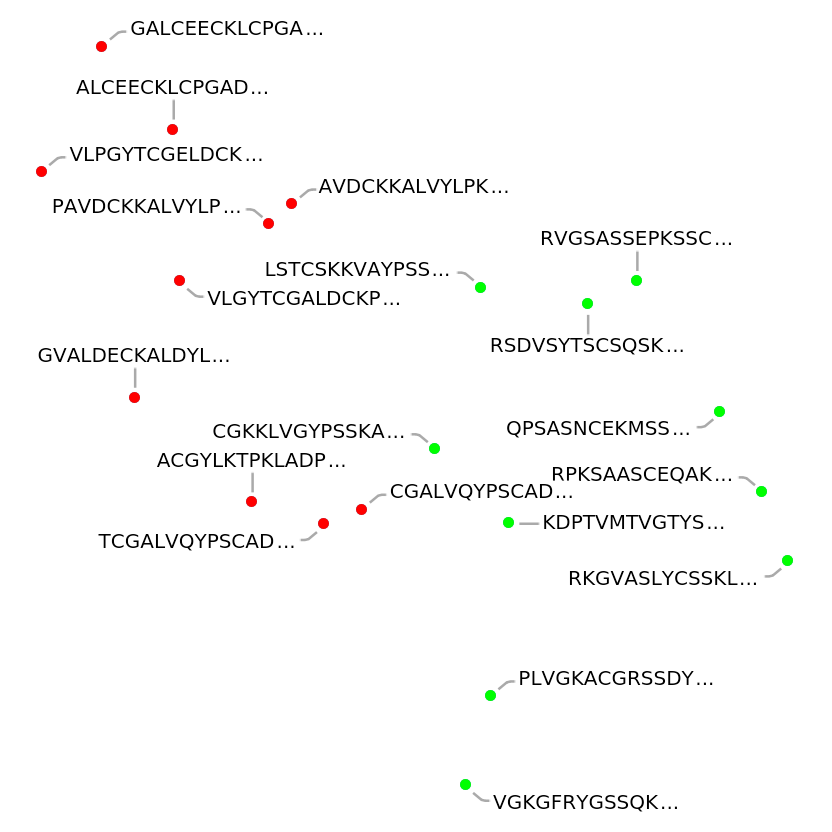
Define two sets of amino acid sequences originating from different protein families, namely enzymes and structural proteins:
Define the feature embeddings extractor using ESMFold:
Visualize the features of the protein sequences:
Advanced usage
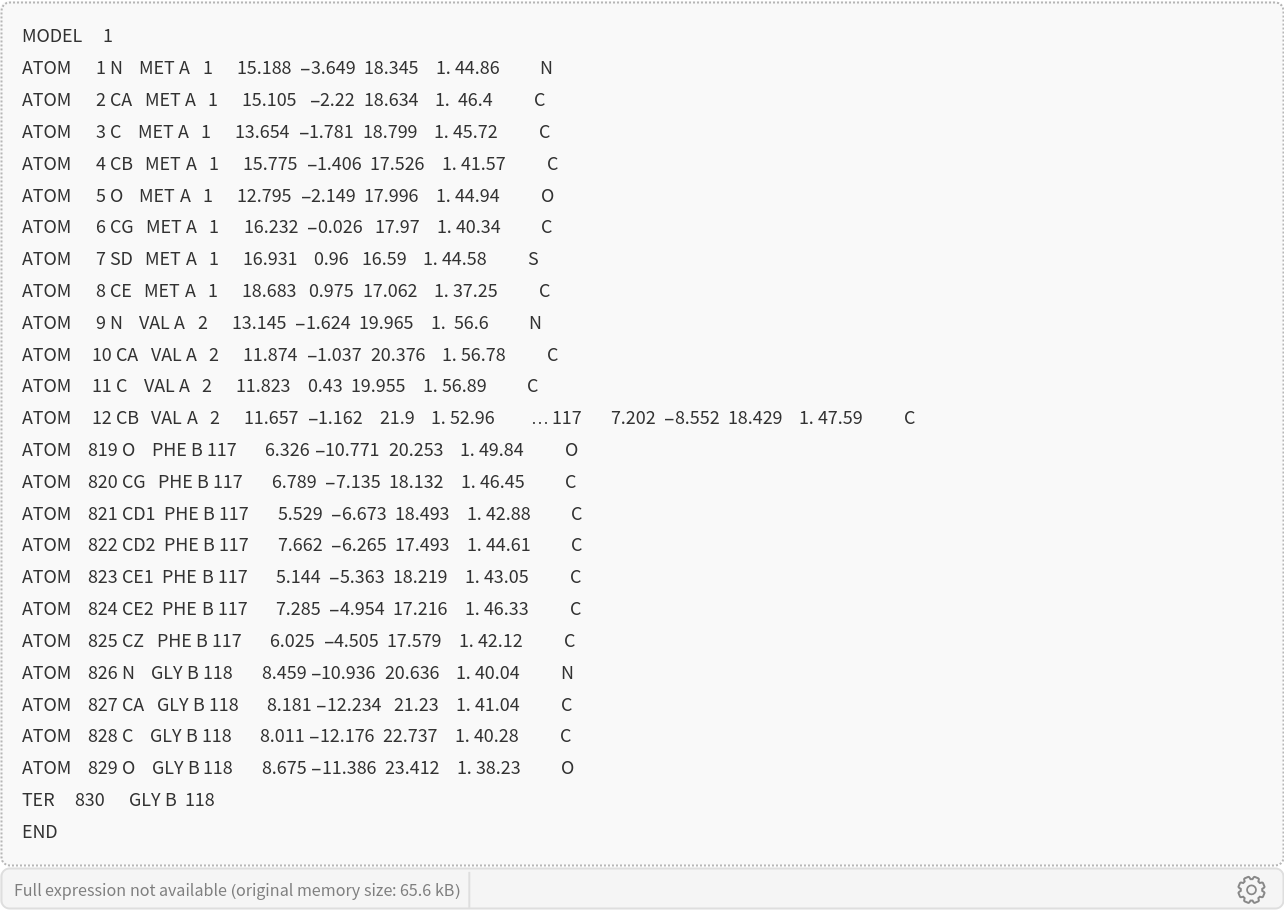
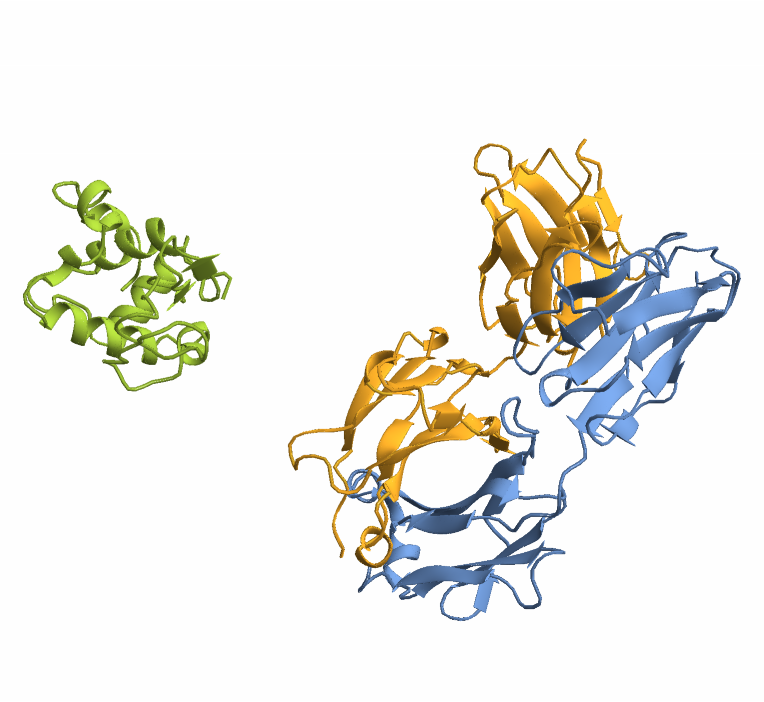
When working with proteins composed of multiple chains (multimers), a glycine linker (commonly 25 residues long) is automatically inserted between chains to create a single continuous sequence suitable for structure prediction. Glycine is typically chosen due to its small size and minimal structural impact. To demonstrate this, we’ll use the antibody 3HFM, which consists of three chains:
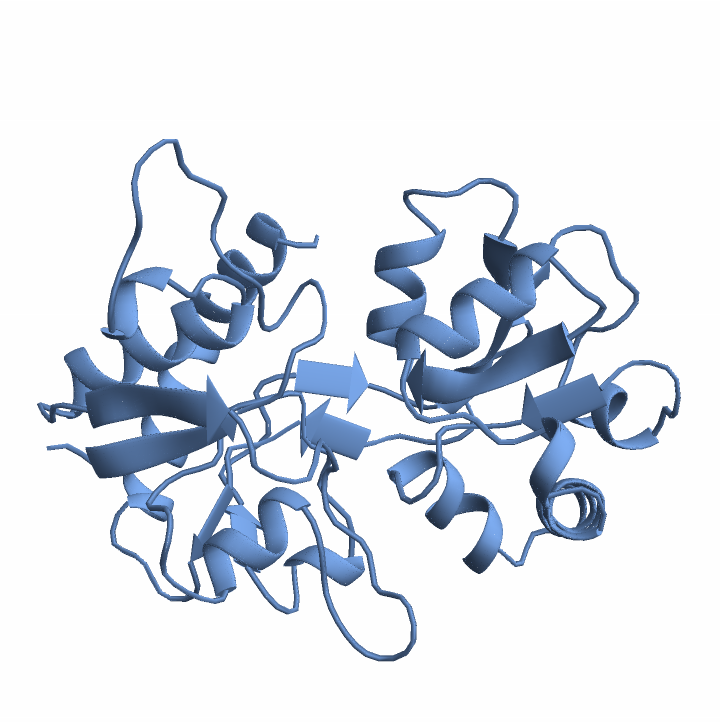
Get the predicted structure and confidence score:
Visualize the structure:
Network result
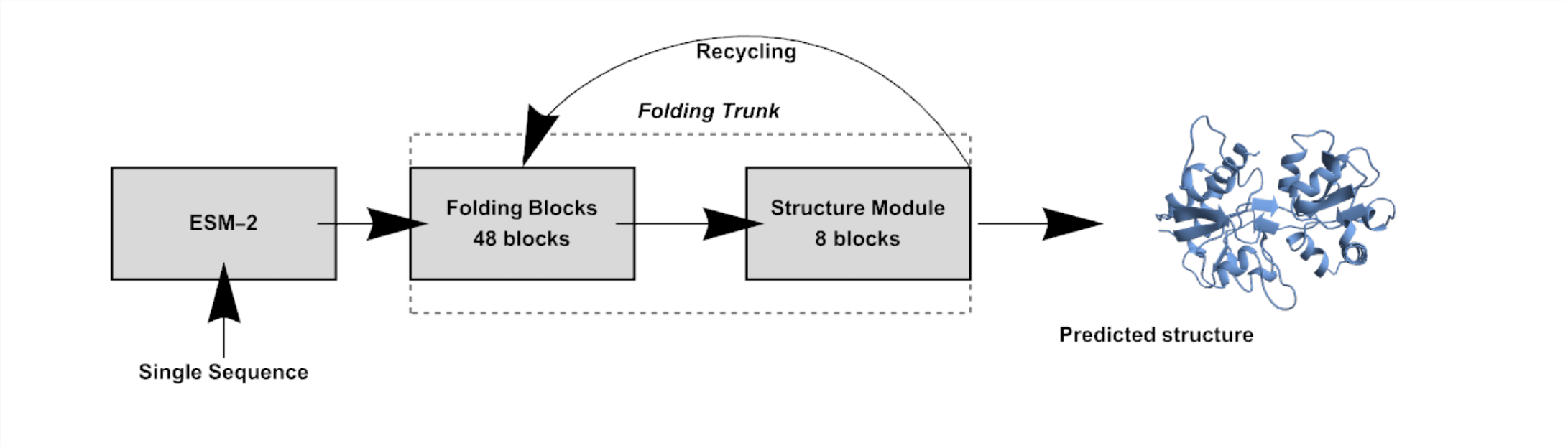
The following diagram shows the modular flow of the ESMFold inference process, which takes a protein sequence and outputs its 3D structure:
The process starts with a raw amino acid sequence with two chains:
The encodeSequence function converts the input protein sequence into numerical lists representing amino acid types, residue indices, a linker mask and chain identifiers for each residue:
The pretrained ESM-2 language model extracts contextual embeddings from the input sequence:
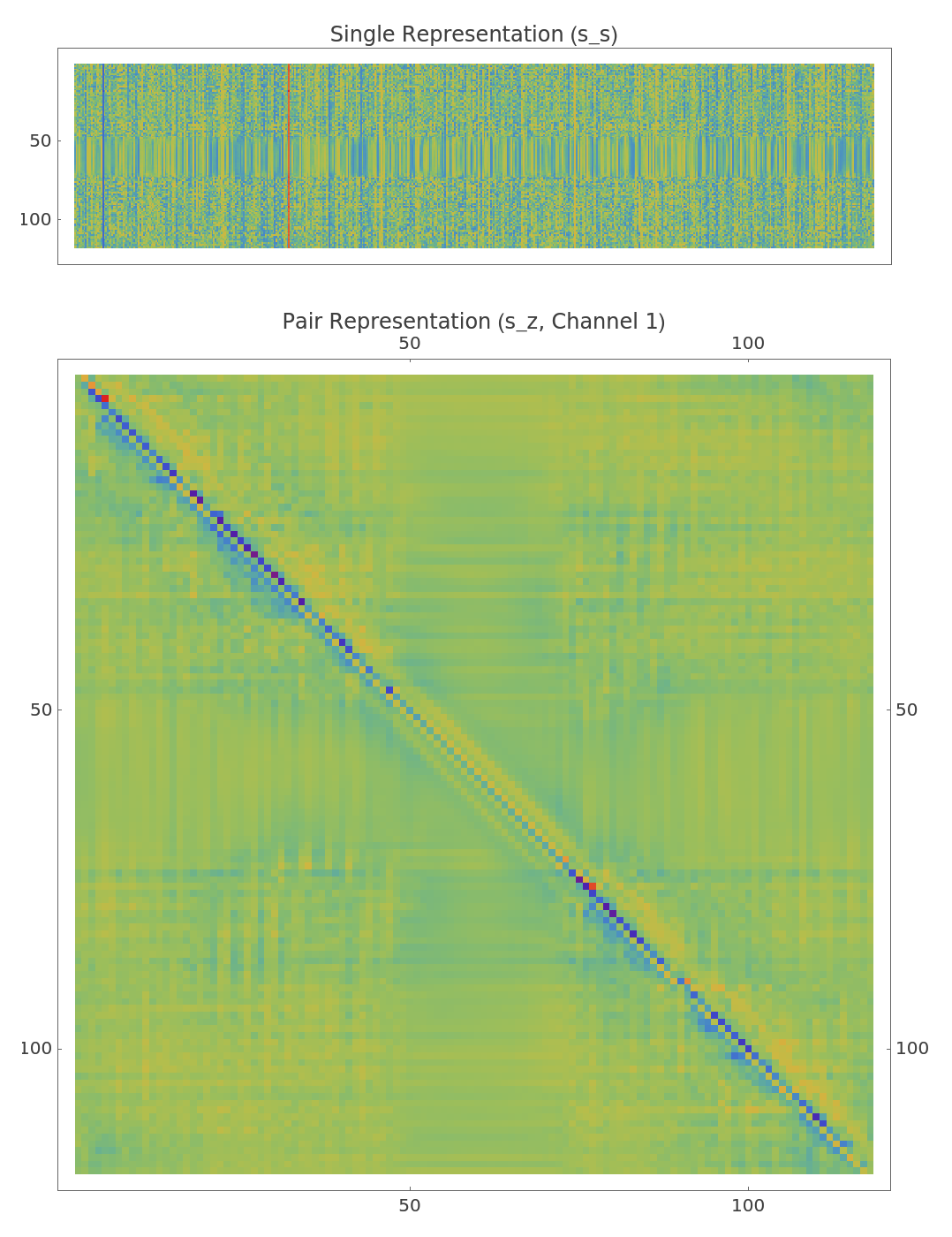
The result includes initial single (s_s_0) and pair (s_z_0) representations. The single representation encodes features for each residue, while the pair representation encodes features for every residue pair, enabling joint local and relational information during folding:
The Folding Trunk is a deep neural network composed of 48 Folding Blocks followed by an additional eight-block Structure Module; together, they refine the internal representations through multiple recycling steps, improving the predicted structure progressively. Initialize input metadata (mask and residue indices) and set up tensors for recycling intermediate representations:
The recycling loop runs multiple times, each time passing the current representations and recycled values into the Folding Trunk model, which updates the representations and predicts the structure. Since the Folding Trunk model already includes the Structure Module internally, it returns both the refined internal features and the predicted atomic structure in a single call:
Visualize the initial single and pair representations:
The post-processing part predicts the final atomic coordinates, frames, angles and sidechains. It also outputs the per-residue confidence (pLDDT) and prepares the data for visualization (PDB string):
The final output includes atomic positions and confidence scores, used to render the 3D protein structure. Convert the output to PDB format:
Get the confidence score:
Plot the result:



![encodeSequence[bs_BioSequence, rest___] := encodeSequence[bs["SequenceString"], rest];
encodeSequence[bs_BioMolecule, rest___] := encodeSequence[Flatten@bs["BioSequence"]["SequenceString"], rest];
encodeSequence[seq_, residueIndexOffset_ : 512, chainLinker_ : StringRepeat["G", 25]] := Module[{chains, joined, encoded, residx, linkerMask, chainIndex, offset = 0, restypesWithX = {"A", "R", "N", "D", "C", "Q", "E", "G", "H", "I",
"L", "K", "M", "F", "P", "S", "T", "W", "Y", "V", "X"}, restypeOrderWithX, chainCount, linkerLen, end},
restypeOrderWithX = AssociationThread[restypesWithX -> Range[1, Length[restypesWithX]]];
(*Setup*)
chains = If[ListQ@seq, seq, {seq}];
chainCount = Length[chains];
linkerLen = StringLength[chainLinker];
joined = StringJoin@Riffle[chains, If[chainCount > 1, chainLinker, ""]];
(*Encode amino acids*)
encoded = Lookup[restypeOrderWithX, Characters[joined], restypeOrderWithX["X"]] - 1;
residx = Range[Length[encoded]] - 1;
(*Apply offsets only if more than 1 chain*)
If[residueIndexOffset > 0 && chainCount > 1, offset = 0;
Do[Module[{start = offset + 1, len = StringLength[chains[[i]]]}, end = start + len - 1;
residx[[start ;; end]] += (i - 1)*residueIndexOffset;
offset = end;
If[i < chainCount,(*Advance offset over linker*)
offset += linkerLen;];], {i, chainCount}];];
(*Linker mask:0 where linker,1 elsewhere*)
linkerMask = ConstantArray[1.0, Length[encoded]];
If[chainCount > 1, offset = 0;
Do[offset += StringLength[chains[[i]]];
If[i < chainCount,
linkerMask[[offset + 1 ;; offset + linkerLen]] = 0;
offset += linkerLen;];, {i, chainCount}];
];
(*Chain index*)
chainIndex = Flatten[Table[
Join[ConstantArray[i - 1, StringLength[chains[[i]]]], If[i < chainCount, ConstantArray[i - 1, linkerLen], {}]], {i, chainCount}]];
Transpose[{{encoded, residx, linkerMask, chainIndex}}]
];](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/5604ba684dcca1b7.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/5725e683-a047-435b-a06f-ceef3df2c07b"]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/3a622ac674a98957.png)
![trunkModel[sS0_, sZ0_, aa_, Optional[noRecycles_, 3], Optional[targetDevice_, "CPU"]] := Module[{recycleS, recycleZ, recycleBins, sS, sZ, i, structure, b, l, mask, residx},
(*Step 1:Initialize the mask and residx*)
{b, l} = Dimensions@aa;
{mask, residx} = {ConstantArray[1, Dimensions@aa], {Range[l] - 1}};
(*Step 2:Initialize recycling tensors*)
{recycleS, recycleZ, recycleBins} = {ConstantArray[0, Dimensions@sS0], ConstantArray[0, Dimensions@sZ0], ConstantArray[0, {1, l, l}]};
(*Step 3:Recycling loop*)
{sS, sZ} = {sS0, sZ0};
For[i = 0, LessEqual[i, noRecycles], Increment@i, structure = NetModel[{"ESMFold-V1 Trained on UR50 Data", "Part" -> "FoldingTrunk"}][<|"aa" -> aa, "s_s_0" -> sS0, "s_z_0" -> sZ0, "recycle_s" -> recycleS, "recycle_z" -> recycleZ, "recycle_bins" -> recycleBins, "residx" -> residx, "mask" -> mask|>, TargetDevice -> targetDevice];
{sS, sZ, recycleS, recycleZ, recycleBins} = Lookup[structure, {"s_s", "s_z", "updated_recycle_s", "updated_recycle_z", "updated_recycle_bins"}];
(*Step 4:Update recycle tensors*)
{recycleS, recycleZ} = {sS, sZ};];
structure]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/3a93c88f2638d4b7.png)
![Options[esmFoldInference] = {"Size" -> "V1", "numRecycles" -> 0, "Confidence" -> True, "chainLinker" -> StringRepeat["X", 25], "residueIndexOffset" -> 512, TargetDevice -> "CPU"};
esmFoldInference[sequence_, OptionsPattern[]] := Module[{seq, aatype, pdbStr, residx, chainIndex, linkerMask, seqs, esm, structure, output, atom37AtomExists, meanPlddt},(*Handle single sequence input*)
(*Batch encode sequences*)
{aatype, residx, linkerMask, chainIndex} = encodeSequence[sequence, OptionValue["residueIndexOffset"], OptionValue@"chainLinker"];
(*Step 1:Run the ESM Language Model Wrapper*)
esm = NetModel[{"ESMFold-V1 Trained on UR50 Data", "Part" -> "LanguageModel", "Size" -> OptionValue@"Size"}][
aatype, TargetDevice -> OptionValue@TargetDevice];
(*Step 2:Run the Trunk Model*)
structure = trunkModel[esm@"s_s_0", esm@"s_z_0", aatype, OptionValue@"numRecycles", OptionValue@TargetDevice];
(*Step 3:Post-process the outputs*)
output = NetModel[{"ESMFold-V1 Trained on UR50 Data", "Part" -> "PostProcessing"}][<|"aa" -> aatype, "frames_0" -> structure["frames"], "sidechain_frames_0" -> structure["sidechain_frames"], "unnormalized_angles_0" -> structure["unnormalized_angles"], "angles_0" -> structure["angles"], "positions_0" -> structure["positions"], "single_0" -> structure["single"], "states_0" -> structure["states"], "s_s_0" -> structure["s_s"], "s_z_0" -> structure["s_z"]|>, TargetDevice -> OptionValue@TargetDevice];
(*Adjust atom37_atom_exists*)
atom37AtomExists = output["atom37_atom_exists"]*linkerMask;
(*Compute mean_plddt*)
meanPlddt = Total[output["plddt"]*atom37AtomExists, All]/
Total[atom37AtomExists, All];
(*Process results*)
output = Association["positions" -> output["positions"], "aatype" -> output["aatype"], "atom14_atom_exists" -> output["atom14_atom_exists"], "residx_atom14_to_atom37" -> output["residx_atom14_to_atom37"], "residx_atom37_to_atom14" -> output["residx_atom37_to_atom14"], "atom37_atom_exists" -> output["atom37_atom_exists"], "residue_index" -> output["residue_index"], "plddt" -> output["plddt"]];
(*Add chain_index to output*)
output["chain_index"] = chainIndex;
output["mean_plddt"] = meanPlddt;
pdbStr = outputToPDB@output;
If[OptionValue["Confidence"], {pdbStr, output["mean_plddt"]},
pdbStr]
]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/27979bc5780fc982.png)
![Options[netevaluate] = {"Size" -> "V1", "numRecycles" -> 3, TargetDevice -> "CPU", "Confidence" -> True};
netevaluate[sequence_, OptionsPattern[]] := Enclose@Block[{pdb},
pdb = esmFoldInference[sequence, "Size" -> OptionValue["Size"], "numRecycles" -> If[OptionValue["Size"] == "V1", OptionValue["numRecycles"], 1], "Confidence" -> OptionValue["Confidence"], TargetDevice -> OptionValue[TargetDevice]];
If[OptionValue["Confidence"], Association@{"Structure" -> ImportString[pdb[[1]], {"PDB", "BioMolecule"}, "PredictedStructure" -> True], "Confidence" -> pdb[[2]]}, ImportString[pdb, {"PDB", "BioMolecule"}, "PredictedStructure" -> True]]
]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/019569a83f31d3b7.png)
![testSequence = BioSequence[
"Peptide", "SLIVTTILEEPYVLFKKSDKPLYGNDRFEGYCIDLLRELSTILGFTYEIRLVEDGKYGAQDNGQWNGMVRELIDHKADLAVAPLAITYVREKVIDFSAPFMTLGISILYRKGTPIDSADDLAKQTKIEYGAVEDGATMTFFKKSKISTYDKMWAFMSSRRQSVLVKSNEEGIQRVLTSDYAFLMESTTIEFVTQRNCNLTQIGGLIDSKGYGVGTPMGSPYRDKITIAILQLQEEGKLHMMKEKWW", {}];](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/1e0f6188df26ee68.png)

![enzymes = Map[Style[#, Red] &, {"ACGYLKTPKLADPPVLRGDSSVTKAICKPDPVLEK", "GVALDECKALDYLPGKPLPMDGKVCQCGSKTPLRP", "VLPGYTCGELDCKPGKPLPKCGADKTQVATPFLRG", "TCGALVQYPSCADPPVLRGSDSSVKACKKLDPQDK", "GALCEECKLCPGADYKPMDGDRLPAAATSKTRPVG", "PAVDCKKALVYLPKPLPMDGKVCRGSKTPKTRPYG", "VLGYTCGALDCKPGKPLPKCGADKTQVATPFLRGA", "CGALVQYPSCADPPVLRGSDSSVKACKKLDPQDKT", "ALCEECKLCPGADYKPMDGDRLPAAATSKTRPVGK", "AVDCKKALVYLPKPLPMDGKVCRGSKTPKTRPYGR"}];
structuralProteins = Map[Style[#, Green] &, {"VGKGFRYGSSQKRYLHCQKSALPPSCRRGKGQGSAT", "KDPTVMTVGTYSCQCPKQDSRGSVQPTSRVKTSRSK", "PLVGKACGRSSDYKCPGQMVSGGSKQTPASQRPSYD", "CGKKLVGYPSSKADVPLQGRSSFSPKACKKDPQMTS", "RKGVASLYCSSKLSCKAQYSKGMSDGRSPKASSTTS", "RPKSAASCEQAKSYRSLSLPSMKGKVPSKCSRSKRP", "RSDVSYTSCSQSKDCKPSKPPKMSGSKDSSTVATPS", "LSTCSKKVAYPSSKADPPSSGRSSFSMKACKKQDPPV", "RVGSASSEPKSSCSVQSYSKPSMSGDSSPKASSTSK", "QPSASNCEKMSSYRPSLPSMSKGVPSSRSKSSPPYQ"}];](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/6eac88ebcd1ea3f5.png)
![extractor = Map[Max, Transpose@
NetModel[{"ESMFold-V1 Trained on UR50 Data", "Size" -> "150M"}][
encodeSequence[#][[1]]]["s_s_0"][[1]]] &;](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/3d85bfeba945c51f.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/399243de-f5d9-4d3e-9635-e718033d7c9e"]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/770e0c151fb9f459.png)

![(*Initialize the mask and residx*)
{sS0, sZ0} = {esm@"s_s_0", esm@"s_z_0"};
{b, l} = Dimensions@aatype;
{mask, residx} = {ConstantArray[1, Dimensions@aatype], {Range[l] - 1}};
(*Initialize recycling tensors*)
{recycleS, recycleZ, recycleBins} = {ConstantArray[0, Dimensions@sS0],
ConstantArray[0, Dimensions@sZ0], ConstantArray[0, {1, l, l}]};](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/14dcc97881939405.png)
![(*Recycling loop*)
{sS, sZ} = {sS0, sZ0};
For[i = 0, LessEqual[i, 3], Increment@i, structure = NetModel[{"ESMFold-V1 Trained on UR50 Data", "Part" -> "FoldingTrunk"}][<|"aa" -> aatype, "s_s_0" -> sS0, "s_z_0" -> sZ0, "recycle_s" -> recycleS, "recycle_z" -> recycleZ,
"recycle_bins" -> recycleBins, "residx" -> residx, "mask" -> mask|>
];
{sS, sZ, recycleS, recycleZ, recycleBins} = Lookup[structure, {"s_s", "s_z", "updated_recycle_s", "updated_recycle_z", "updated_recycle_bins"}];
(*Update recycle tensors*)
{recycleS, recycleZ} = {sS, sZ};
];](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/4c42c32ec0be48c8.png)
![GraphicsColumn[{MatrixPlot[sS[[1]], FrameTicks -> {Automatic, None}, PlotLabel -> "Single Representation (s_s)", ImageSize -> Large, ColorFunction -> "Rainbow"], ArrayPlot[sZ[[1, All, All, 1]], ColorFunction -> "Rainbow", FrameTicks -> Automatic, PlotLabel -> "Pair Representation (s_z, Channel 1)", ImageSize -> Large]}]](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/2373aeadb4ffe131.png)
![output = NetModel[{"ESMFold-V1 Trained on UR50 Data", "Part" -> "PostProcessing"}][<|"aa" -> aatype, "frames_0" -> structure["frames"], "sidechain_frames_0" -> structure["sidechain_frames"], "unnormalized_angles_0" -> structure["unnormalized_angles"], "angles_0" -> structure["angles"], "positions_0" -> structure["positions"], "single_0" -> structure["single"], "states_0" -> structure["states"], "s_s_0" -> structure["s_s"], "s_z_0" -> structure["s_z"]|>];
(*Adjust atom37_atom_exists*)
atom37AtomExists = output@"atom37_atom_exists";
(*Compute mean_plddt*)
meanPlddt = Total[output["plddt"]*atom37AtomExists, All]/
Total[atom37AtomExists, All];
(*Process results*)
output = Association["positions" -> output["positions"], "aatype" -> output["aatype"], "atom14_atom_exists" -> output["atom14_atom_exists"], "residx_atom14_to_atom37" -> output["residx_atom14_to_atom37"], "residx_atom37_to_atom14" -> output["residx_atom37_to_atom14"], "atom37_atom_exists" -> output["atom37_atom_exists"], "residue_index" -> output["residue_index"], "plddt" -> output["plddt"]];
(*Add chain_index to output*)
output["chain_index"] = chainIndex;
output["mean_plddt"] = meanPlddt;](https://www.wolframcloud.com/obj/resourcesystem/images/414/414f6464-3265-4719-8962-7ac2be1d6fe5/578eef9cac506fc6.png)