BPEmb Subword Embeddings
Trained on
Wikipedia Data
Released in 2017, this collection of models combines BPE tokenization and the Global Vectors (GloVe) method to create subword embeddings for 275 languages with various dimensions and vocabulary sizes, all trained on Wikipedia. They can be used out of the box as a basis to train NLP applications or just for generic BPE text segmentation. Since all digits were mapped to 0 before training, these models map all digits except 0 to the unkown token.
Number of models: 2,520
Examples
Resource retrieval
Get the pre-trained net:
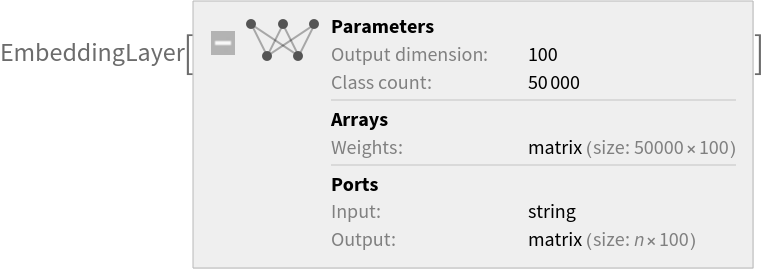
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default model by specifying the parameters:
Pick a non-default untrained net:
Basic usage
For each token, the net produces a vector of features:
Obtain the dimensions of the vectors:
Visualize the embeddings:
Use the embedding layer inside a NetChain:
BPE tokenization
The BPE tokenization can be extracted from the model as a NetEncoder:
The encoder segments the input string into words and subwords using BPE tokenization and outputs integer codes for each token:
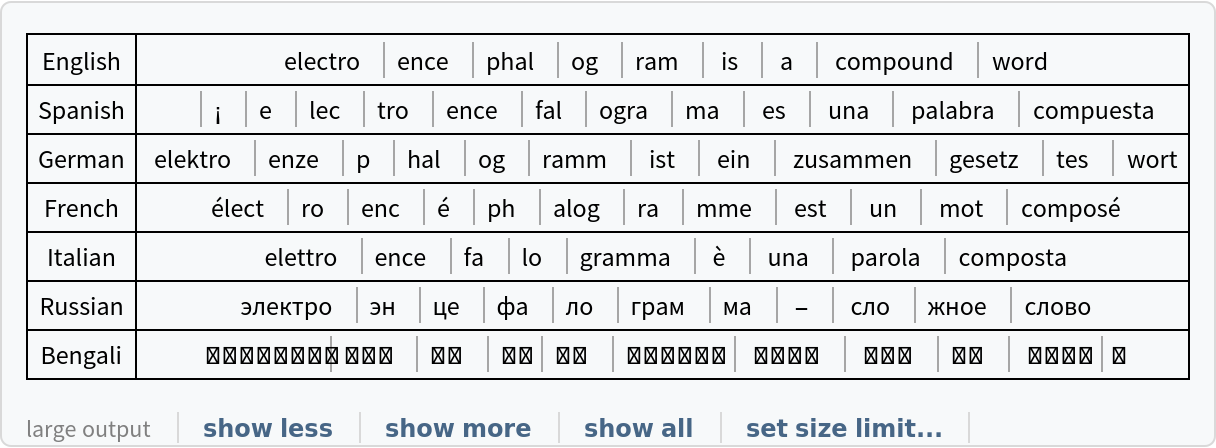
Obtain the tokens. Rare words are usually split up into subwords:
Write a function to tokenize a string in any language:
Compare tokenizations in various languages:
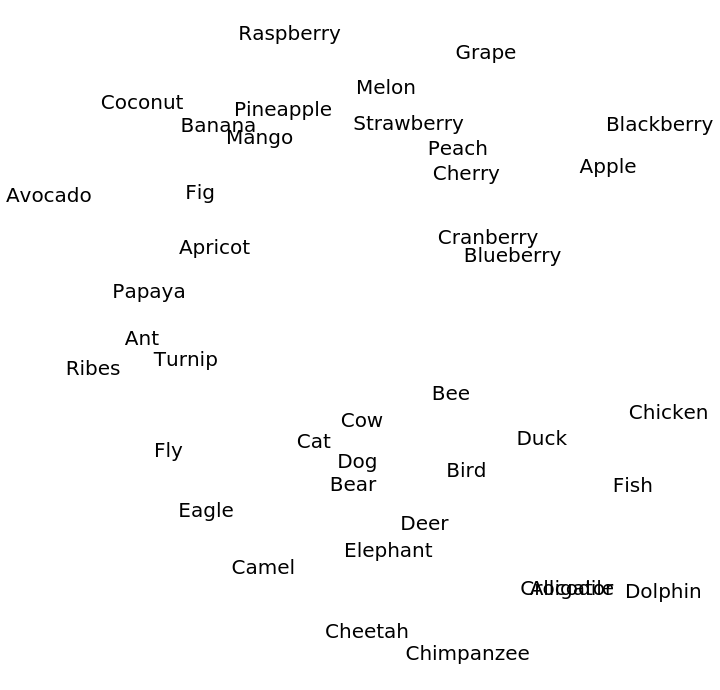
Feature visualization
Create two lists of related words:
Visualize relationships between the words using the net as a feature extractor:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the layer type counts:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
Requirements
Wolfram Language
12.0
(April 2019)
or above
Resource History
Reference




![tokenizeBPE[language_, sentence_] := With[
{tokenizer = NetExtract[
NetModel[{"BPEmb Subword Embeddings Trained on Wikipedia Data", "Language" -> language, "VocabularySize" -> 10000}], "Input"]},
tokenizer[["Tokens"]][[tokenizer[sentence]]]
];](https://www.wolframcloud.com/obj/resourcesystem/images/999/999d8271-1da7-4ef0-81e7-597601eafb7d/5d25e433f7d3842b.png)
![sentences = <|
"English" -> "Electroencephalogram is a compound word",
"Spanish" -> "¡Electroencefalograma es una palabra compuesta",
"German" -> "Elektroenzephalogramm ist ein zusammengesetztes wort",
"French" -> "Électroencéphalogramme est un mot composé",
"Italian" -> "Elettroencefalogramma è una parola composta",
"Russian" -> "Электроэнцефалограмма - сложное слово",
"Bengali" -> "ইলেক্ট্রোয়েন্ফালোগ্রাম একটি যৌগিক শব্দদ"
|>;
Grid[KeyValueMap[{#1, TextElement@tokenizeBPE[#1, #2]} &, sentences], Dividers -> All]](https://www.wolframcloud.com/obj/resourcesystem/images/999/999d8271-1da7-4ef0-81e7-597601eafb7d/2b8b33c93ba2e56d.png)