X3D Video Action Classification
Trained on
Kinetics-400 Data
X3D is a family of efficient video networks with a focus on low-computation regime in terms of computation/accuracy tradeoff for video recognition. The main idea is to progressively expand a tiny base 2D image architecture into a spatiotemporal one by expanding multiple axes: temporal duration, frame rate, spatial resolution, network width, bottleneck width and depth. X3D achieves state-of-the-art performance while requiring 4.8x and 5.5x fewer multiply-adds and parameters for similar accuracy as previous work.
Examples
Resource retrieval
Get the pre-trained net:
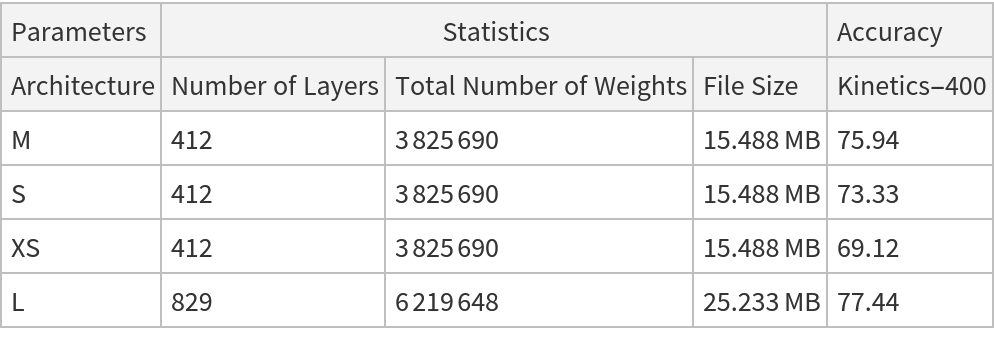
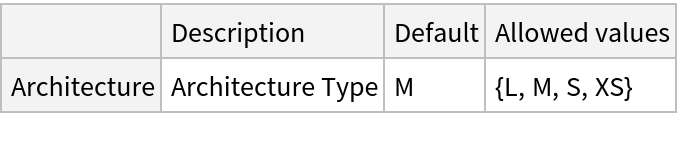
NetModel parameters
This model consists of a family of individual nets, each identified by a specific architecture. Inspect the available parameters:
Pick a non-default net by specifying the architecture:
Pick a non-default uninitialized net:
Basic usage
Classify a video:
Obtain the probabilities predicted by the net:
Feature extraction
Remove the last three layers of the trained net so that the net produces a vector representation of an image:
Get a set of videos:
Visualize the features of a set of videos:
Transfer learning
Use the pre-trained model to build a classifier for telling apart images from two action classes not present in the dataset. Create a test set and a training set:
Remove the LinearLayer, the SoftmaxLayer and the AggregationLayer from the pre-trained net:
Create a new net composed of the pre-trained net followed by a LinearLayer, a SoftmaxLayer and an AggregationLayer:
Train on the dataset, freezing all the weights except for those in the "Linear" layer (use TargetDevice -> "GPU" for training on a GPU):
Perfect accuracy is obtained on the test set:
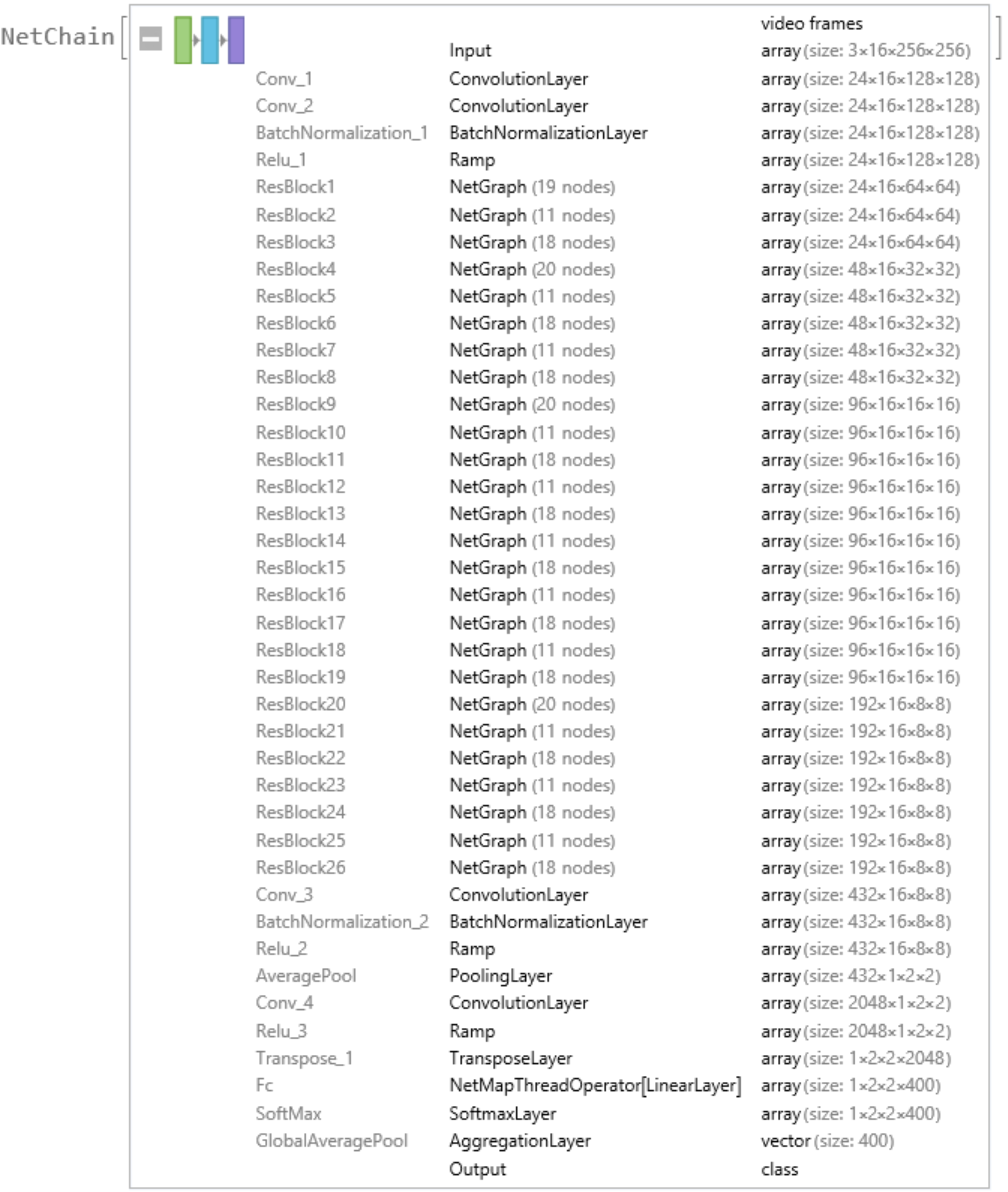
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Resource History
Reference




![FeatureSpacePlot[videos, FeatureExtractor -> (extractor[#] &), LabelingFunction -> (Placed[Thumbnail@VideoFrameList[#1, 1][[1]], Center] &), LabelingSize -> 70, ImageSize -> 400, Method -> "TSNE"]](https://www.wolframcloud.com/obj/resourcesystem/images/91f/91f790e1-87ab-469f-939c-1b18788c02c0/1fa2a9a5716fe9e5.png)

![videos = <|
VideoTrim[ResourceData["Sample Video: Wild Ducks in the Park"], 10] -> "Wild Ducks in the Park", VideoTrim[ResourceData["Sample Video: Freezing Bubble"], 10] -> "Freezing Bubble"|>;](https://www.wolframcloud.com/obj/resourcesystem/images/91f/91f790e1-87ab-469f-939c-1b18788c02c0/1b2aa0ac3a656d85.png)
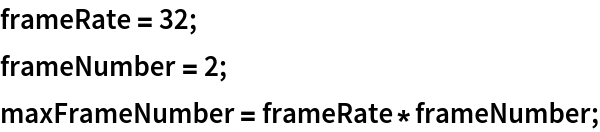
![dataset = Join @@ KeyValueMap[
Table[VideoTrim[#1, {Quantity[i, "Frames"], Quantity[i + maxFrameNumber - 1, "Frames"]}] -> #2, {i, 1, Information[#1, "FrameCount"][[1]] - Mod[Information[#1, "FrameCount"][[1]], maxFrameNumber], Round[maxFrameNumber/4]}] &, videos];](https://www.wolframcloud.com/obj/resourcesystem/images/91f/91f790e1-87ab-469f-939c-1b18788c02c0/1e162a074ec16c60.png)

![newNet = NetAppend[
tempNet, {"Linear" -> fc, "SoftMax" -> SoftmaxLayer[], "GlobalAveragePool" -> AggregationLayer[Mean, ;; -2]}, "Output" -> NetDecoder[{"Class", {"Freezing Bubble", "Wild Ducks in the Park"}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/91f/91f790e1-87ab-469f-939c-1b18788c02c0/73f19a753c4f88a2.png)


