Resource retrieval
Get the pre-trained net:
NetModel parameters
This model consists of a family of individual nets, each identified by a specific architecture. Inspect the available parameters:
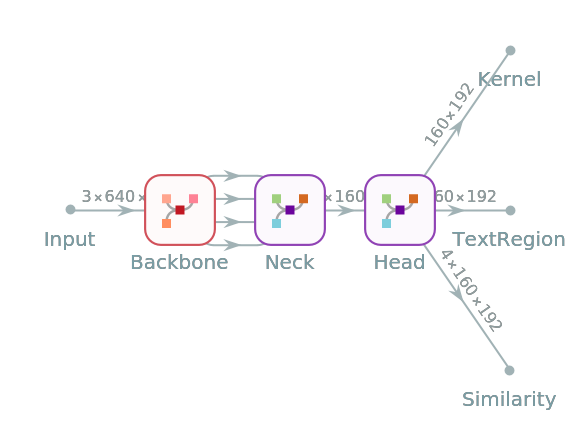
Pick a non-default net by specifying the architecture:
Pick a non-default uninitialized net:
Evaluation function
Write an evaluation function to extract the bounding regions and masks for each text instance:
Basic usage
Obtain the bounding boxes and masks for each text instance in a given image:
The output is an Association containing the detected bounding boxes with their labels:
Visualize the bounding regions:
Advanced usage
Get an image:
Obtain the bounding regions using the default evaluation and visualize them:
Get the individual masks via the option "Output"->"Masks":
Increase the "MinTextArea" to remove small regions:
Set the region type to "MinConvexPolygon" to generate arbitrarily shaped regions:
Network result
Get an image:
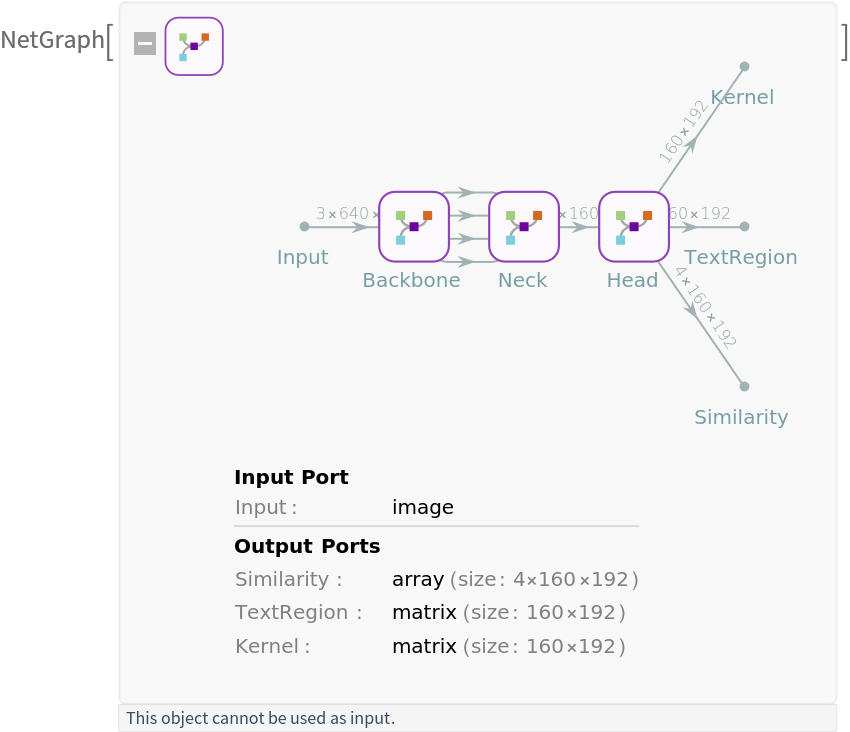
Run the model on the image:
The model's outputs are the "TextRegion", "Kernel" and "Similarity" components. The text region matrix outlines the entire area of each text instance, while the kernel matrix helps distinguish between individual text instances. The similarity vector then guides the grouping of pixels within each instance:
Binarize the text probability map and the kernel. Multiply both images to obtain the final kernel:
Split the detected instances:
Use the expandComponent function to expand the kernel region using the similarity matrices as a guide:
Filter the small areas:
All outputs contain rectangular matrices with fixed dimensions, specifically 160×192. Adjust the result dimensions to the original image shape:
Visualize the detected text instances:
Net information
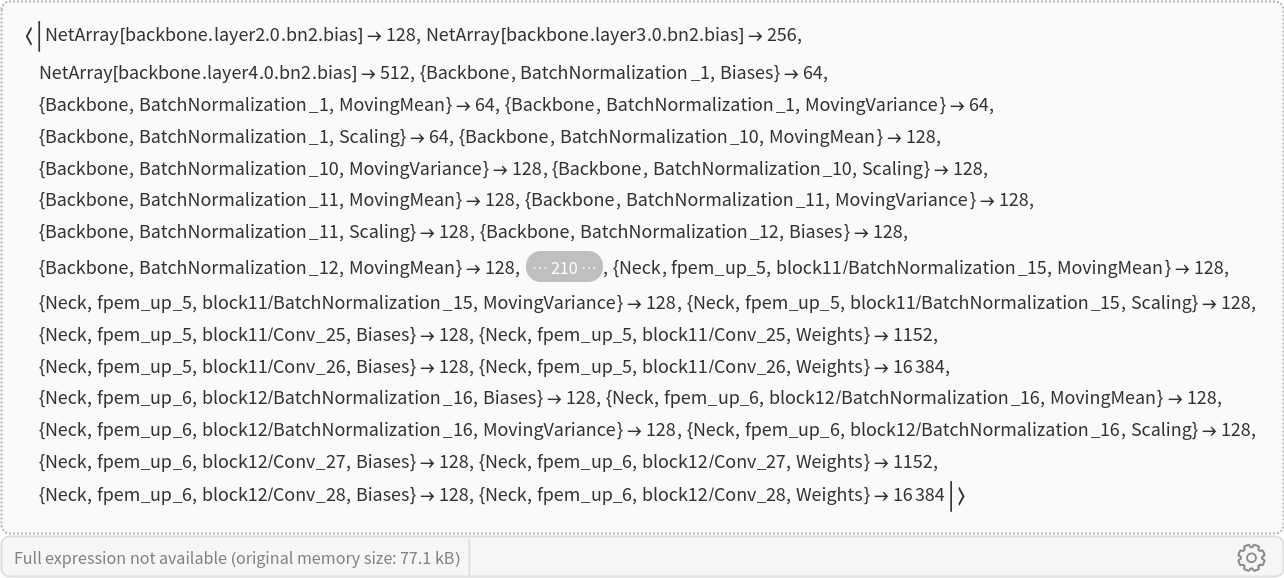
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to ONNX
Export the net to the ONNX format:
Get the size of the ONNX file:
The size is similar to the byte count of the resource object:
Check some metadata of the ONNX model:
Import the model back into Wolfram Language. However, the NetEncoder and NetDecoder will be absent because they are not supported by ONNX:

![NetModel["PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data", "ParametersInformation"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/5163b3333764f98a.png)

![NetModel[{"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data",
"Dataset" -> "ICDAR2015"}]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/45c88e96f5b619d8.png)
![NetModel[{"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data",
"Dataset" -> "ICDAR2015"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/6e7cb59b1bb6d653.png)
![perimeter = ImageSubtract[Dilation[#, 1] - #] &;
expandComponent[component_, similarity_, t_] := Module[{p, mean, dist, new},
p = PixelValuePositions[perimeter@component, 1];
mean = ImageMeasurements[similarity, "Mean", Masking -> component];
dist = DistanceMatrix[PixelValue[similarity, p], {mean}][[All, 1]];
new = Pick[p, UnitStep[t - dist], 1];
ReplacePixelValue[component, new -> 1]]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/140b80d367391f48.png)
![Options[netevaluate] = { "MaskThreshold" -> 0.5, "KernelThreshold" -> 0.2, "MinTextArea" -> 16, "RegionType" -> "MinOrientedRectangle", "Output" -> "Regions" | "Masks"};
netevaluate[img_, OptionsPattern[]] := Module[
{result, kernel, embeddings, similarity, comlist, labels, scores, masks, elem, area, mean, score, i, inputImageDims, h, w, ratio, tRatio, contours, boundingReg}, result = NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"][
img]; kernel = Image[UnitStep[result["Kernel"] - OptionValue["KernelThreshold"]]*
UnitStep[result["TextRegion"] - OptionValue["MaskThreshold"]]];
similarity = Image[result["Similarity"], Interleaving -> False];
comlist = Image /@ Values@ComponentMeasurements[kernel, "Mask"];
labels = Map[expandComponent[#, similarity, OptionValue["MaskThreshold"]] &,
comlist]; (*Filter the results by defining thresholds for the instance area and pixel value's mean*)
masks = Association[];
scores = Association[];
elem = 1;
For[i = 1, i <= Length[labels], i++,
With[{label = labels[[i]]},
area = Values[ComponentMeasurements[label, "Area"]][[1]];
If[SameQ[area, {}], Continue[]];
If[area >= OptionValue["MinTextArea"],
AppendTo[masks, elem -> label];
elem += 1,
Continue[]
]
]
]; (*scale the results to match the shape of the original image*)
inputImageDims = ImageDimensions[img];
{w, h} = ImageDimensions[kernel];
ratio = ImageAspectRatio[img];
tRatio = ImageAspectRatio[kernel];
masks = Map[If[
tRatio/ratio > 1,
ImageResize[ImageCrop[#, {w, w*ratio}], inputImageDims],
ImageResize[ImageCrop[#, {h /ratio, h}], inputImageDims]
] &, masks]; If[SameQ[OptionValue["Output"], "Masks"], Return[masks]]; (*get the texts contours*)
contours = Map[Values[
ComponentMeasurements[#, "PerimeterPositions", CornerNeighbors -> True]][[1]] &, masks]; (*get the bounding region for each contour *)
boundingReg = Which[
SameQ[OptionValue["RegionType"], "MinRectangle"],
Map[BoundingRegion[#[[1]], "MinRectangle"] & , contours],
SameQ[OptionValue["RegionType"], "MinOrientedRectangle"],
Map[BoundingRegion[#[[1]], "MinOrientedRectangle"] & , contours],
SameQ[OptionValue["RegionType"], "MinConvexPolygon"],
Map[BoundingRegion[#[[1]], "MinConvexPolygon"] & , contours]
];
boundingReg
];](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/518cf0f3bf3aac45.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/c554b551-f58a-4ce8-8565-7db9f95fdc81"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/5726bd05e3b3e552.png)


![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/2d82ac04-570f-419d-a511-81fdee62edaf"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/33cfe02aa73c6bb8.png)





![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/0eb24de7-a93c-4416-9f0b-32c0ab1005d1"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/24809c94ba3dd4fb.png)



![mask = Binarize[textProbMap, 0.5];
kernel = Binarize[kernelMap, 0.5];
kernel = ImageMultiply[kernel, mask]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/399864e35b939f58.png)




![scaleResult[img_Image, orImg_Image] := Module[{inputImageDims, w, h, ratio, tRatio},
(*scale the results to match the shape of the original image*)
inputImageDims = ImageDimensions[orImg];
{w, h} = ImageDimensions[img];
ratio = ImageAspectRatio[orImg];
tRatio = ImageAspectRatio[img];
If[
tRatio/ratio > 1,
ImageResize[ImageCrop[img, {w, w*ratio}], inputImageDims],
ImageResize[ImageCrop[img, {h /ratio, h}], inputImageDims]
]
];
labels = Map[scaleResult[#, testImage] &, labels]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/617d84214239beb5.png)


![Information[
NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/697b79a72ff1041f.png)
![Information[
NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/4102e8c7d3e29732.png)
![Information[
NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/634b861121dfd44d.png)
![Information[
NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/3d8c7a8a9d65b4b0.png)
![onnxFile = Export[FileNameJoin[{$TemporaryDirectory, "net.onnx"}], NetModel[
"PANet Text Detector Trained on ICDAR-2015 and CTW1500 Data"]]](https://www.wolframcloud.com/obj/resourcesystem/images/53c/53ce4323-7fd5-4e8c-9f96-f311121d8d81/2fdbd4d35cf032ad.png)
