NetModel parameters
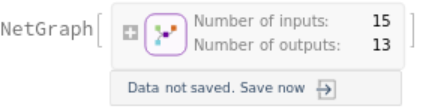
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Pick a non-default uninitialized net:
Get the labels:
Feature extraction
Get a set of audio samples for background noise and speech:
Visualize the feature space embedding performed by the audio encoder. Notice that the human speech samples and the background noise samples belong to different clusters:
Advanced usage
Set the option "IncludeTimestamps" to True to add timestamps at the beginning and end of the audio sample:
Perform transcription with a different "Temperature":
The option "SuppressSpecialTokens" removes non-speech tokens. Compare the transcription of the original audio sample with the sample after "SuppressSpecialTokens" is enabled:
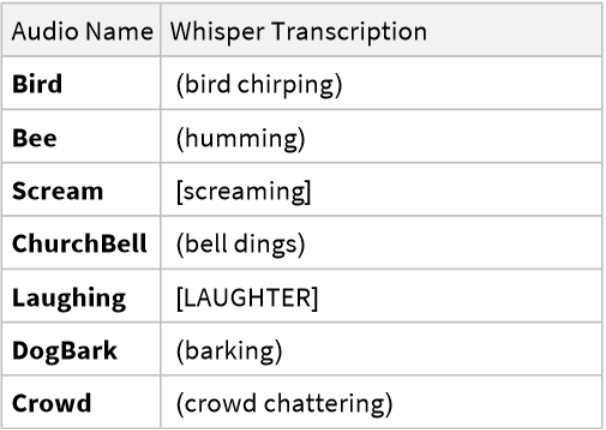
Whisper can recognize actions or background sounds in an audio sample:
Transcription
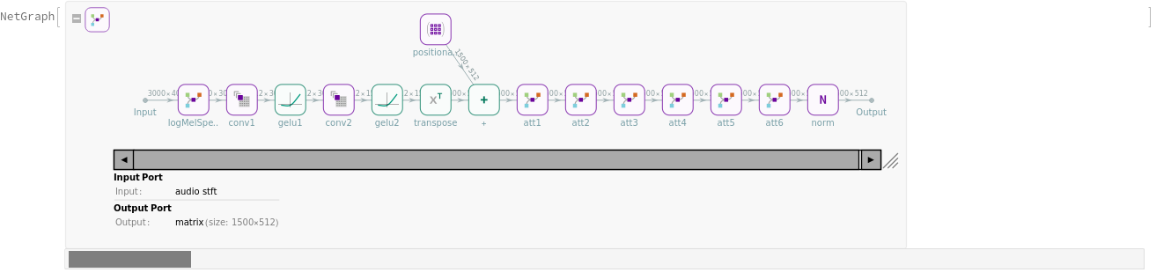
The transcription pipeline makes use of two separate transformer nets, encoder and decoder:
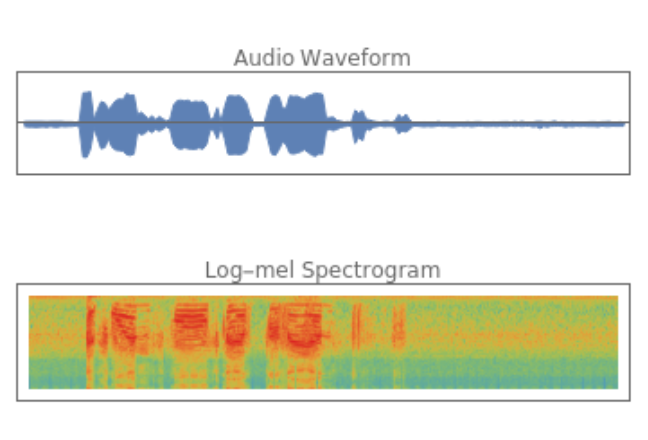
The encoder preprocesses input audio into a log-Mel spectrogram, capturing the signal's frequency content over time:
Get an input audio sample and compute its log-Mel spectrogram:
Visualize the log-Mel spectrogram and the audio waveform:
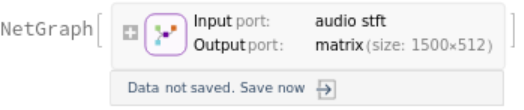
The encoder processes the input once, producing a feature matrix of size 1500x512:
The decoding step involves running the decoder multiple times recursively, with each iteration producing a subword token of the transcribed audio. The decoder receives several inputs:
• The port "Input1" takes the subword token generated by the previous evaluation of the decoder.
• The port "Index" takes an integer keeping count of how many times the decoder was evaluated (positional encoding).
• The port "Input2" takes the encoded features produced by the encoder. The data fed to this input is the same for every evaluation of the decoder.
• The ports "State1", "State2"... take the self-attention key and value arrays for all the past tokens. Their size grows by one at each evaluation. The default ("Size"->"Base") decoder has 12 attention blocks, which makes for 24 states: 12 key arrays and 12 value arrays.
Before starting the decoding process, initialize the decoder's inputs:
Use the decoder iteratively to transcribe the audio sample. The recursion keeps going until the EndOfString token is generated or the maximum number of iterations is reached:
Display the generated tokens:
Obtain a readable representation of the tokens:
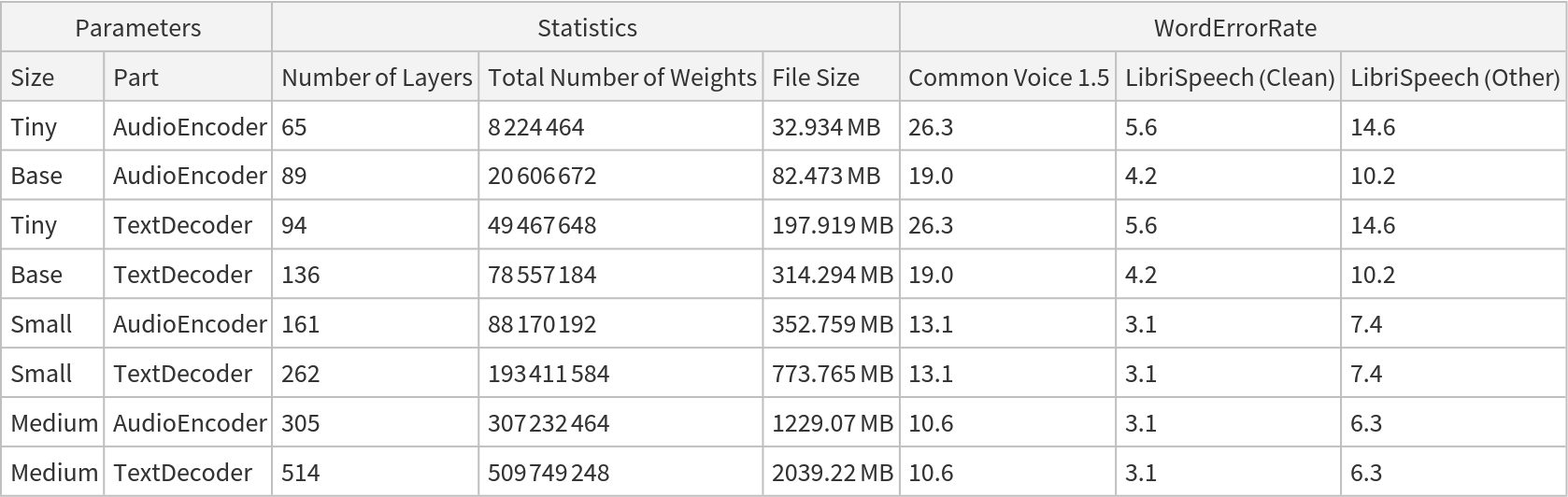
Net information
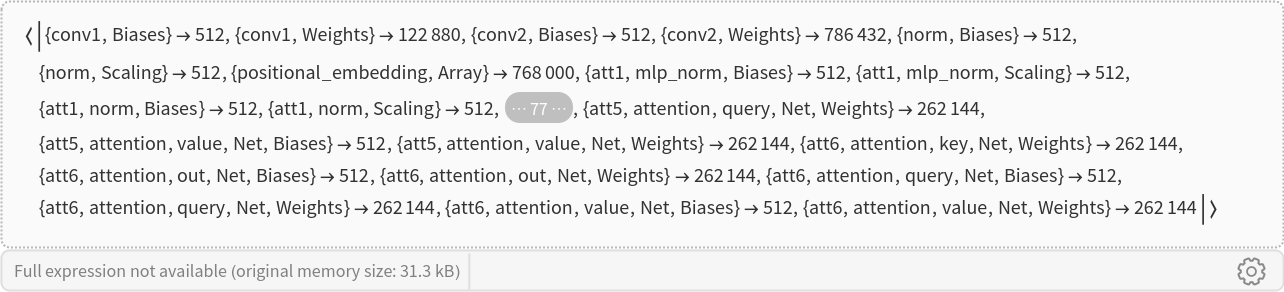
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:

![NetModel[{"Whisper-V1 Nets", "Size" -> "Tiny", "Part" -> "TextDecoder"}, "UninitializedEvaluationNet"]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/1b81afb332fae435.png)

![suppress[logits_, tokenIds_ : {}] := ReplacePart[logits, Thread[tokenIds -> -Infinity]];
rescore[logits_, temp_ : 1] := Block[{expRescaledLog, total}, expRescaledLog = Quiet[Exp[logits/temp]] /. Indeterminate -> 0.;
total = Total[expRescaledLog, {-1}] /. 0. -> 1.;
expRescaledLog/total]
sample[probs_, temp_, tokenIds_ : {}] := Block[{weights, suppressLogits}, suppressLogits = suppress[Log[probs], tokenIds];
weights = Quiet@rescore[suppressLogits, temp];
First@
If[Max[weights] > 0, RandomSample[weights -> Range@Length@weights, 1], FirstPosition[#, Max[#]] &@
Exp[suppressLogits](*low temperature cases*)]];
sample[probs_, 0., tokenIds_ : {}] := First@FirstPosition[#, Max[#]] &@suppress[probs, tokenIds];
sample[probs_, 0, tokenIds_ : {}] := sample[probs, 0., tokenIds];](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/1be402b405481764.png)
![Options[generate] = {MaxIterations -> 224, TargetDevice -> "CPU", "Temperature" -> 0, "IncludeTimestamps" -> False, "SuppressSpecialTokens" -> False};
generate[features_, prev_, textDecoder_, initStates_, outPorts_, opts : OptionsPattern[]] := Module[{index = 1, generated = {}, logProbs = {}, isGenerating = False, suppressTokens = CompressedData["
1:eJwtz70rBHAcx/E3znPyELqck+cibpHkmZISg6QkD8MlpeSUh1kXkvwBlrvF
ZLGQuzNQYpDZYFBGfwBJFu/B8Fp+9ft+Pp+GaGxmIwtYULZyVKBCFalYpapR
SLUKq0716teABjWkYY3831vUkpb1plWDYkqpyrAL3Sts6JmaAvCoT5ELQY0o
qk2t5MG3ZvNhy5J9lszopATOLbldBj/l8FQBV5XwXg03QWi29HELfLTCWJs5
7ZDogNtO2I/AehfEu+FAr73w7KiQI05HYWIcApPQMwVf09A45/s87K1Bcgde
dv0bh8Mj9yYgknSnLtPwewczD3CtlNLK6EZ/5LQ5ng==
"], eosCode = 50257, sosCode = 50258, sopCode = 50361, tStampCode = 50363, noSpeechCode = 50362, noSpeechThresh = 0.6, avgLogProb, noSpeech = False, token, probs, init, prompt, netOut}, (*Check if gen is empty, meaning this is the first audio segment*)
If[Length[prev] === 0,
(*If it's the first audio segment,
start with a Start of Sequence (SOS) token*)
prompt = {sosCode, If[OptionValue["IncludeTimestamps"], Nothing, tStampCode]};
,
(*Else, use the last 224 tokens from the previous generation as context for the next generation*)
prompt = {sopCode, Sequence @@ prev[[-Min[Length[prev], 224] ;;]], sosCode, If[OptionValue["IncludeTimestamps"], Nothing, tStampCode]};
];
(*define initial input*)
init = Join[
<|"Index" -> index,
"Input1" -> prompt[[1]],
"Input2" -> features
|>,
initStates
]; (*Iterating the generation process*)
NestWhile[
Function[
If[SameQ[index, Length[prompt]], isGenerating = True];
netOut = textDecoder[#, outPorts, TargetDevice -> OptionValue[TargetDevice]];
probs = netOut[NetPort[{"softmax", "Output"}]];
token = sample[probs, OptionValue["Temperature"], Which[OptionValue["SuppressSpecialTokens"], suppressTokens, OptionValue["IncludeTimestamps"], tStampCode, True, {}]];
If[SameQ[index, 1], noSpeech = (probs[[noSpeechCode]] > noSpeechThresh)];
If[isGenerating,
AppendTo[generated, token];
AppendTo[logProbs, token -> Log[probs][[token]]]
];
Join[
KeyMap[StringReplace["OutState" -> "State"], KeyDrop[netOut, NetPort[{"softmax", "Output"}]]],
<|"Index" -> ++index,
"Input1" -> If[isGenerating, token, prompt[[index]]],
"Input2" -> features|>
]
],
init,
#Input1 =!= eosCode &,
1,
OptionValue[MaxIterations] + Length[prompt]
];
(*compute the mean log probabilities*)
avgLogProb = Mean@Values[KeyDrop[logProbs, eosCode]];
(*remove eos token*)
If[Last[generated] === eosCode,
generated = Most[generated]
];
(*Return the generated tokens, noSpeech probability and mean log probabilities*)
{generated, noSpeech, avgLogProb}
]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/3f34ec699500550d.png)
![(*Define needsFallbackQ function*)
fallbackQ[noSpeech_, compressionRatio_, compressionRatioThresh_, avgLogProb_, logProbThresh_] := Which[
And[noSpeech, avgLogProb < logProbThresh], False,(*Silent*)
avgLogProb < logProbThresh, True,(*average log probability is too low*)
compressionRatio > compressionRatioThresh, True (*too repetitive*),
True, False
];
(*Define compressionRatioF function*)
compressionRatio[tokens_, labels_] := With[
{textBytes = StringToByteArray[StringJoin@labels[[tokens]], "UTF-8"]},
N@Length[textBytes]/StringLength[Compress[textBytes]]
];
(*Define decodeWithFallback function*)
Options[decodeWithFallback] = {"IncludeTimestamps" -> False, "SuppressSpecialTokens" -> False, "LogProbabilityThreshold" -> -1, "CompressionRatioThreshold" -> 9.2, "Temperature" -> 0, MaxIterations -> 224, TargetDevice -> "CPU"};
decodeWithFallback[features_, textDecoder_, initStates_, outPorts_, labels_, prev_, opts : OptionsPattern[]] := Module[{tokens, noSpeech, avgLogProb, compressRatio, outPortst, needsFallback = True, temperatures, i = 1},
temperatures = Range[OptionValue["Temperature"], 1, 0.2];
(*if needsFallback is True iterate over different temperatures*)
While[i <= Length[temperatures],
{tokens, noSpeech, avgLogProb} = generate[features, prev, textDecoder, initStates, outPorts, "IncludeTimestamps" -> OptionValue["IncludeTimestamps"], "SuppressSpecialTokens" -> OptionValue["SuppressSpecialTokens"],
"Temperature" -> temperatures[[i]], MaxIterations -> OptionValue[MaxIterations], TargetDevice -> OptionValue[TargetDevice]];
(*update iterator*)
i++;
(*update needsFallback*)
compressRatio = compressionRatio[tokens, labels];
needsFallback = fallbackQ[noSpeech, compressRatio, OptionValue["CompressionRatioThreshold"], avgLogProb, OptionValue["LogProbabilityThreshold"]];
If[! needsFallback, Break[]];
];
tokens (*return the generated tokens for this chunk*)
];](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/21a3fe1d1f1c7d14.png)
![Options[netevaluate] = {"Size" -> "Tiny", "IncludeTimestamps" -> False, "SuppressSpecialTokens" -> False, "Temperature" -> 0, "LogProbabilityThreshold" -> -1, "CompressionRatioThreshold" -> 2.4, MaxIterations -> 224, TargetDevice -> "CPU"};
netevaluate[audio_ : (_?AudioQ), opts : OptionsPattern[]] := Module[{aud, audioEncoder, textDecoder, labels, audioFeatures, outPorts, generated, initStates, prev = {}},
(*split the audion into 30 second smaller segments*)
aud = AudioPartition[audio, 30];
(*Obtain encoder-
decoder models*){audioEncoder, textDecoder} = NetModel[{"Whisper-V1 Nets", "Size" -> OptionValue["Size"], "Part" -> #}] & /@ {"AudioEncoder", "TextDecoder"};
(*Get labels*)
labels = NetModel["Whisper-V1 Nets", "Labels"];
(*Obtain audio features*)
audioFeatures = audioEncoder[aud];
(*Get output port names*)
outPorts = Append[NetPort /@ Information[textDecoder, "OutputPortNames"], NetPort[{"softmax", "Output"}]];
(*Define initial states*)
initStates = AssociationMap[Function[x, {}], Select[Information[textDecoder, "InputPortNames"], StringStartsQ["State"]]]; (*Map over 30s segment audio features*)
generated = Join @@ Map[
(prev = decodeWithFallback[#, textDecoder, initStates, outPorts, labels, prev, "IncludeTimestamps" -> OptionValue["IncludeTimestamps"], "SuppressSpecialTokens" -> OptionValue["SuppressSpecialTokens"], "LogProbabilityThreshold" -> OptionValue["LogProbabilityThreshold"], "CompressionRatioThreshold" -> OptionValue["CompressionRatioThreshold"], "Temperature" -> OptionValue["Temperature"], MaxIterations -> OptionValue[MaxIterations], TargetDevice -> OptionValue[TargetDevice]
]) &,
audioFeatures
];
(*Convert generated token IDs back to text*)
StringJoin@labels[[generated]]
]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/2b1a81e48bea4d23.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/06746a0f-a39a-4bf5-b3d7-27da99413681"]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/699681d1fea5e6d1.png)

![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/f3391a39-8f16-4fca-8be3-dd9b43d4aa7a"]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/1a776bf06f58df18.png)
![audios = <|"Bird" -> ExampleData[{"Audio", "Bird"}], "Bee" -> ExampleData[{"Audio", "Bee"}], "Scream" -> ExampleData[{"Audio", "Scream"}], "ChurchBell" -> ExampleData[{"Audio", "ChurchBell"}], "Laughing" -> ExampleData[{"Audio", "Laughing"}], "DogBark" -> ExampleData[{"Audio", "DogBark"}], "Crowd" -> ExampleData[{"Audio", "Crowd"}]|>](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/4f8c8da0f359b32c.png)

![Dataset[KeyValueMap[
Association[{"Audio Name" -> Style[#1, Bold], "Whisper Transcription" -> #2}] &, transcriptions]]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/4b66689347afb750.png)
![audio = AudioPad[ResourceData["Sample Audio: Apollo 11 One Small Step"],
30 - Min[30, QuantityMagnitude[Duration[audio]]]]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/7dff88a875d11c7d.png)
![GraphicsColumn[{
AudioPlot[audio, PlotRange -> {0, 5}, PlotLabel -> "Audio Waveform",
FrameTicks -> None, ImageSize -> {300, 100}],
MatrixPlot[logMelSpectrogram, PlotLabel -> "Log-mel Spectrogram", ColorFunction -> "Rainbow", FrameTicks -> None, ImageSize -> {300, 100}, PlotRange -> {{0, 80}, {0, 500}}]}, ImageSize -> Medium]](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/41278e279025cc6f.png)
![index = 1;
sosCode = 50258;
init = Join[
<|"Index" -> index,
"Input1" -> sosCode,
"Input2" -> audioFeatures
|>,
initStates
];](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/2d53b59271e7949f.png)
![eosCode = 50257;
tokens = {sosCode};
NestWhile[
Function[
netOut = textDecoder[#];
AppendTo[tokens, netOut["Output"]];
Join[
KeyMap[StringReplace["OutState" -> "State"], netOut] (*include last states*),
<|"Index" -> ++index, (*update index*)
"Input1" -> netOut["Output"], (*input last generated token*)
"Input2" -> audioFeatures (*audio features for transcription*)
|>
]
],
init,
#Input1 =!= eosCode &,(*stops when EndOfString token is generated*)
1,
100 (*Max iterations*)
];](https://www.wolframcloud.com/obj/resourcesystem/images/521/5211d691-293f-417d-a19f-f1e5faef3fb7/315e4b354d08ae37.png)