VGGish Feature Extractor
Trained on
YouTube Data
Released by Google in 2017, this model extracts 128-dimensional embeddings from ~1 second long audio signals. The model was trained on a large YouTube dataset (a preliminary version of what later became YouTube-8M).
Number of layers: 25 |
Parameter count: 72,141,184 |
Trained size: 289 MB |
Examples
Resource retrieval
Get the pre-trained net:
Basic usage
Extract semantic features from an Audio object:
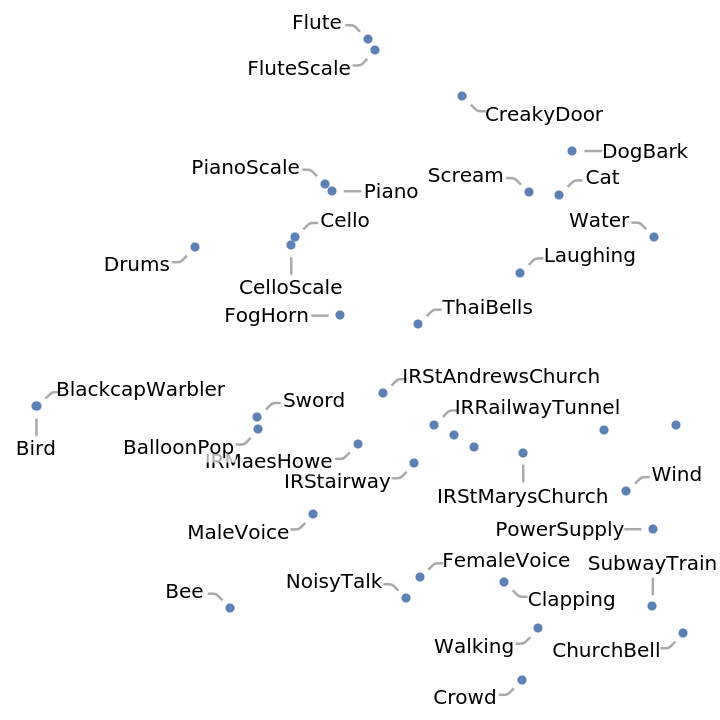
The extracted features are a sequence of 128-dimensional vectors of unsigned 8-bit integers. Visualize the relationship between the sounds using the network as a feature extractor:
The network output from the network itself is passed to a PCA transformation and a quantization step. To obtain the raw output of the net, remove the NetDecoder:
Extract the raw features:
Visualize the relationship between the sounds using the raw features as a feature extractor:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
Represent the MXNet net as a graph:
Requirements
Wolfram Language
12.0
(April 2019)
or above
Resource History
Reference
-
S. Hershey, S. Chaudhuri, D. P. W. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney, R. J. Weiss, K. Wilson, "CNN Architectures for Large-Scale Audio Classification," arXiv:1609.09430 (2017)
- Available from: https://github.com/tensorflow/models/tree/master/research/audioset
-
Rights:
Apache 2.0 License

![FeatureSpacePlot[
Callout[ExampleData[#], #[[2]]] & /@ ExampleData["Audio"], FeatureExtractor -> NetModel["VGGish Feature Extractor Trained on YouTube Data"], LabelingFunction -> None]](https://www.wolframcloud.com/obj/resourcesystem/images/511/511fdfe6-752a-43fc-98cd-b763a5509251/0174fb75f241419f.png)