NuTopic Text Feature Extractor
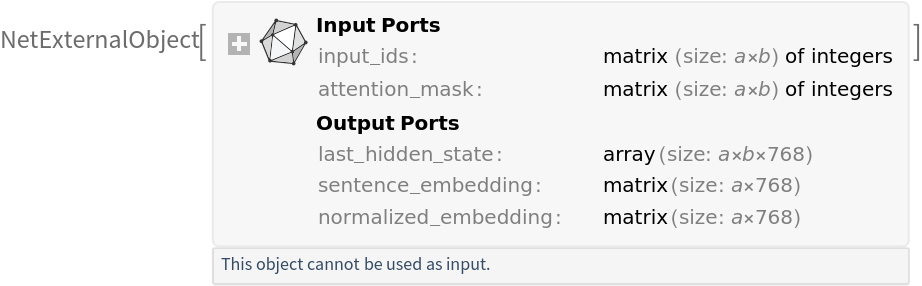
Released in 2024, NuTopic is a BERT-based transformer encoder from NuMind designed for topic-classification feature extraction. Publicly available configuration files indicate that it is built on top of the E5-base-v2 text-embedding architecture, with 12 layers, a hidden size of 768 and a maximum sequence length of 512. The model produces contextual text representations intended to capture topic-related properties of language for downstream applications.
Examples
Resource retrieval
Get the pre-trained net:
Evaluation function
Get the tokenizer to process text inputs into tokens:
Write a function that preprocesses a list of input sentences:
Write a function that applies mean pooling to the hidden states:
Write a function that returns one of the requested outputs from the NuTopic encoder (last hidden state, sentence and normalized embeddings) and optionally trims padding tokens using the "attention_mask" when the optional parameter "ApplyMask" is set to True:
Basic usage
Get the sentence embedding:
Get the dimensions of the output:
Get the sentences:
Get the sentence embeddings using "NormalizedEmbedding":
Get the dimensions of the output:
Get the scores from the output's embeddings:
Input preprocessing
Preprocess a batch of sentences into inputs expected by the model. The result is an association:
• "input_ids": integer token indices
• "attention_mask": a binary mask indicating valid tokens vs. padding tokens
Get the dimensions of the preprocessed sentences:
Visualize the preprocessed sentences:
Get the sentence embeddings:
Get the dimensions of the outputs:
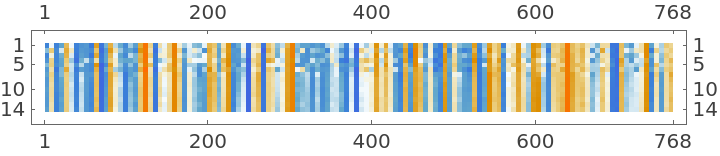
Visualize the first sentence embedding:
The sentence embedding is the normalized average of all non-padded token representations:
Advanced usage
One-shot learning
Get a list of classes with one example sentence for each:
Get a set of sentences to classify and their correct labels:
Get the embeddings of the labels and test sentences:
Get the predictions. Since all of the embeddings are normalized, SquaredEuclideanDistance, which is equivalent (up to a constant factor) to cosine distance, is used here:
Create a table to visualize the correct and predicted label for each sentence:
Transfer learning
Topic classification
Perform topic classification on the DBpedia dataset, where each input sentence is classified into one of 14 ontology-based classes. Texts are encoded using NuTopic Text Feature Extractor sentence embeddings and a simple classifier is trained on top of these embeddings.
Get the dataset:
Get the label mapping:
Preprocess the dataset:
Define the classifier model for topic classification, which accepts the embeddings as input and outputs the probabilities for each class of labelMap:
Extract the training datasets from the initial data:
Train the classifier:
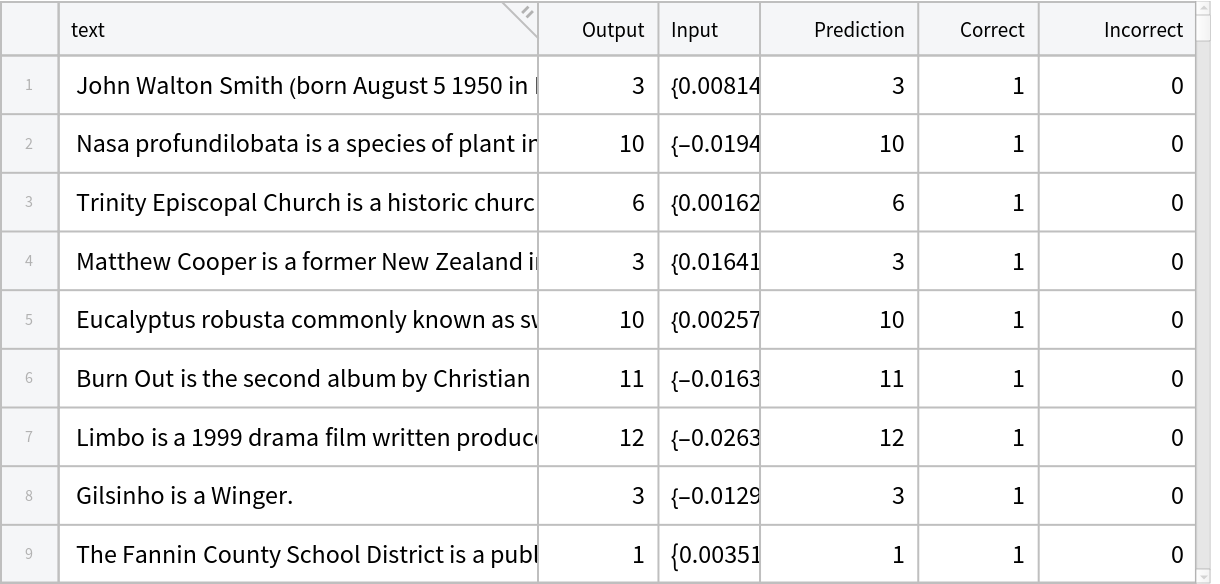
Run the classifier on the embeddings obtained by the NuTopic model using test sentences and categorize the results into "Correct" and "Incorrect" predictions:
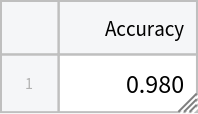
Compute the accuracy:
Create a unified pipeline by merging the classifier and NuTopic:
Show the results:
Resource History
Reference
-
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, F. Wei, "Text Embeddings by Weakly-Supervised Contrastive Pre-training," arXiv:2212.03533v1 (2022)
- Available from: https://huggingface.co/numind/NuTopic
-
Rights:
MIT License

![prepareBatch[inputStrings_?ListQ] := Block[
{tokens, attentionMask},
tokens = tokenizer[inputStrings] - 1;
attentionMask = PadRight[ConstantArray[1, Length[#]] & /@ tokens, Automatic];
tokens = PadRight[tokens, Automatic, 1];
<|
"input_ids" -> tokens, "attention_mask" -> attentionMask
|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/4b1/4b1e89cd-5d59-4741-a031-25f4fb57e6a9/5a9c82a39c017a88.png)
![Options[netevaluate] = {"ApplyMask" -> False}; netevaluate[input_?StringQ, output : ("LastHiddenState" | "SentenceEmbedding" | "NormalizedEmbedding" | "MeanPooling") : "MeanPooling", opts : OptionsPattern[]] := If[output === "NetOutputs", First /@ netevaluate[{input}, output, opts], First@netevaluate[{input}, output, opts]];
netevaluate[inputStrings_?ListQ, output : ("LastHiddenState" | "SentenceEmbedding" | "NormalizedEmbedding" | "MeanPooling") : "MeanPooling", opts : OptionsPattern[]] := Module[
{assoc, out, h, mask, pooled},
assoc = prepareBatch[inputStrings];
mask = assoc["attention_mask"];
out = NetModel["NuTopic Text Feature Extractor"][assoc];
Switch[output,
"LastHiddenState",
h = out["last_hidden_state"];
If[TrueQ@OptionValue["ApplyMask"], MapThread[Take, {h, Total /@ mask}], h], "SentenceEmbedding",
out["sentence_embedding"], "NormalizedEmbedding",
out["normalized_embedding"], "MeanPooling",
h = out["last_hidden_state"];
pooled = meanPooler[h, mask];
Normalize /@ pooled,
"NetOutputs",
out
]
];](https://www.wolframcloud.com/obj/resourcesystem/images/4b1/4b1e89cd-5d59-4741-a031-25f4fb57e6a9/3c7ba0c6b9def081.png)







![i = 0; Monitor[
encodeddata = Select[TransformColumns[data, "Input" -> Function[i++; Quiet@Check[
Normal@netevaluate[("query: " <> #text)], $Failed]]], #Input =!= $Failed &], ProgressIndicator[i/Length[data]]]](https://www.wolframcloud.com/obj/resourcesystem/images/4b1/4b1e89cd-5d59-4741-a031-25f4fb57e6a9/32149c410a3cc2ab.png)
![resultsData = TransformColumns[testData, "Prediction" -> Function[trainedClassifier[#Input]]] // TransformColumns[{
"Correct" -> (Boole[#Prediction == #Output] &),
"Incorrect" -> (Boole[#Prediction != #Output] &)
}]](https://www.wolframcloud.com/obj/resourcesystem/images/4b1/4b1e89cd-5d59-4741-a031-25f4fb57e6a9/20575cd8343bc5e4.png)