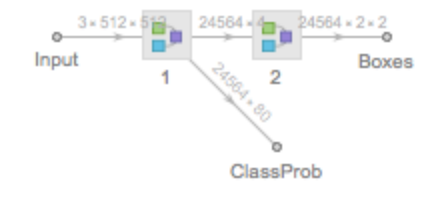
SSD-VGG-300
Trained on
PASCAL VOC Data
Released in 2016, this model discretizes the output space of bounding boxes into a set of default boxes. At the time of prediction, scores are generated for each object and multiple feature maps with different resolutions are used to make predictions for objects of various sizes. This model processes images at 59 FPS on a NVIDIA Titan X.
Number of layers: 145 |
Parameter count: 27,076,694 |
Trained size: 109 MB |
Examples
Resource retrieval
Get the pre-trained net:
Evaluation function
Write an evaluation function to scale the result to the input image size and suppress the least probable detections:
Define the label list for this model. Integers in the model's output correspond to elements in the label list:
Basic usage
Obtain the detected bounding boxes with their corresponding classes and confidences for a given image:
Inspect which classes are detected:
Visualize the detection:
Network result
The network computes 8,732 bounding boxes and the probability that the objects in each box are of any given class:
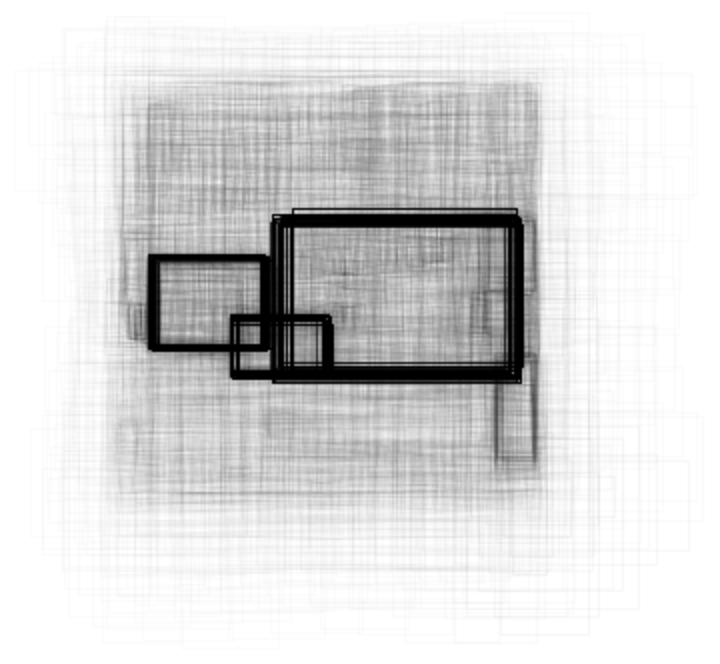
Visualize all the boxes predicted by the net scaled by their “objectness” measures:
Visualize all the boxes scaled by the probability that they contain a bus:
Superimpose the bus prediction on top of the scaled input received by the net:
Advanced visualization
Write a function to apply a custom styling to the result of the detection:
Visualize multiple objects, using a different color for each class:
Net information
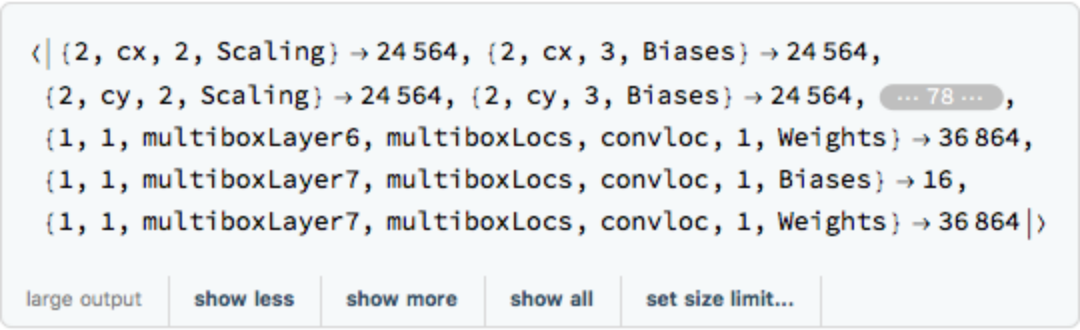
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
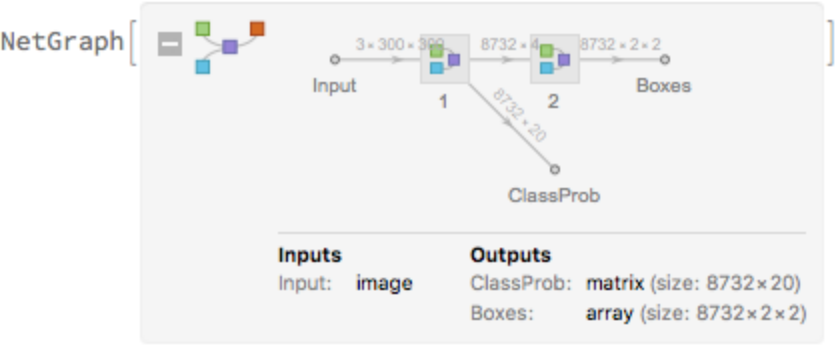
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:
Requirements
Wolfram Language
11.3
(March 2018)
or above
Resource History
Reference
![nonMaxSuppression[overlapThreshold_][detection_] := Module[{boxes, confidence}, Fold[{list, new} |-> If[NoneTrue[list[[All, 1]], iou[#, new[[1]]] > overlapThreshold &], Append[list, new], list], Sequence @@ TakeDrop[Reverse@SortBy[detection, Last], 1]]]
iou := iou = With[{c = Compile[{{box1, _Real, 2}, {box2, _Real, 2}}, Module[{area1, area2, x1, y1, x2, y2, w, h, int}, area1 = (box1[[2, 1]] - box1[[1, 1]]) (box1[[2, 2]] - box1[[1, 2]]);
area2 = (box2[[2, 1]] - box2[[1, 1]]) (box2[[2, 2]] - box2[[1, 2]]);
x1 = Max[box1[[1, 1]], box2[[1, 1]]];
y1 = Max[box1[[1, 2]], box2[[1, 2]]];
x2 = Min[box1[[2, 1]], box2[[2, 1]]];
y2 = Min[box1[[2, 2]], box2[[2, 2]]];
w = Max[0., x2 - x1];
h = Max[0., y2 - y1];
int = w*h;
int/(area1 + area2 - int)], RuntimeAttributes -> {Listable}, Parallelization -> True, RuntimeOptions -> "Speed"]}, c @@ Replace[{##}, Rectangle -> List, Infinity, Heads -> True] &]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/78d45b138523f0cc.png)

![netevaluate[img_Image, detectionThreshold_ : .5, overlapThreshold_ : .45] := Module[{netOutputDecoder, net},
netOutputDecoder[imageDims_, threshold_ : .5][netOutput_] := Module[{detections = Position[netOutput["ClassProb"], x_ /; x > threshold]}, If[Length[detections] > 0, Transpose[{Rectangle @@@ Round@Transpose[
Transpose[
Extract[netOutput["Boxes"], detections[[All, 1 ;; 1]]], {2, 3, 1}]*
imageDims/{300, 300}, {3, 1, 2}], Extract[labels, detections[[All, 2 ;; 2]]],
Extract[netOutput["ClassProb"], detections]}],
{}
]
];
net = NetModel["SSD-VGG-300 Trained on PASCAL VOC Data"];
(Flatten[
nonMaxSuppression[overlapThreshold] /@ GatherBy[#, #[[2]] &], 1] &)@netOutputDecoder[ImageDimensions[img], detectionThreshold]@(net@(ImageResize[#, {300, 300}] &)@img)
]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/7299eb5bfd449bc7.png)
![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/10e91fac-61c1-41c7-9474-c3152636da92"]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/1279e8ab45a372b1.png)

![HighlightImage[testImage, MapThread[{White, Inset[Style[#2, Black, FontSize -> Scaled[1/12], Background -> GrayLevel[1, .6]], Last[#1], {Right, Top}], #1} &,
Transpose@detection]]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/78cbbd773e96e62d.png)


![Graphics[
MapThread[{EdgeForm[Opacity[#1 + .01]], #2} &, {Total[
res["ClassProb"], {2}], rectangles}],
BaseStyle -> {FaceForm[], EdgeForm[{Thin, Black}]}
]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/4d7a85451dbda31d.png)
![Graphics[
MapThread[{EdgeForm[Opacity[#1 + .01]], #2} &, {res["ClassProb"][[
All, idx]], rectangles}],
BaseStyle -> {FaceForm[], EdgeForm[{Thin, Black}]}
]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/776a78a57332f7c7.png)
![HighlightImage[ImageResize[testImage, {300, 300}], Graphics[MapThread[{EdgeForm[{Opacity[#1 + .01]}], #2} &, {res[
"ClassProb"][[All, idx]], rectangles}]], BaseStyle -> {FaceForm[], EdgeForm[{Thin, Red}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/27ad608ab296da40.png)

![styleDetection[
detection_] := {RandomColor[], {#[[1]], Text[Style[#[[2]], White, 12], {20, 20} + #[[1, 1]], Background -> Black]} & /@ #} & /@ GatherBy[detection, #[[2]] &]](https://www.wolframcloud.com/obj/resourcesystem/images/483/48388bf5-0ca5-4019-872a-f524f1ecc22b/6f94f2ee5dd262d4.png)