Wolfram Neural Net Repository
Immediate Computable Access to Neural Net Models
Represent text as a sequence of vectors
Released in 2023, NuToxicity is a BERT-based transformer encoder from NuMind designed for content-moderation feature extraction. It is publicly distributed as a feature-extraction model and is built on top of the E5-base-v2 text-embedding architecture. The public configuration indicates a 12-layer encoder with a hidden size of 768 and a maximum sequence length of 512. The model can be used to obtain contextual token representations and sentence-level embeddings for downstream moderation applications.
Get the pre-trained net:
| In[1]:= |
| Out[1]= | 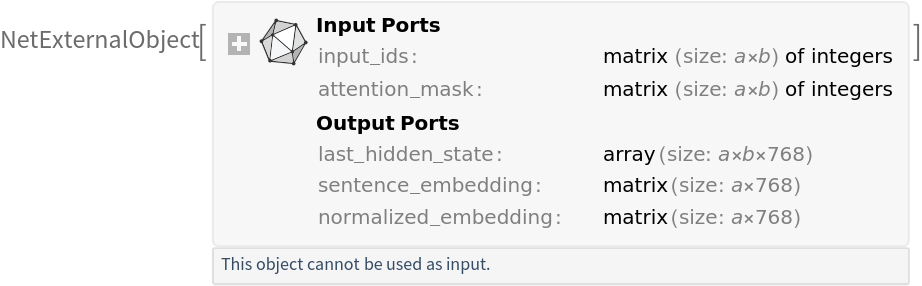 |
Get the tokenizer to process text inputs into tokens:
| In[2]:= |
| Out[2]= |  |
Write a function that preprocesses a list of input sentences:
| In[3]:= | ![prepareBatch[inputStrings_?ListQ] := Block[
{tokens, attentionMask},
tokens = tokenizer[inputStrings] - 1;
attentionMask = PadRight[ConstantArray[1, Length[#]] & /@ tokens, Automatic];
tokens = PadRight[tokens, Automatic, 1];
<|
"input_ids" -> tokens, "attention_mask" -> attentionMask
|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/40d/40db4a8d-4c27-4208-8e41-c6ab50d0ed30/4fc6c7529343e90d.png) |
Write a function that applies mean pooling to the hidden states:
| In[4]:= |
Write a function that returns one of the requested outputs from the NuToxicity encoder (last hidden state, sentence and normalized embeddings) and optionally trims padding tokens using the "attention_mask" when the optional parameter "ApplyMask" is set to True:
| In[5]:= | ![Options[netevaluate] = {"ApplyMask" -> False}; netevaluate[input_?StringQ, output : ("LastHiddenState" | "SentenceEmbedding" | "NormalizedEmbedding" | "MeanPooling") : "MeanPooling", opts : OptionsPattern[]] := If[output === "NetOutputs", First /@ netevaluate[{input}, output, opts], First@netevaluate[{input}, output, opts]];
netevaluate[inputStrings_?ListQ, output : ("LastHiddenState" | "SentenceEmbedding" | "NormalizedEmbedding" | "MeanPooling") : "MeanPooling", opts : OptionsPattern[]] := Module[
{assoc, out, h, mask, pooled},
assoc = prepareBatch[inputStrings];
mask = assoc["attention_mask"];
out = NetModel["NuToxicity Text Feature Extractor"][assoc];
Switch[output,
"LastHiddenState",
h = out["last_hidden_state"];
If[TrueQ@OptionValue["ApplyMask"], MapThread[Take, {h, Total /@ mask}], h], "SentenceEmbedding",
out["sentence_embedding"], "NormalizedEmbedding",
out["normalized_embedding"], "MeanPooling",
h = out["last_hidden_state"];
pooled = meanPooler[h, mask];
Normalize /@ pooled,
"NetOutputs",
out
]
];](https://www.wolframcloud.com/obj/resourcesystem/images/40d/40db4a8d-4c27-4208-8e41-c6ab50d0ed30/6c0dec338e5a98e3.png) |
Get the sentence embedding:
| In[6]:= |
Get the dimensions of the output:
| In[7]:= |
| Out[7]= |
Get the sentences:
| In[8]:= |  |
Get the sentence embeddings using "NormalizedEmbedding":
| In[9]:= |
Get the dimensions of the output:
| In[10]:= |
| Out[10]= |
Get the scores from the output's embeddings:
| In[11]:= |
| Out[11]= |
Preprocess a batch of sentences into inputs expected by the model. The result is an association:
• "input_ids": integer token indices
• "attention_mask": a binary mask indicating valid tokens vs. padding tokens
| In[12]:= |
Get the dimensions of the preprocessed sentences:
| In[13]:= |
| Out[13]= |
Visualize the preprocessed sentences:
| In[14]:= |
| Out[14]= |
Get the sentence embeddings:
| In[15]:= |
Get the dimensions of the outputs:
| In[16]:= |
| Out[16]= |
Visualize the first sentence embedding:
| In[17]:= |
| Out[17]= | 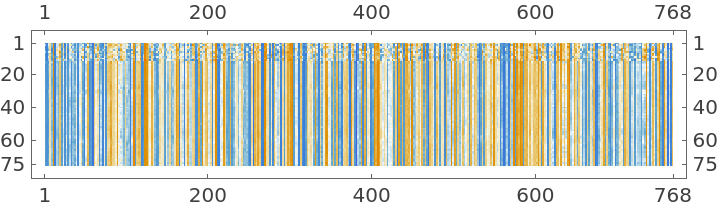 |
The sentence embedding is the normalized average of all non-padded token representations:
| In[18]:= |
| Out[18]= |
Get the sentences:
| In[19]:= |  |
Get the embeddings of the sentences by taking the mean of the features of the tokens for each sentence:
| In[20]:= |
Compute the pairwise distance matrix between the sentence embeddings:
| In[21]:= |
Define shorter labels for the plot axes:
| In[22]:= |
Use numbered labels on the horizontal axis and numbered short labels on the vertical axis:
| In[23]:= |
Visualize the pairwise distances between the sentence embeddings:
| In[24]:= |
| Out[24]= | 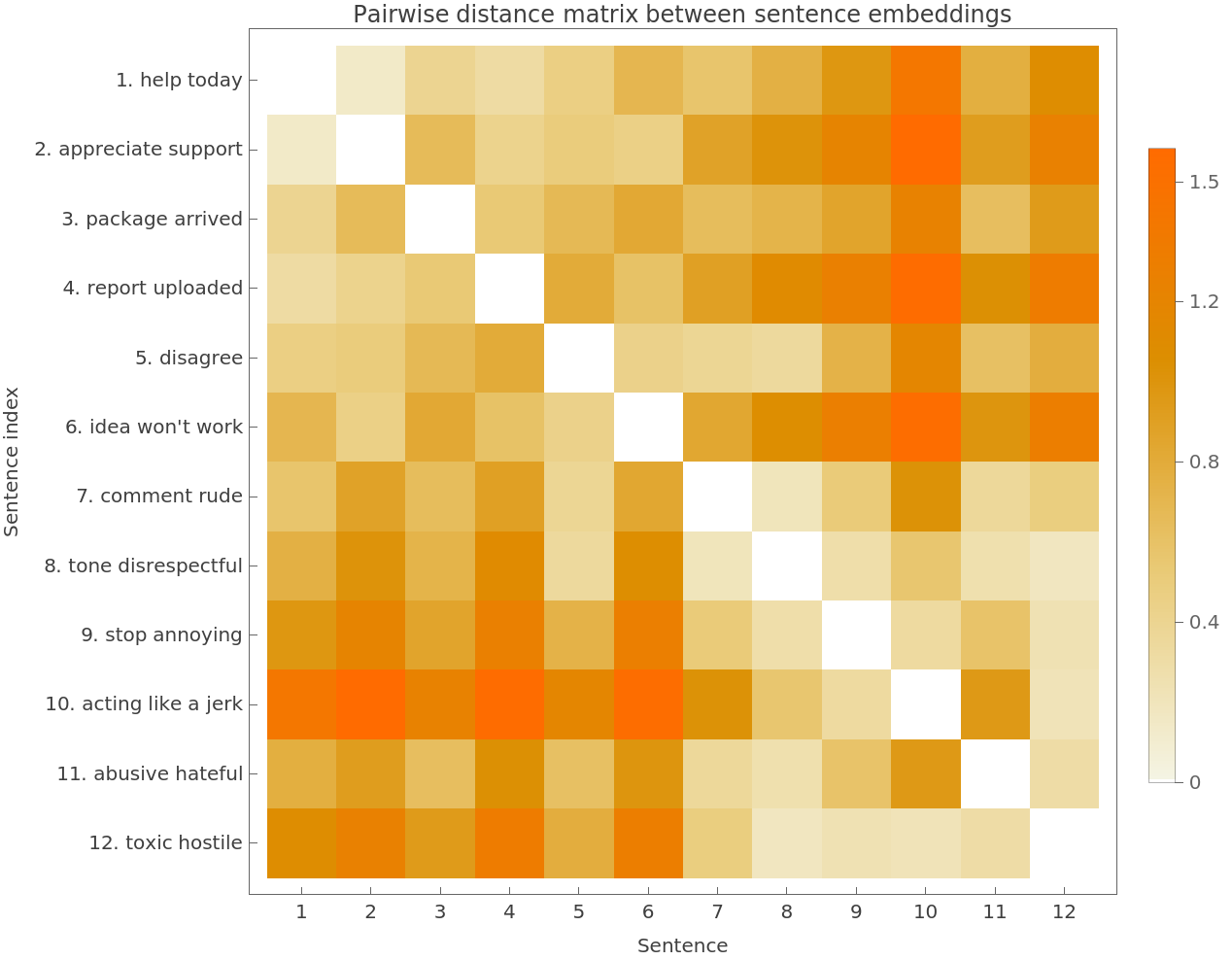 |
Get a list of classes with one example sentence for each:
| In[25]:= |  |
Get a set of sentences to classify and their correct labels:
| In[26]:= |  |
Get the embeddings of the labels and test sentences:
| In[27]:= |
Get the predictions. Since all of the embeddings are normalized, SquaredEuclideanDistance, which is equivalent (up to a constant factor) to cosine distance, is used here:
| In[28]:= |
Create a table to visualize the correct and predicted label for each sentence:
| In[29]:= |
| Out[29]= |  |
Perform content moderation classification on the Jigsaw Toxic Comment Classification Challenge dataset, which contains Wikipedia comments labeled as toxic behavior. For this example, the original annotations are reduced to three classes, and texts are encoded using NuToxicity Text Feature Extractor sentence embeddings. A simple classifier is then trained on top of these embeddings.
Get the Jigsaw Toxic Comment Classification Challenge dataset (via a Hugging Face mirror of the original Kaggle release). The underlying text is derived from Wikipedia talk pages and is licensed under the Creative Commons Attribution-ShareAlike 3.0 (CC BY-SA 3.0) license:
| In[30]:= |
| Out[30]= |  |
Preprocess the dataset:
| In[31]:= | ![i = 0; Monitor[
encodeddata = Select[TransformColumns[data, "Input" -> Function[i++; Quiet@Check[
Normal@netevaluate[("query: " <> #text)], $Failed]]], #Input =!= $Failed &], ProgressIndicator[i/Length[data]]]](https://www.wolframcloud.com/obj/resourcesystem/images/40d/40db4a8d-4c27-4208-8e41-c6ab50d0ed30/21dae52a7b3c1dc5.png) |
| Out[31]= | 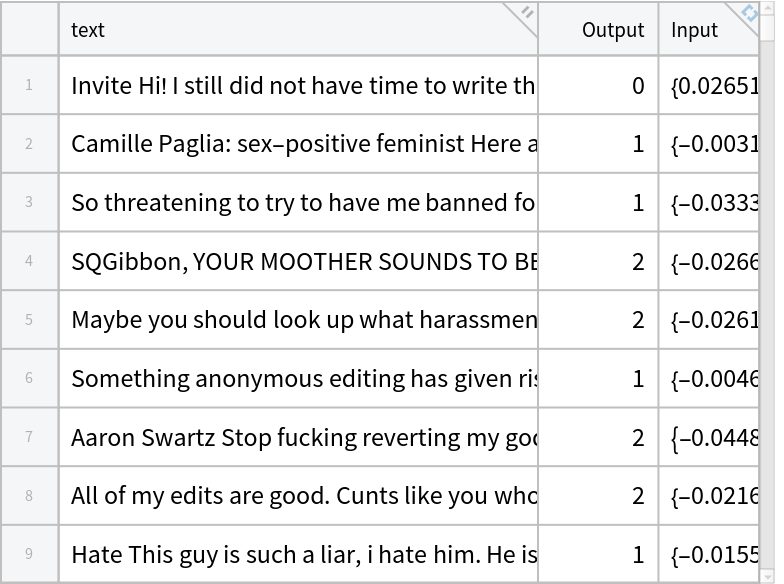 |
Define the classifier model for content moderation classification, which accepts the embeddings as input and outputs the probabilities for each class (benign, toxic, severe):
| In[32]:= |
| Out[33]= |
Extract the training datasets from the initial data:
| In[34]:= |
Train the classifier:
| In[35]:= |
| Out[35]= |
Run the classifier on the embeddings obtained by the NuToxicity model using test sentences and categorize the results into "Correct" and "Incorrect" predictions:
| In[36]:= | ![resultsData = TransformColumns[testData, "Prediction" -> Function[trainedClassifier[#Input]]] // TransformColumns[{
"Correct" -> (Boole[#Prediction == #Output] &),
"Incorrect" -> (Boole[#Prediction != #Output] &)
}]](https://www.wolframcloud.com/obj/resourcesystem/images/40d/40db4a8d-4c27-4208-8e41-c6ab50d0ed30/0bc3b35a33ab8163.png) |
| Out[36]= | 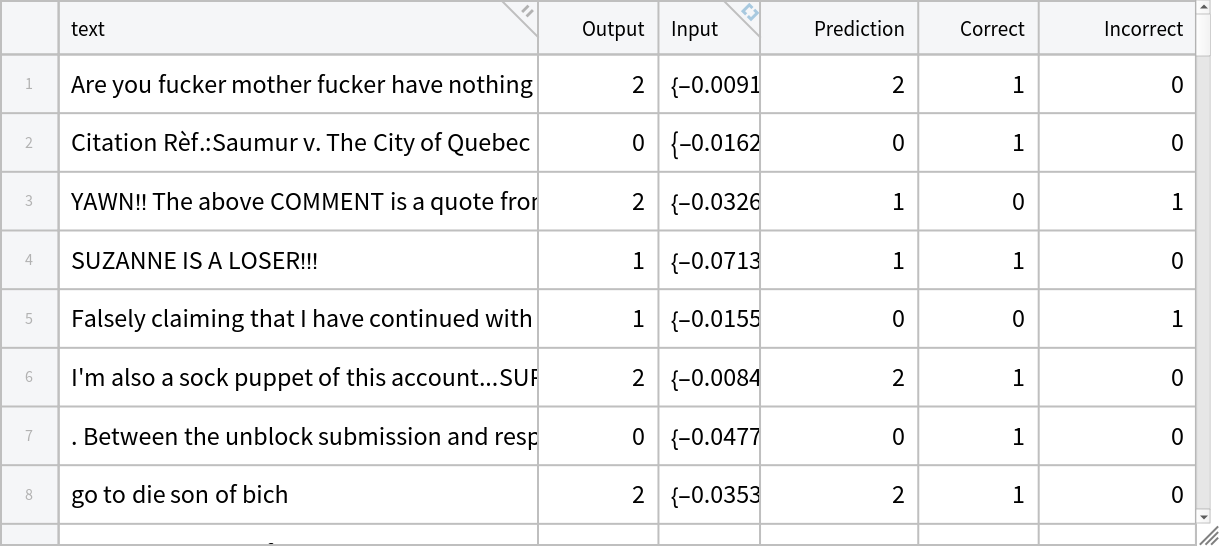 |
Compute the accuracy:
| In[37]:= |
| Out[37]= | 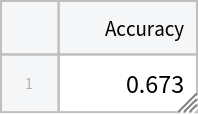 |
Create a unified pipeline by merging the classifier and NuToxicity:
| In[38]:= | ![toxicityModel = NetReplacePart[
trainedClassifier, {"Input" -> NetEncoder[{"Function", netevaluate[#] &, 768, SaveDefinitions -> False}], "Output" -> NetDecoder[{"Class", {"Benign", "Toxic", "Severe"}}]}]](https://www.wolframcloud.com/obj/resourcesystem/images/40d/40db4a8d-4c27-4208-8e41-c6ab50d0ed30/4e805666754f5072.png) |
| Out[38]= |
Show the results:
| In[39]:= |  |
| Out[39]= |