Resource retrieval
Get the pre-trained net:
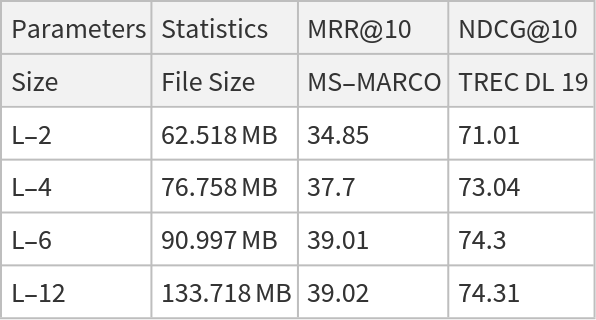
NetModel parameters
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
Pick a non-default net by specifying the parameters:
Evaluation function
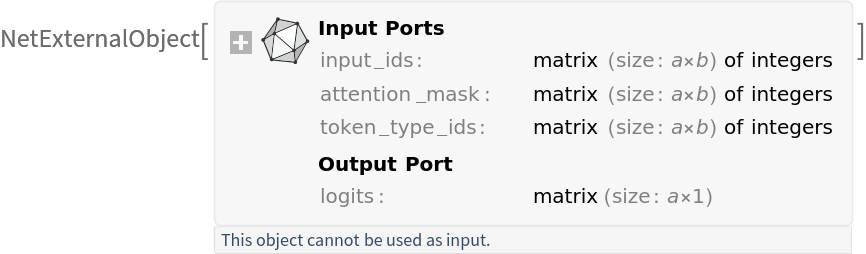
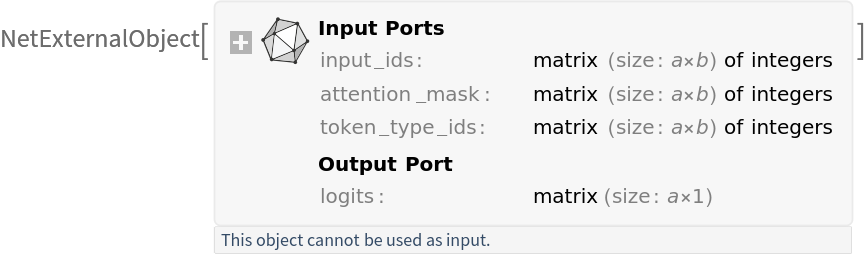
Get the tokenizer:
Write a function that preprocesses a list of input sentences:
Write a function that incorporates all the steps from tokenizing the input string up to outputting the scores:
Basic usage
Get the question and the sentences:
Get the scores for a given question for each sentence:
Get the scores for a given question for each sentence using a non-default model:
Input preprocessing
Preprocess a batch of sentences into inputs expected by a model. The result is an association:
• "input_ids": integer token indices representing each token of the concatenated question-sentence pairs
• "attention_mask": binary mask indicating valid tokens vs. padding tokens
• "token_type_ids": segment IDs used for sentence pair tasks showing which sentence each token belongs to (here 0 for the question and 1 for the sentence)
Get the dimensions of the preprocessed pairs of the sentences:
Visualize the preprocessed sentences:
Get the scores from the pairs of sentences:
Reranker-only document retrieval
The reranker model directly evaluates the joint relationship between a query and each document by concatenating them and producing a single relevance score. This full query-document interaction provides high accuracy, but because reranker scores cannot be precomputed and must be recalculated for every pair, applying it to all documents is computationally expensive and scales poorly. Therefore, this approach is best suited for small corpora. First, get the documents:
Split the input data into individual sentences to use each as a separate passage:
Get the query:
Run the reranker directly on all documents and get the scores from the pairs of sentences with recorded time:
Get the top-K relevant answers for the given query with the corresponding relevance score:
Show the results:
Embedding-only document retrieval
In large-scale information retrieval, processing every document with a reranker for each query is infeasible. To handle this efficiently, a text embedder encodes each document into a dense vector representation and stores these embeddings for reuse. At query time, the user query is encoded into the same vector space, and the system retrieves the most semantically similar documents based on vector distances. This approach enables fast and scalable retrieval with minimal latency. First, define the utility functions responsible for embedding extraction:
Evaluate the utility functions to compute embeddings for the query and all passages by recording the time:
Use the utility function to compute distance scores between the query embedding and all passage embeddings:
Get the top-K relevant answer for the given query with the corresponding distance score:
Show the results:
Record the overall runtime, excluding the document embedding step, since those embeddings are computed once and reused across queries:
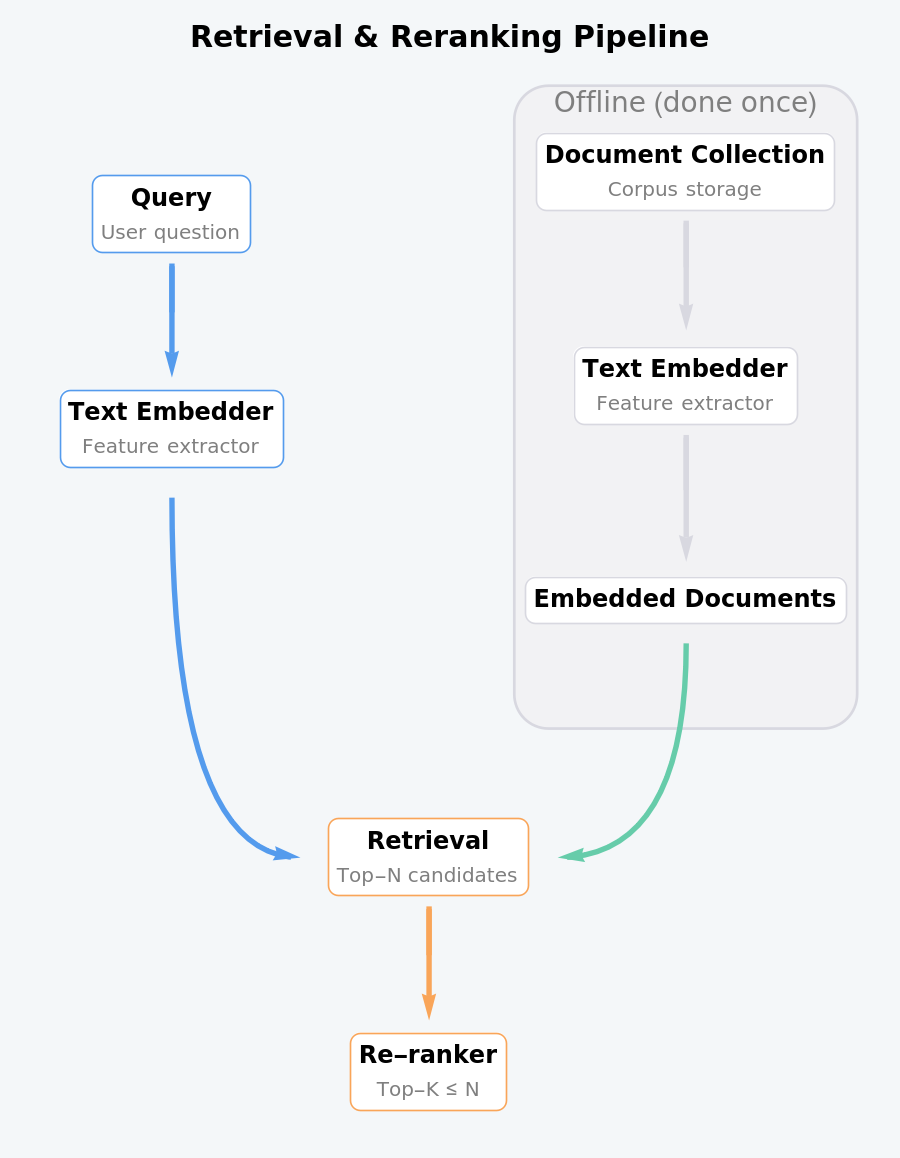
Two-stage document retrieval (embedding + reranker)
Two-stage retrieval first uses the fast embedder to fetch a small pool of top-N candidate documents and then applies the more accurate reranker only to those candidates. This keeps retrieval efficient while still benefiting from the reranker’s fine-grained relevance scoring. This process is summarized in the diagram:
Get the indices of the top-N closest passages by selecting the smallest distance values from all computed distance scores:
Run the reranker on the top-N most similar passages to get the relevance scores:
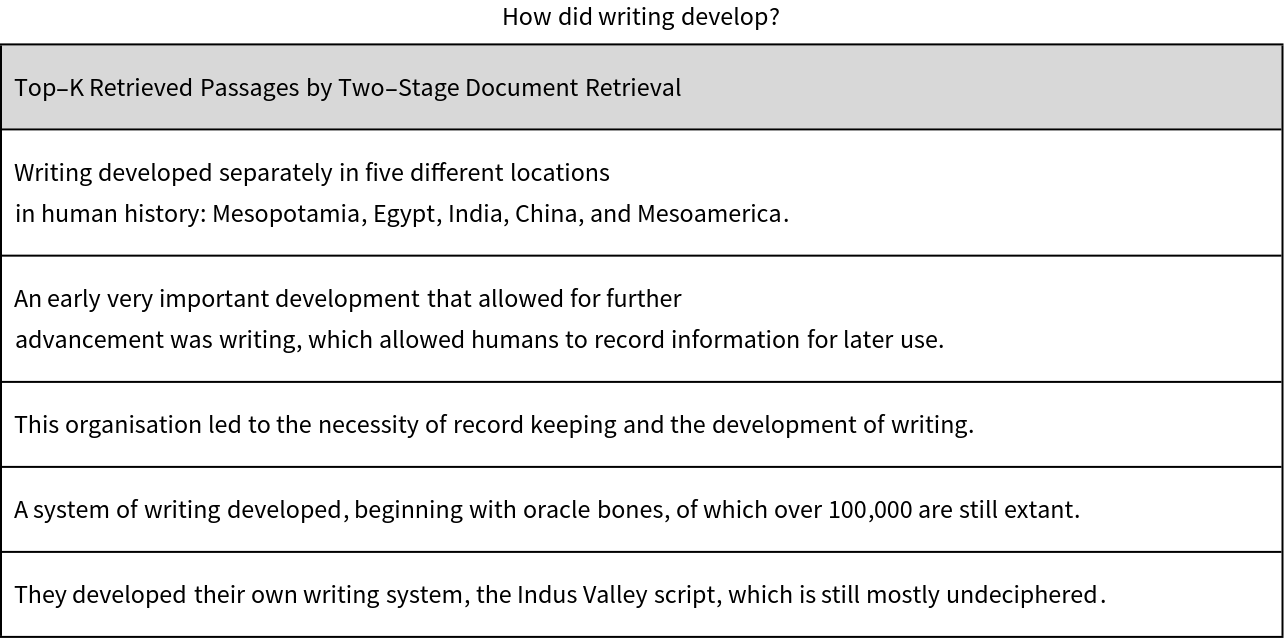
Get the top-K relevant answers for the given query with the corresponding relevance score:
Show the results:
Record the overall runtime, excluding the document embedding step, since those embeddings are computed once and reused across queries:
Timing summary
This section compares the total runtime across three retrieval strategies: embedding-only retrieval, reranker-only retrieval and two-stage retrieval. Each approach was evaluated on the same query and document set to measure their relative computational efficiency. Create an association for each retrieval method by storing the total runtime values and show the results:


![prepareBatch[inputQuery_? StringQ, inputDocuments_ ?ListQ, tokenizer_ : tokenizer] := Block[
{tokens, tokensQ, tokensD, pairs, attentionMask, tokenTypes},
{tokensQ, tokensD} = TakeDrop[tokenizer[Prepend[inputDocuments, inputQuery]], 1] - 1;
tokensQ = First@tokensQ;
tokens = Join[tokensQ, Rest[#]] & /@ tokensD;
tokens = PadRight[tokens, Automatic];
attentionMask = UnitStep[tokens - 1];
tokenTypes = Join[ConstantArray[0, {Length@tokensD, Length@tokensQ}], ConstantArray[1, Length@# - 1] & /@ tokensD, 2];
tokenTypes = PadRight[tokenTypes, Automatic];
<|
"input_ids" -> tokens, "attention_mask" -> attentionMask, "token_type_ids" -> tokenTypes
|>
];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/7f3d2071abeeaf92.png)
![Options[netevaluate] = {"Size" -> "L-6"};
netevaluate[inputQuery_? StringQ, inputDocuments_ ?ListQ, OptionsPattern[]] := Block[
{preprocessedAssoc, embeddings},
preprocessedAssoc = prepareBatch[inputQuery, inputDocuments];
embeddings = NetModel["MiniLM V2 Reranker Trained on MS MARCO Data", "Size" -> OptionValue["Size"]][preprocessedAssoc];
embeddings
];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/27f3e59b9f32af10.png)


![topK = 5;
{maxScoresRerankerOnly, topPassagesRerankerOnly} = Transpose@
TakeLargestBy[Transpose[{Flatten[outputsRerankerOnly], passages}], First, topK];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/7c0fe66612688626.png)
![Labeled[Grid[
Prepend[Transpose[{topPassagesRerankerOnly}], {"Top-K Retrieved Passages by Reranker-Only"}], Frame -> All, Background -> {None, {LightGray}}, Alignment -> Left, Spacings -> {1, 2}], query, Top]](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/2501f0748c41365d.png)

![embedder[inputStrings_ ?(StringQ[#] || VectorQ[#, StringQ] &), modelName_ : "Base", tokenizer_ : tokenizer] := Block[{embeddings, outputFeatures, tokens, attentionMask, tokenTypes, isString, input, meanPooler}, meanPooler[
PatternTest[
Pattern[vectors,
Blank[]], MatrixQ],
PatternTest[
Pattern[weights,
Blank[]], VectorQ]] := Mean[
WeightedData[vectors, weights]]; meanPooler[
PatternTest[
Pattern[vectors,
Blank[]], ArrayQ],
PatternTest[
Pattern[weights,
Blank[]], ArrayQ]] := MapThread[
meanPooler, {vectors, weights}]; isString = StringQ[
inputStrings]; input = If[
isString, {inputStrings}, inputStrings]; tokens = tokenizer[
input] - 1; attentionMask = PadRight[
Map[ConstantArray[1,
Length[#]]& , tokens], Automatic]; tokens = PadRight[
tokens, Automatic]; tokenTypes = ConstantArray[0,
Dimensions[tokens]]; embeddings = NetModel[
"MiniLM V2 Text Feature Extractor", "Part" -> modelName][<|"input_ids" -> tokens, "attention_mask" -> attentionMask, "token_type_ids" -> tokenTypes|>]; outputFeatures = meanPooler[
embeddings, attentionMask]; If[isString,
First[
Map[Normalize, outputFeatures]],
Map[Normalize, outputFeatures]]];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/7d9fe5e6e1b35f02.png)
![{timeEmbDist, distanceScores} = AbsoluteTiming[
First@DistanceMatrix[queryEmbedding, passagesEmbeddings, DistanceFunction -> SquaredEuclideanDistance]];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/11750129b3157729.png)
![Labeled[Grid[
Prepend[Transpose[{topPassagesEmbOnly}], {"Top-K Retrieved Passages by Embedding-Only"}], Frame -> All, Background -> {None, {LightGray}},
Alignment -> Left, Spacings -> {1, 2}], query, Top]](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/425662a8b5eac0b5.png)

![topN = 32;
{topNscores, topNPassages} = Transpose@
TakeSmallestBy[Transpose[{distanceScores, passages}], First, topN];](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/25235fc9781f4941.png)

![Labeled[Grid[
Prepend[Transpose[{topPassagesReranker}], {"Top-K Retrieved Passages by Two-Stage Document Retrieval"}], Frame -> All, Background -> {None, {LightGray}}, Alignment -> Left, Spacings -> {1, 2}], query, Top]](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/4d4badc326037f21.png)
![totalTimes = {{"Method", "Time (seconds)"}, {"Embedding-Only Retrieval", timeEmbOnly}, {"Reranker-Only Retrieval", timeRerankerOnly}, {"Two-Stage Retrieval", timeReRankerPipeline}};
Grid[totalTimes, Frame -> All, Background -> {None, {LightGray}}, Alignment -> Left, Spacings -> {2, 1}]](https://www.wolframcloud.com/obj/resourcesystem/images/31b/31b1cda2-b56f-4eed-875e-8c3586fdfc7e/4ca64ef561affc2c.png)
